

7.3 代码解读
MP3一般是用于我们普通用户听歌,而WAV文件通常用于录音室录音和专业音频项目。
虽然WAV质量高,但是很多播放器都不兼容这个格式,所以有时候我们需要将WAV格式转成MP3格式;或者在某些工程实践中,一般语音信号处理或者语音识别、声纹识别中读取音频的格式为WAV,所以也存在将其他几种常见音频格式转换成WAV格式的需求。
本节通过如下两种方式检测音频文件MP3和WAV的文件内容属性,确定文件类型和质量属性,并实现音频文件的转换等。
·以二进制方式打开媒体文件,借助struct库,通过媒体文件结构来获取。
·通过使用pymediainfo或pydub第三方库来获取媒体文件信息。
下面我们结合代码示例,展开讲解这两种方式。
1.通过音频文件格式获取
以《阿炳-二泉映月.mp3》为例,该音频的文件结构解析如下,其中前10字节为标签头。通过UltraEdit编辑器打开音频文件,MP3音频文件头解析如图7-3所示,显示的是十六进制数据。其中,前3字节49 44 33表示ID3,第4字节03表示V2.3版本,ID3V2是可选的,所以有的音频文件就没有ID3V2。

图7-3 MP3音频文件头解析
通过代码,我们可以进一步印证MP3音频文件标签头。不同的媒体文件,其文件内结构是不一样的,从7.2.2节中可知,MP3文件中有一种类型ID3V1,这种文件后128位中保存了一些重要的信息内容。
我们以二进制方式打开一个媒体文件,然后将文件定位到指定的位置(例如MP3文件的后128位的开始位置),最后通过列表切片逐条获取其中的信息并进行解码操作(使用decode()函数将二进制流解码为相应的内容)。二进制方式打开MP3音频文件,并读取标签头,如代码清单7-1所示。
# -*- coding: utf-8 -*-
# @Time : 2022/6/21 9:50 下午
# @Project : videoUtil
# @File : mp3Demo.py
# @Author : hutong
# @Describe: 微信公众号:大话性能
# @Version: Python3.9.8
from collections import namedtuple
import struct
ID3V2TagHeader = namedtuple("ID3V2TagFrame",
["Header", "Ver", "Revision", "Flag", "Size"])
# 二进制方式打开MP3音频文件
with open ("阿炳-二泉映月.mp3", "rb") as fr_mp3:
data_mp3 = fr_mp3.read()
# 通过struck库进行字节解码,MP3文件的前10字节是ID3V2.3的标签头
values = struct.unpack("3s b b b 4s", data_mp3[:10])
mp3Header = ID3V2TagHeader(*values)
print(f'mp3 header: {mp3Header}')
代码清单7-1 mp3Demo
输出结果如下:
mp3 header: ID3V2TagFrame(Header=b'ID3', Ver=3, Revision=0, Flag=0, Size=b'\x00\x00\x005')
读取标签尾部,从前面的文件结构中可知,ID3V2标签头不一定存在,而ID3V1的标签尾部是一定存在的,所以通过标签尾部的检测,可以确认该音频文件是MP3格式,MP3音频文件的后128字节如图7-4所示。
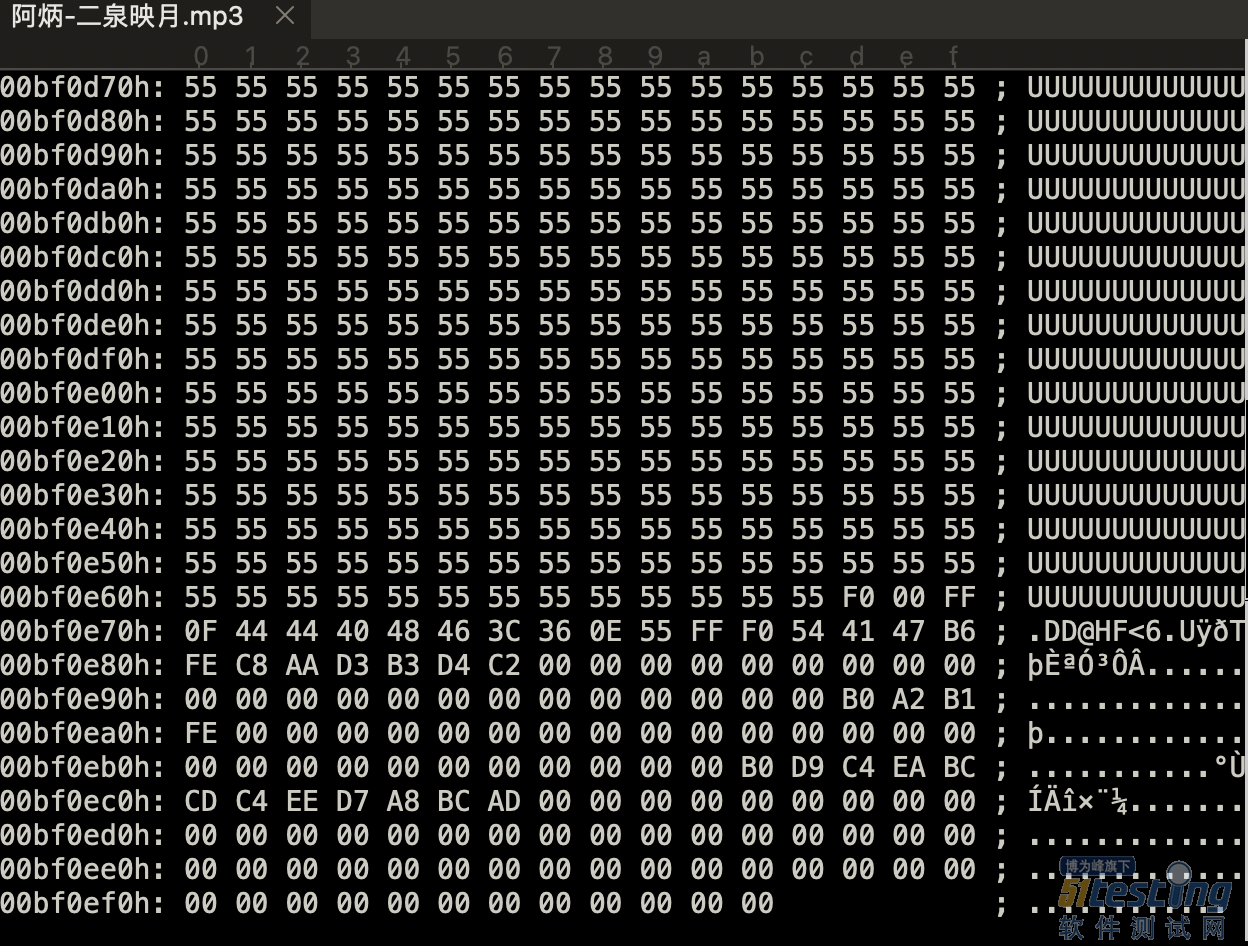
图7-4 MP3音频文件后128字节
先来看看ID3V1,因为它长度固定且位于文件尾部,所以读取一个MP3文件之后,获取它的后128字节就能得到ID3V1标签。每个部分的长度是固定的,如果长度不够用\0补齐。ID3V1标签的前3个字符一定是“TAG”,如代码清单7-2所示。
# -*- coding: utf-8 -*-
# @Time : 2022/6/21 10:50 下午
# @Project : videoUtil
# @File : mp3Util.py
# @Author : hutong
# @Describe: 微信公众号:大话性能
# @Version: Python3.9.8
from collections import namedtuple
import struct
# 封装MP3文件ID3V1的信息解码
import chardet
# 二进制方式打开音视频文件,并获取MP3音频文件的后128字节
def getFile(fileName):
with open(fileName, 'rb') as f:
# 2表示从文件尾开始偏移
f.seek(0, 2)
#print('f current tell() :{}'.format(f.tell()))
# tell()用于判断文件指针当前所处的位置
if (f.tell() < 128):
return None
# -128表示向文件头方向移动的字节数
f.seek(-128, 2)
data_bin = f.read()
print(f'读取mp3文件中ID3V1标签的字节长度为:{len(data_bin)} 具体内容为:{data_bin},')
return data_bin
# 字节转换为字符
def changeDecode(binStr):
# enType = chardet.detect(binStr)['encoding']
enType = 'GB2312'
# print('当前字节编码方式为:{}'.format(enType))
'''
if enType == None:
return binStr.decode('GB2312',errors = 'ignore')
else:
data_str = binStr.decode(enType, errors='ignore')
print('字节转换为字符后为:{}'.format(data_str))
'''
data_str = binStr.decode(enType, errors='ignore')
# print('字节转换为字符后为:{}'.format(data_str))
return data_str
# 按照MP3音频文件格式,针对ID3V1标签,逐个解析字节为字符
def getInfor(binInfo):
# 待移除的字节
rmbin = b"\x00"
info = {}
if binInfo[0:3] != b'TAG':
print('读取到的前3字节数据为:{}'.format(binInfo[0:3]))
return '获取失败,检查类型'
# print(binInfo[3:33])
info['title'] = binInfo[3:33].strip(rmbin)
# print('info title : {}'.format(info['title']))
if info['title']:
info['title'] = changeDecode(info['title'])
info['artist'] = binInfo[33:63].strip(rmbin)
if info['artist']:
info['artist'] = changeDecode(info['artist'])
info['album'] = binInfo[63:93].strip(rmbin)
if info['album']:
info['album'] = changeDecode(info['album'])
info['year'] = binInfo[93:97].strip(rmbin)
if not info['year']:
info['year'] = '未指定年份'
info['comment'] = binInfo[98:127].strip(rmbin)
if info['comment']:
info['comment'] = changeDecode(info['comment'])
info['genre'] = ord(binInfo[127:128])
return info
if __name__ == '__main__':
binData = getFile('阿炳-二泉映月.mp3')
changeDecode(binData)
print(f'解析出来的mp3音频文件ID3V1标签信息为:{getInfor(binData)}')
代码清单7-2 mp3Util
以音频文件《阿炳-二泉映月.mp3》为例,运行上述代码后输出结果如下:
读取mp3文件中ID3V1标签的字节长度为:128 具体内容为:b'TAG\xb6\xfe\xc8\xaa\xd3\xb3\xd4\xc2\
x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\xb0\
xa2\xb1\xfe\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\
x00\x00\x00\x00\x00\x00\xb0\xd9\xc4\xea\xbc\xcd\xc4\xee\xd7\xa8\xbc\xad\x00\x00\x00\x00\x00\
x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\
x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\
x00\x00'
,
解析出来的mp3音频文件ID3V1标签信息为:{'title': '二泉映月', 'artist': '阿炳', 'album': '百年纪念专辑', 'year': '未指定年份', 'comment': b'', 'genre': 0}
上面讲解的是MP3音频文件的检测,接下来是WAV音频文件。WAV文件的前44字节如图7-5所示。
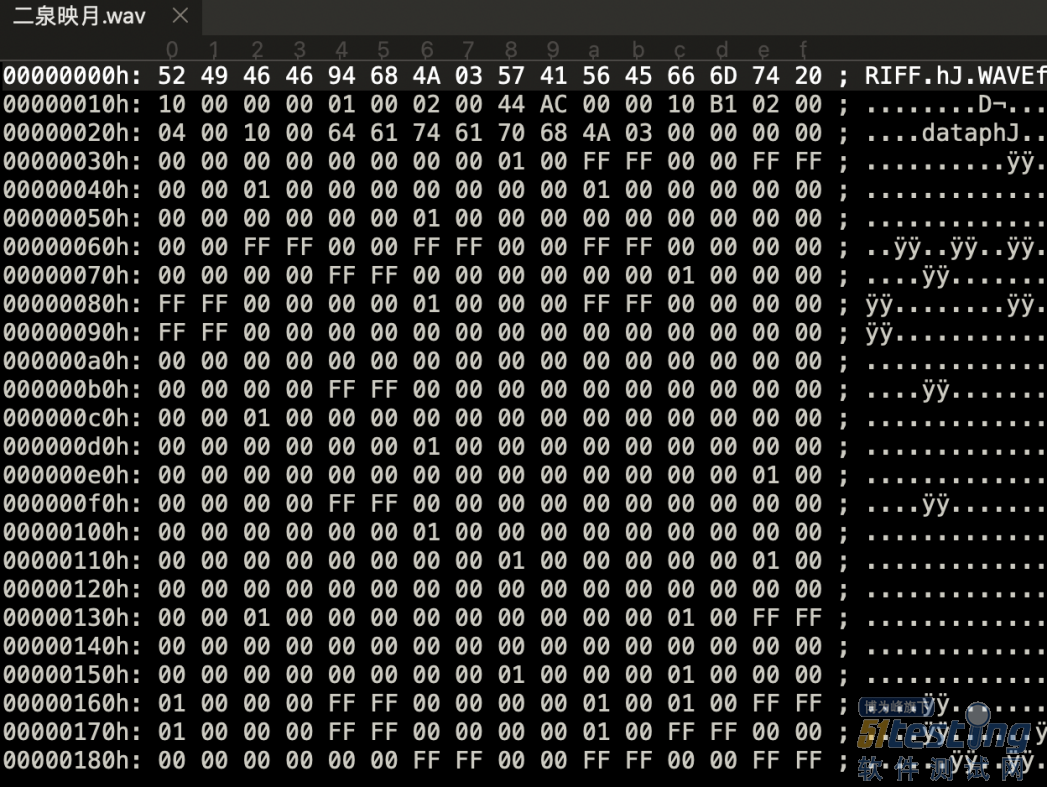
图7-5 WAV文件前44字节
采用struct库,原始地读取WAV文件,从而获取文件头内容,如代码清单7-3所示。
# -*- coding: utf-8 -*-
# @Time : 2022/6/22 09:40 下午
# @Project : videoUtil
# @File : wavDemo.py
# @Author : hutong
# @Describe: 微信公众号:大话性能
# @Version: Python3.9.8
from collections import namedtuple
import struct
# WAV格式
# WAV文件头包含文件前面的44字节数据
WavHeader = namedtuple("WavHeader",
["ChunkID", "ChunkSize", "Format", "Subchunk1ID", "Subchunk1Size",
"AudioFormat", "NumChannels", "SampleRate", "ByteRate", "BlockAlign",
"BitsPerSample", "Subchunk2ID", "Subchunk2Size"])
# 二进制的方式打开WAV音频文件
with open( "二泉映月.wav", "rb") as fr_wav:
data_wave = fr_wav.read()
# 通过struck进行字节解码
values = struct.unpack("4s I 4s 4s I H H I I H H 4s I", data_wave[:44])
wavHeader = WavHeader(*values)
print(f"wav header: {wavHeader}")
代码清单7-3 wavDemo
代码中以《二泉映月.wav》音频文件为例,运行上述代码后输出结果如下:
wav header: WavHeader(ChunkID=b'RIFF', ChunkSize=55208084, Format=b'WAVE', Subchunk1ID=
b'fmt ', Subchunk1Size=16, AudioFormat=1, NumChannels=2, SampleRate=44100, ByteRate=176400,
BlockAlign=4, BitsPerSample=16, Subchunk2ID=b'data', Subchunk2Size=55208048)
当然,除了这些,我们还可以获取帧信息、时长等一些内容,这里就不再演示了,主要方法是从二进制数据中提取有效信息,但解析的前提是我们要了解这些文件的二进制结构。
2.使用第三方库pymediainfo或pydub
使用Python提取视频中的音频仅需要安装一个体量很小的Python第三方库pymediainfo即可实现。使用pymediainfo获取媒体文件内容的代码相对简单,直接传入文件位置,然后使用MediaInfo.to_json()即可将信息以JSON格式返回,不过该库不能进行修改设置的操作。
借助pymediainfo库获取音频文件的属性信息如代码清单7-4所示,其中使用的pymediainfo版本号为5.1.0。
# -*- coding: utf-8 -*-
# @Time : 2022/6/22 09:48 下午
# @Project : videoUtil
# @File : mediaDemo.py
# @Author : hutong
# @Describe: 微信公众号:大话性能
# @Version: Python3.9.8
# 通过第三方库的方式获取或设置音频文件属性
# pymediainfo库,只能获取信息,无法重新设置更新
from pymediainfo import MediaInfo
media_info = MediaInfo.parse(r'阿炳-二泉映月.mp3')
data = media_info.to_json()
print(f'通过pymediainfo库,获取mp3音频信息为:{data}')
代码清单7-4 mediaDemo
运行上述代码,输出结果如下:
通过pymediainfo库,获取mp3音频信息为:{"tracks": [{"track_type": "General", "count": "331",
"count_of_stream_of_this_kind": "1", "kind_of_stream": "General", "other_kind_of_stream": ["General"], "stream_identifier": "0", "count_of_audio_streams": "1", "audio_format_list":
"MPEG Audio", "audio_format_withhint_list": "MPEG Audio", "audio_codecs": "MPEG Audio",
"complete_name": "\u963f\u70b3-\u4e8c\u6cc9\u6620\u6708.mp3", "file_name_extension": "\u963f\
u70b3-\u4e8c\u6cc9\u6620\u6708.mp3"
,
"file_name"
:
"\u963f\u70b3-\u4e8c\u6cc9\u6620\u6708"
,
"file_extension": "mp3", "format": "MPEG Audio", "other_format": ["MPEG Audio"], "format_
extensions_usually_used"
:
"m1a mpa mpa1 mp1 m2a mpa2 mp2 mp3"
,
"commercial_name"
:
"MPEG
Audio"
,
"internet_media_type"
:
"audio/mpeg"
,
"file_size"
: 12521212,
"other_file_size"
:
["11.9 MiB", "12 MiB", "12 MiB", "11.9 MiB", "11.94 MiB"], "duration": 312999, "other_duration":
["5 min 12 s", "5 min 12 s 999 ms", "5 min 12 s", "00:05:12.999", "00:05:12.999"], "overall_bit_rate_mode": "CBR", "other_overall_bit_rate_mode": ["Constant"], "overall_bit_rate":
320000, "other_overall_bit_rate": ["320 kb/s"], "stream_size": 201, "other_stream_size":
["201 Bytes (0%)", "201 Bytes", "201 Bytes", "201 Bytes", "201.0 Bytes", "201 Bytes (0%)"],
"proportion_of_this_stream": "0.00002", "title": "\u4e8c\u6cc9\u6620\u6708", "album": "\
u767e\u5e74\u7eaa\u5ff5\u4e13\u8f91"
,
"track_name"
:
"\u4e8c\u6cc9\u6620\u6708"
,
"performer"
:
"\u963f\u70b3", "file_last_modification_date": "UTC 2023-02-17 05:03:15", "file_last_modification_date__local": "2023-02-17 13:03:15", "writing_library": "LAME3.99r", "other_writing_library":
["LAME3.99r"]}, {"track_type": "Audio", "count": "280", "count_of_stream_of_this_kind":
"1", "kind_of_stream": "Audio", "other_kind_of_stream": ["Audio"], "stream_identifier":
"0", "format": "MPEG Audio", "other_format": ["MPEG Audio"], "commercial_name": "MPEG Audio",
"format_version": "Version 1", "format_profile": "Layer 3", "format_settings": "Joint stereo /
MS Stereo"
,
"mode"
:
"Joint stereo"
,
"mode_extension"
:
"MS Stereo"
,
"internet_media_type"
:
"audio/mpeg", "duration": 312999, "other_duration": ["5 min 12 s", "5 min 12 s 999 ms",
"5 min 12 s", "00:05:12.999", "00:05:15:12", "00:05:12.999 (00:05:15:12)"], "bit_rate_mode":
"CBR", "other_bit_rate_mode": ["Constant"], "bit_rate": 320000, "other_bit_rate": ["320 kb/s"],
"channel_s": 2, "other_channel_s": ["2 channels"], "samples_per_frame": "1152", "sampling_rate": 44100, "other_sampling_rate": ["44.1 kHz"], "samples_count": "13803264", "frame_rate":
"38.281", "other_frame_rate": ["38.281 FPS (1152 SPF)"], "frame_count": "11982", "compression_mode": "Lossy", "other_compression_mode": ["Lossy"], "stream_size": 12519967, "other_stream_size": ["11.9 MiB (100%)", "12 MiB", "12 MiB", "11.9 MiB", "11.94 MiB", "11.9 MiB (100%)"], "proportion_of_this_stream": "0.99990", "writing_library": "LAME3.99r", "other_writing_library": ["LAME3.99r"], "encoding_settings": "-m j -V 4 -q 3 -lowpass 20.5"}]}
为了设置音频属性和实现音频格式之间的转化,下面采用Python第三方库pydub,此处pydub版本号为0.25.1,FFmpeg版本号为1.4。利用pydub库,除了可以获取相关音频属性,还可以进行修改和重命名等操作,如代码清单7-5所示。
# -*- coding: utf-8 -*-
# @Time : 2022/6/22 09:49 下午
# @Project : videoUtil
# @File : mediaDemo2.py
# @Author : hutong
# @Describe: 微信公众号:大话性能
# @Version: Python3.9.8
# pydub库,除了可以获取信息,还支持设置、保存
import pydub
song = pydub.AudioSegment.from_mp3("阿炳-二泉映月.mp3")
# 返回一个AudioSegment对象,它就是音频读取之后的结果,通过该对象我们可以对音频进行各种操作
print(f'通过pydub库,读取音频文件后返回值为:{song}')
# 获取属性
# 声道数,1表示单声道,2表示双声道
print(f'通过pydub库,获取的声道数为:{song.channels}') # 2
# 采样宽度乘以8就是采样位数
print(f'通过pydub库,获取的采样位数为:{song.sample_width * 8}') # 16
# 采样频率,采样频率等于帧速率
print(f'通过pydub库,获取的采样频率为:{song.frame_rate}') # 44 100
# 时长(单位为秒)
print(f'通过pydub库,获取的音频时长为:{song.duration_seconds}') # 258.97600907029477
# 设置属性
# 我们可以更改设置采样频率
'''
print('原来的采样频率:{}'.format(song.frame_rate)) # 44 100
# 更改采样频率,一般都是44 100,我们可以修改为其他值
# 注意,并不是任意值都可以,只能是8000、12 000、16 000、24 000、32 000、44 100和48 000之一
# 如果不是这些值当中的一个,那么会从中选择与设置的值最接近的一个
# 例如,我们设置18 000,那么会自动变成16 000
song.set_frame_rate(16000).export("newSong.mp3", "mp3",bitrate="320k")
print('更改后的采样频率:{}'.format(pydub.AudioSegment.from_mp3("newSong.mp3").frame_rate))
# 16 000
'''
# 保存文件
# 指定文件名和保存的类型即可,注意,第二个参数表示保存的音频的类型,如果不指定则默认为MP3
'''
song.export("二泉映月.wav", "wav",tags=
{"title":"二泉映月",
"artist": "阿炳",
"comments": "soul singer"})
# 读取之后查看前4字节,发现是b"RIFF",证明确实是WAV格式
data = open("二泉映月.wav", "rb").read(4)
import struct
header = struct.unpack("4s", data)[0]
print(header) # b'RIFF',证明是WAV格式
'''
代码清单7-5 mediaDemo2
运行上述代码,输出结果如下:
通过pydub库,读取音频文件后返回值为:<pydub.audio_segment.AudioSegment object at 0x7fa3102200d0>
通过pydub库,获取的声道数为:2
通过pydub库,获取的采样位数为:16
通过pydub库,获取的采样频率为:44100
通过pydub库,获取的音频时长为:312.97079365079367
注意
运行中若报错“FileNotFoundError: [Errno 2] No such file or directory: 'ffprobe'”,原因是运行代码的机器上没有安装ffprobe和ffmpeg命令。
若使用的是macOS,可以通过如下方法安装上述工具。
(1)前往FFmpeg官网,下载适用于不同平台的软件版本。例如,选择适用于macOS的5.0.1版本的FFmpeg的静态编译包进行下载。下载的是zip压缩包,需要解压出来。
(2)配置全局环境变量,将解压出来的FFmpeg工具移动到/usr/local/bin/目录下。
(3)进入/usr/local/bin/目录,执行chmod 777 ffmpeg即可修改FFmpeg的权限。
上文中,我们讲解了如何通过原始二进制文件和第三方库的两种方式进行音频文件检测,以及从二进制文件中读取信息。对于不同格式的媒体文件,其二进制结构存在很大的差异,此类操作的前提是知道这种类型的文件二进制组织结构。但是,使用二进制方式打开的文件,在进行切片索引时,如果传入的位置参数和源媒体文件不一致,则获取到的数据信息会产生乱码,这是这种方式很明显的一个缺陷。不过这种方式能让我们深入了解各类音视频文件的结构。
使用第三方库pymediainfo获取的媒体文件的信息相对来说更详细,而且获取到的JSON数据也很容易提取有效信息,最重要的一点是它的速度比二进制文件方式更快。以1GB以上的视频文件为例,使用第三方库方式的程序性能比二进制文件方式有成倍的提升。因此,在实际使用时,建议大家使用第三方库来解决这一问题。
第三方的音视频库
MoviePy是一个用于视频编辑的Python库,可用于进行视频的基本操作(如剪切、拼接、标题插入)、视频合成、视频处理、创建高级效果等。
OpenCV是最常用的图像和视频识别库,其出色的处理能力使其在计算机产业和学术研究中都广泛使用。
FFmpeg有非常强大的功能包括视频采集、视频截取、视频格式转换、视频分辨率转换、视频合并、视频提取、音频提取、图片提取、视频水印处理等。FFmpeg是命令行工具,可以通过subprocess的调用来使用。
7.4 本章小结
通过本章的学习,相信大家了解了基础的音频概念和数据文件结构,尤其是MP3和WAV的音频文件构成,并学会通过两种方式操作音视频,即采用struct库进行音频文件的二进制方式的读取和解析,以及采用第三方库pymediainfo和pydub实现更加便捷灵活的处理。我们结合实际代码来演示讲解这两种方式,供大家学习和借鉴。
版权声明:51Testing软件测试网获得作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责












