

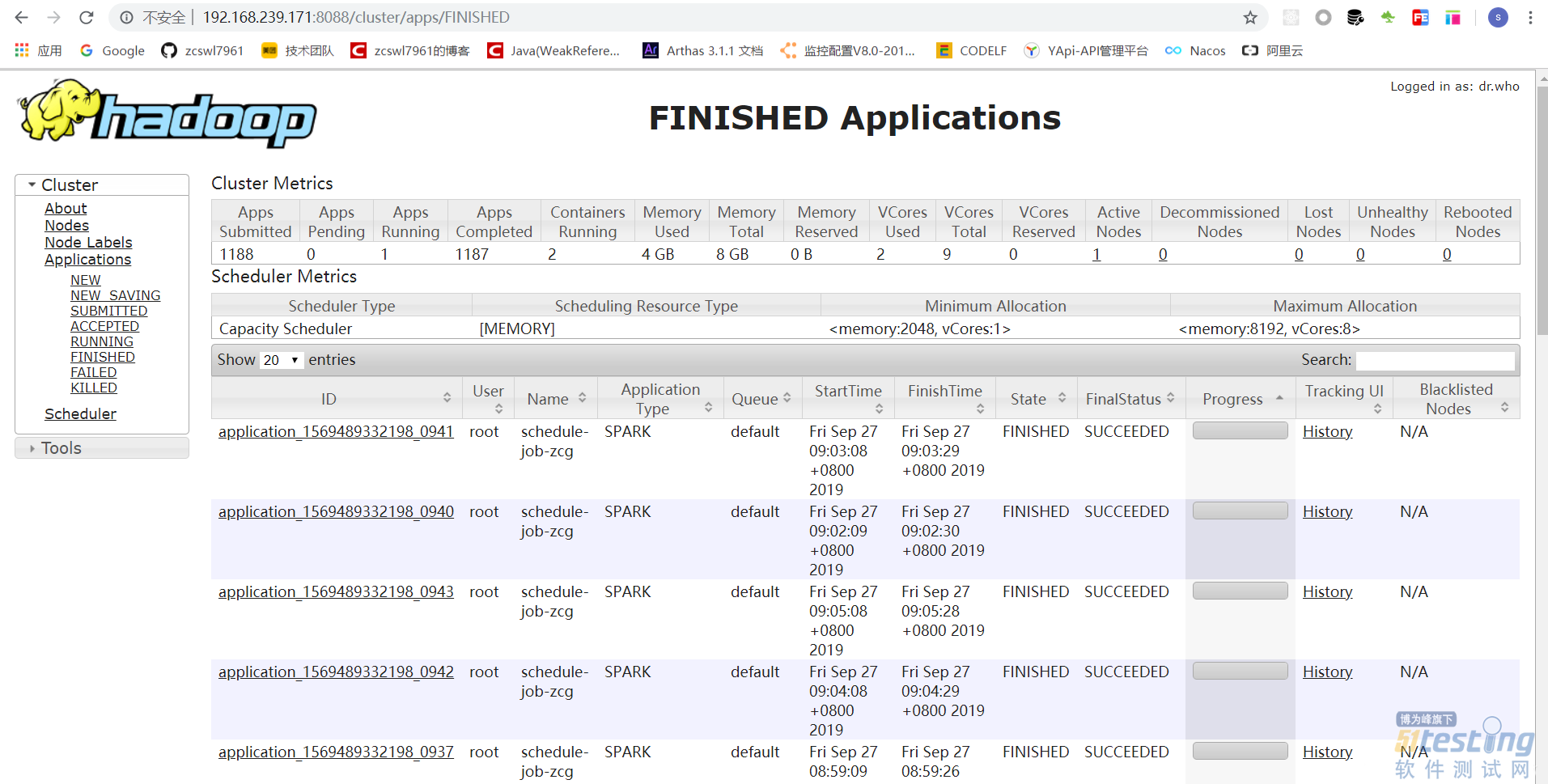
2,livy任务提交spark
livy接收到service提交的任务之后,提交到spark,spark接受的到任务之后,进行执行,首先是获取hadoop中配置的fileName:hdfs://localhost:8020/griffin/griffin-measure.jar,通过获取对应的className进行执行任务调度。
3,measure引擎计算
首先measuer计算是依赖于measuer.jar ,同时spark通过访问hadoop中的上传的measuer.jar进行执行,这个配置是在griffin源码中的sparkProperties.json的配置信息中。
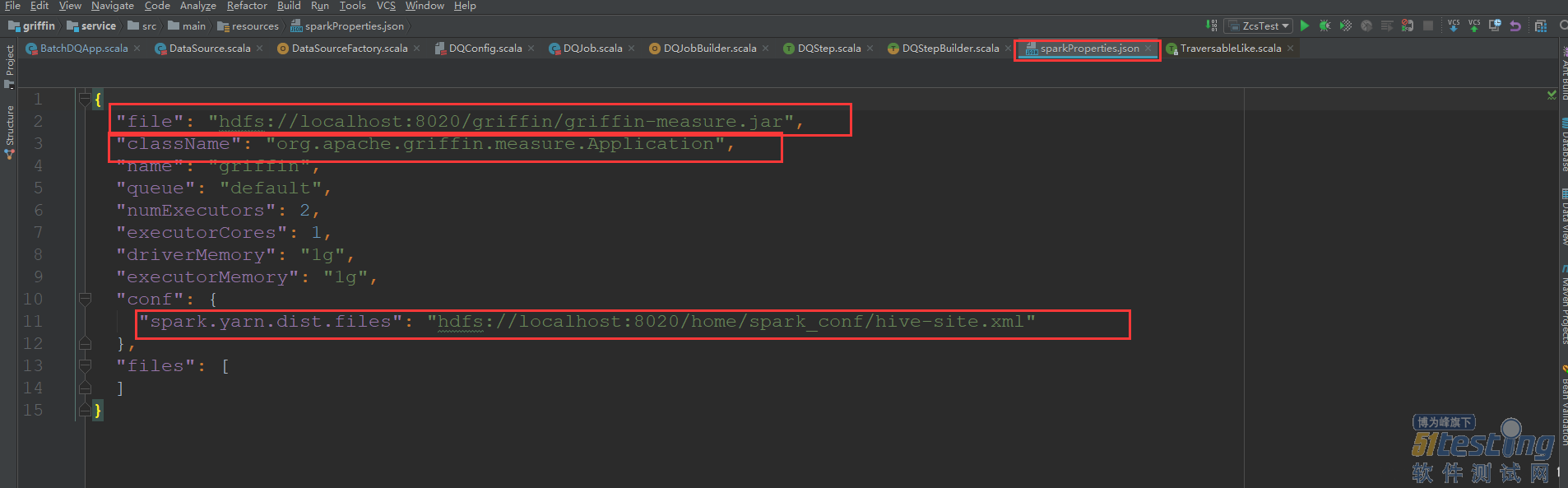
在去讲解源码之前,首先大致介绍一下Spark和Hadoop
3.1 Hadoop
首先,Hadoop是为了解决大数据存储和大数据分析的一套开源的分布式基础架构,
Hadoop有两大核心:HDFS和MapReducer
· HDFS(Hadoop Distributed File
System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。
· MapReduce 为分布式计算框架,包含map(映射)和 reduce(归约)过程,负责在 HDFS 上进行计算。
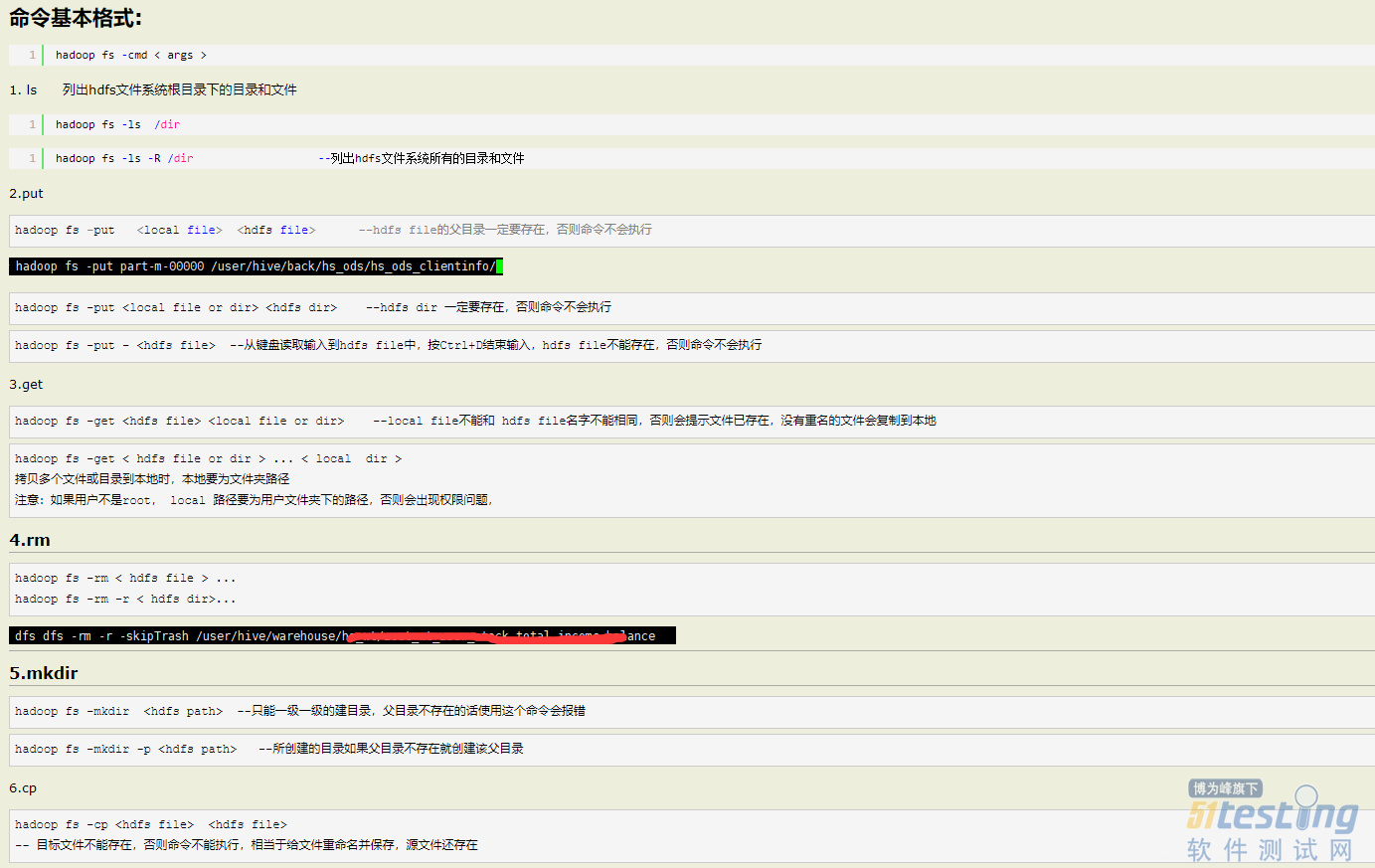
HDFS 就像一个传统的分级文件系统,可以进行创建、删除、移动或重命名文件或文件夹等操作,与 Linux 文件系统类似。
基础的文件操作命令:
MapReduce:MapReduce 是 Google 提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。概念“Map(映射)”和“Reduce(归纳)”以及它们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
当前的软件实现是指定一个 Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的 Reduce(归纳)函数,用来保证所有映射的键值对中的每一个共享相同的键组。

3.2 Spark
Spark是用于大规模数据处理的统一分析引擎。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
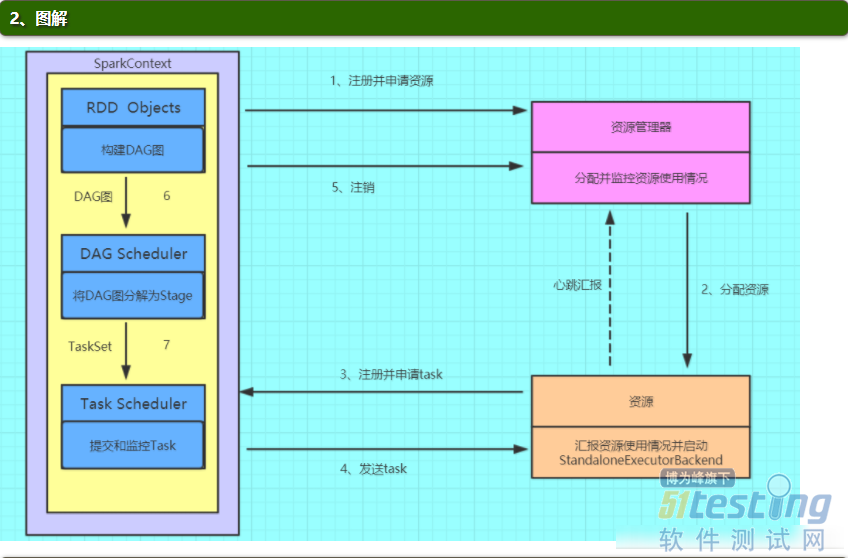
Spark的基本运行流程:
(1)构建Spark
Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
(2)资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
(3)SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task
Scheduler。Executor向SparkContext申请Task
(4)Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
(5)Task在Executor上运行,运行完毕释放所有资源。
3.2 measuer源码
进入到meauser模块中,执行Application.scala类,首先是获取启动类传递的两个参数args
val envParamFile = args(0)
val dqParamFile = args(1)
envParamFile:表示对应环境配置信息,包括对应的spark的日志级别,数据源的输出目的地,
{
//对应的spark的日志级别
"spark":{
"log.level":"WARN"
},
//数据源的输出目的地
"sinks":[
{
"type":"CONSOLE",
"config":{
"max.log.lines":10
}
},
{
"type":"HDFS",
"config":{
"path":"hdfs://localhost:8020/griffin/persist",
"max.persist.lines":10000,
"max.lines.per.file":10000
}
},
{
"type":"ELASTICSEARCH",
"config":{
"method":"post",
"api":"http://localhost:9200/griffin/accuracy",
"connection.timeout":"1m",
"retry":10
}
}
],
"griffin.checkpoint":[
]
}
dbParamFile:表示对应的执行任务的数据配置,包括对应的数据源的配置,计算规则信息
{
"measure.type":"griffin",
"id":3355,
"name":"schedule-job-zcg",
"owner":"test",
"description":"test",
"deleted":false,
"timestamp":1569492180000,
"dq.type":"ACCURACY",
"sinks":[
"ELASTICSEARCH",
"HDFS"
],
"process.type":"BATCH",
"data.sources":[
{
"id":3358,
"name":"source",
"connectors":[
{
"id":3359,
"name":"source1569548839003",
"type":"HIVE",
"version":"1.2",
"predicates":[
],
"data.unit":"1day",
"data.time.zone":"",
"config":{
"database":"griffin_demo",
"table.name":"demo_src",
"where":"dt='20190927' AND hour = '09'"
}
}
],
"baseline":false
},
{
"id":3360,
"name":"target",
"connectors":[
{
"id":3361,
"name":"target1569548846717",
"type":"HIVE",
"version":"1.2",
"predicates":[
],
"data.unit":"1day",
"data.time.zone":"",
"config":{
"database":"griffin_demo",
"table.name":"demo_tgt",
"where":"dt='20190927' AND hour = '09'"
}
}
],
"baseline":false
}
],
"evaluate.rule":{
"id":3356,
"rules":[
{
"id":3357,
"rule":"source.id=target.id",
"dsl.type":"griffin-dsl",
"dq.type":"ACCURACY",
"out.dataframe.name":"accuracy"
}
]
}
}
Application.scala核心代码:
object Application extends Loggable {
def main(args: Array[String]): Unit = {
// info(args.toString)
val args = new Array[String](2)
// 测试代码
args(0) = "{\n \"spark\":{\n \"log.level\":\"WARN\",\n \"config\":{\n \"spark" +
".master\":\"local[*]\"\n }\n },\n \"sinks\":[\n {\n \"type\":\"CONSOLE\",\n " +
" \"config\":{\n \"max.log.lines\":10\n }\n },\n {\n " +
"\"type\":\"HDFS\",\n \"config\":{\n " +
"\"path\":\"hdfs://localhost:8020/griffin/batch/persist\",\n \"max.persist" +
".lines\":10000,\n \"max.lines.per.file\":10000\n }\n },\n {\n " +
"\"type\":\"ELASTICSEARCH\",\n \"config\":{\n \"method\":\"post\",\n " +
"\"api\":\"http://192.168.239.171:9200/griffin/accuracy\",\n \"connection" +
".timeout\":\"1m\",\n \"retry\":10\n }\n }\n ],\n \"griffin" +
".checkpoint\":[\n\n ]\n}";
args(1) = "{\n \"name\":\"accu_batch\",\n \"process.type\":\"batch\",\n \"data" +
".sources\":[\n {\n \"name\":\"source\",\n \"baseline\":true,\n " +
"\"connectors\":[\n {\n \"type\":\"avro\",\n \"version\":\"1.7\"," +
"\n \"config\":{\n \"file.name\":\"src/test/resources/users_info_src" +
".avro\"\n }\n }\n ]\n },\n {\n \"name\":\"target\",\n " +
" \"connectors\":[\n {\n \"type\":\"avro\",\n \"version\":\"1.7\"," +
"\n \"config\":{\n \"file.name\":\"src/test/resources/users_info_target" +
".avro\"\n }\n }\n ]\n }\n ],\n \"evaluate.rule\":{\n " +
"\"rules\":[\n {\n \"dsl.type\":\"griffin-dsl\",\n \"dq" +
".type\":\"accuracy\",\n \"out.dataframe.name\":\"accu\",\n \"rule\":\"source" +
".user_id = target.user_id AND upper(source.first_name) = upper(target.first_name) AND " +
"source.last_name = target.last_name AND source.address = target.address AND source.email =" +
" target.email AND source.phone = target.phone AND source.post_code = target.post_code\"\n " +
" }\n ]\n },\n \"sinks\":[\n \"CONSOLE\",\n \"ELASTICSEARCH\"\n ]\n}";
if (args.length < 2) {
error("Usage: class <env-param> <dq-param>")
sys.exit(-1)
}
val envParamFile = args(0)
val dqParamFile = args(1)
info(envParamFile)
info(dqParamFile)
// read param files
// args(0)信息,将其转换成对应的EnvConfig对象,
val envParam = readParamFile[EnvConfig](envParamFile) match {
case Success(p) => p
case Failure(ex) =>
error(ex.getMessage, ex)
sys.exit(-2)
}
// args(2)信息,将其转换成对应的DQConfig配置信息
val dqParam = readParamFile[DQConfig](dqParamFile) match {
case Success(p) => p
case Failure(ex) =>
error(ex.getMessage, ex)
sys.exit(-2)
}
val allParam: GriffinConfig = GriffinConfig(envParam, dqParam)
// choose process
// 选择对应的进程对象进行执行,这里面的就是BatchDQApp
val procType = ProcessType(allParam.getDqConfig.getProcType)
val dqApp: DQApp = procType match {
case BatchProcessType => BatchDQApp(allParam)
case StreamingProcessType => StreamingDQApp(allParam)
case _ =>
error(s"${procType} is unsupported process type!")
sys.exit(-4)
}
startup
// (1)初始化griffin定时任务执行环境
// 具体代码见下个代码块,主要逻辑是创建sparkSession和注册griffin自定义的spark udf
// dq app init
dqApp.init match {
case Success(_) =>
info("process init success")
case Failure(ex) =>
error(s"process init error: ${ex.getMessage}", ex)
shutdown
sys.exit(-5)
}
// dq app run
// (2)执行对应的定时任务作业,这里的处理就是批处理任务,
val success = dqApp.run match {
case Success(result) =>
info("process run result: " + (if (result) "success" else "failed"))
result
case Failure(ex) =>
error(s"process run error: ${ex.getMessage}", ex)
if (dqApp.retryable) {
throw ex
} else {
shutdown
sys.exit(-5)
}
}
// dq app end
dqApp.close match {
case Success(_) =>
info("process end success")
case Failure(ex) =>
error(s"process end error: ${ex.getMessage}", ex)
shutdown
sys.exit(-5)
}
shutdown
if (!success) {
sys.exit(-5)
}
}
private def readParamFile[T <: Param](file: String)(implicit m : ClassTag[T]): Try[T] = {
val paramReader = ParamReaderFactory.getParamReader(file)
paramReader.readConfig[T]
}
private def startup(): Unit = {
}
private def shutdown(): Unit = {
}
}
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












