

第2章 关键识别技术及常见控件的使用
在写界面的功能自动化测试脚本时,90%的时间花在和界面中的各种对象交互上,了解界面中的对象后,我们就可以在测试脚本中使用指令来测试这些对象。
在《精通QTP—自动化测试技术领航》一书中,我们用了非常大的篇幅来帮助读者理解和掌握对象识别的原理和技术,在本书中,这一部分仍然是重中之重。
2.1 自动化测试的核心——对象识别
2.1.1 如何快速抓取页面上的元素属性
在第 1 章中有一个技术点,我们只是对其介绍了一下,没有加以解释,它就是现在要讲的—如何获取页面中的元素属性。本节会讲解如何快速查找页面中的对象属性的内容。仍然以飞机订票网站为例,浏览器使用Chrome,具体实现步骤如下。
(1)启动Chrome,打开飞机订票页面。
(2)将光标定位到UserName文本框,右击弹出上下文菜单,如图2.1所示。
(3)选择 Inspect 命令后,Chrome 会自动定位到此对象所在的元素位置,如图 2.2所示。
当选择Inspect命令后,Chrome浏览器会自动打开开发者工具窗口。窗口顶部其实有很多标签页,当前选中的标签页为Elements,在这个标签页下会显示整个页面所包含的所有元素。用户单击某个对象元素后,Chrome就会自动定位到这个对象所在的代码行。下面就是Chrome定位对象的代码。
| <input type="text" name="UserName" size="10"> |
这样我们就成功获取到了对象的类型“text”、对象的名称“UserName”,以及该对象的尺寸“10”。同样地,我们可以很轻松地定位到其他任何想要寻找的对象。问题来了,既然已经获取到了对象的XPath,我们如何确保XPath是正确的呢?总不能每次运行测试脚本,发现XPath出错以后改一次,接着又出错,继续改。如果测试脚本很长,这样调试代码的过程将会非常痛苦,所以需要在运行脚本之前确保XPath是正确的。Chrome浏览器自带了一个功能,可以帮助用户快速验证XPath是否正确。具体方法如下。
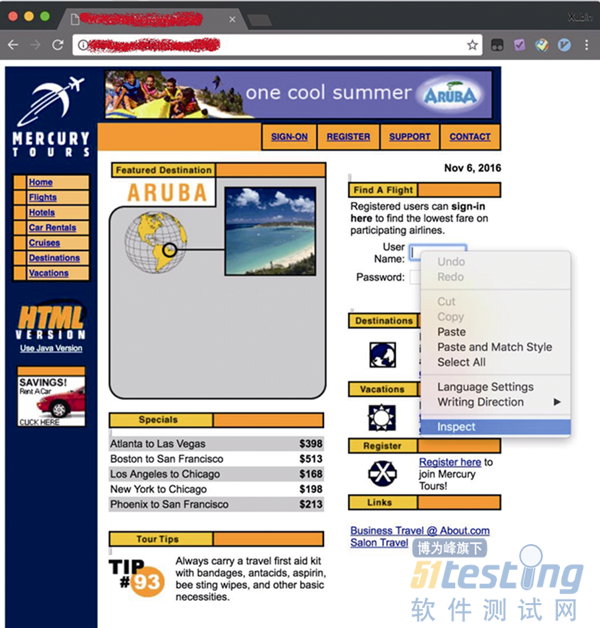
图2.1 右击UserName文本框弹出的上下文菜单

图2.2 自动定位到对象所在的元素位置
方法一:在Elements标签页中按Ctrl + F组合键进行查找。
在Elements标签页中按Ctrl + F组合键,你会发现在页面底部新增了一个文本框,并且显示“Find by string,selector,or XPath”(见图2.3),意思就是这个文本框支持直接用字符串搜索验证、XPath搜索验证及CSS选择器搜索验证。

图2.3 搜索验证文本框
输入正确的XPath后,Chrome会自动定位到对应的元素。
当输入完XPath并按Enter键后,如果看到图2.4所示的灰色匹配条,说明XPath验证通过了;反之,如果页面没有任何动作,也没有看到匹配条,表明写入的XPath在页面中没有找到任何成功匹配的元素。
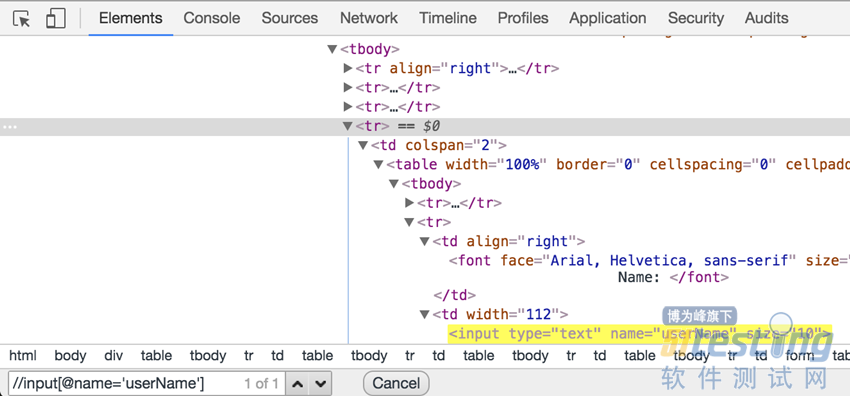
图2.4 验证XPath是否正确
方法二:在Console标签页中输入$x("<写入XPath>")。
首先,需要切换到Console标签页。然后,输入一个美元符加上一个x。接着,写入XPath并按Enter键,如图2.5所示。
如果验证通过,Console就会返回对应的元素。如图2.5所示,我们可以看到Console返回了一个input元素。如果展开input,并把鼠标指针放到其上面,则页面中对应的元素会自动高亮显示,从而二次检查对象是否验证通过。图2.6即为鼠标指针悬浮在返回的input文本上时,对象高亮显示的效果。
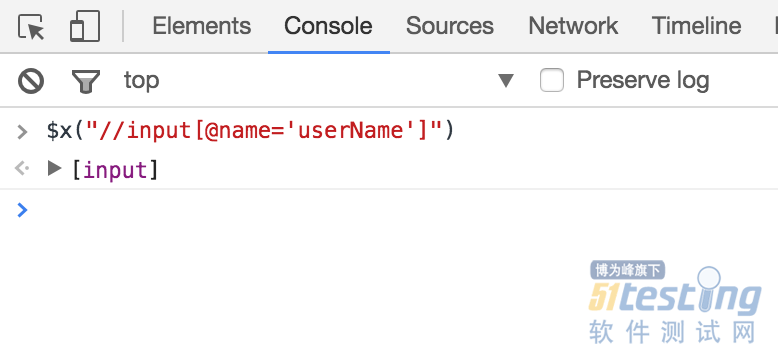
图2.5 在Console标签页中验证XPath

图2.6 对象高亮显示的效果
假设输入的XPath不正确,那么Console就会返回空,代表在当前页面中找不到对应的元素,如图2.7所示。

图2.7 在Console中未找到对应元素
这一节的内容相对基础,但是对于新手来说,其重要性远胜过后面的章节,它是对象识别的基础。如果读者对这一节的内容还不是很熟练,需要反复练习,然后继续后续章节的学习,因为后续的章节不再讲解有关XPath验证的内容了,有关XPath的表达式需要读者自行验证。当然,如果有兴趣,读者可以通过网络平台的一些教程深入学习和理解一下XPath,这对后续学习会有很大帮助。
2.1.2 学会如何高效地使用XPath定位对象
这一节介绍如何利用XPath查找定位器。不过,在此之前,先简单介绍一下什么是定位器。一些读者可能会对这个词比较陌生,举一个简单的例子,当我们需要自动化测试一个登录操作时,先要确定哪些对象是需要自动化测试的。通常的做法是,先通过各种途径获取到对应的UserName文本框、Password文本框及Login按钮这3个测试对象,当确保已经能够成功识别到这些对象后,即可“随意”操作这些对象。而定位器就是查找及定位这些测试对象的途径(或者方式),并以表达式的方式呈现出来。如果需要查找id为UserName的元素,那么id=UserName即为一种以id方式查找的定位器,若使用XPath来查找,那么定位器即为XPath=XXX。通俗地讲,定位器可以告诉Selenium哪些测试对象是需要自动化测试的。
相信读者已经了解了什么是定位器,下面就来讲解如何高效地使用XPath定位测试对象,注意此处的“高效”两字。一些读者刚开始学习XPath时,非常喜欢使用浏览器自带的Copy XPath。的确,Copy XPath用起来很方便,浏览器自动生成XPath,不用自己一个个按照HTML的源码手动编写这些XPath,但是很多情况下,浏览器自带的Copy XPath的定位结果是一堆索引,就像下面这样。
| /html/body/div/table/tbody/tr/td[2]/table/tbody/tr[4]/td/table/tbody/tr/td[2]/table/tbody/tr[2]/td[3]/form/table/tbody/tr[4]/td/table/tbody/tr[2]/td[2]/input |
虽然这样的XPath可以成功识别对象,也可以在识别对象后操作对象,但是假设开发人员变更了表达式中的某些索引,之前获取的XPath是不是就失效了?有些读者会说没关系,若失效了,就重新通过Copy XPath获取一个最新的XPath。但是,这还只是一个XPath,当脚本数量很庞大时,XPath定位器的数量也随之不断增加,在这样的情况下,如果仍然坚持每次都重新使用Copy XPath的方式几十遍或几百遍地更新对象库,那真是太累了。在这种情况下,其实完全可以将事情简单化,找能够唯一识别的关键字,如id,因为开发人员很少会去更改id这个属性,它是一个控件的唯一标识。也可以选择控件的name属性来作为标识,只要name不变,即使控件的位置发生改变,也可以找到指定的控件。有些时候,如果某一个属性值的部分内容是变化的,则可以使用contains方式来识别对象。当然,一些控件既没有id也没有name,这类情况只能考虑相邻位置定位(后续的内容会讲到),或者使用索引,但是使用索引对于后期的脚本维护不是一个很好的选择,最好的方法是让开发人员加上对应的id或者通过修改程序来使对象可以被唯一识别。
下面看几个XPath的实例。先来看一下简单的登录操作的HTML源代码。
<table> <tr> <td colspan="2"> <font size="2">Registered users can <b>sign-in here</b> to find the lowest fare on participating airlines. </font> </td> </tr> <tr> <td align="right"> <font size="2">User Name: </font> </td> <td width="112"> <input type="text" name="userName" size="10"> </td> </tr> <tr> <td align="right"> <font size="2">Password:</font> </td> <td width="112"> <input type="password" name="Password" size="10"> </td> </tr> <tr> <td align="right"> </td> <td width="112"> <div align="center"> <input type="image" name="login" value="Login" src="/images/XXX" width=" 58" height="17" alt="Sign-In" border="0"> </div> </td> </tr> <tr> <td colspan="2"><img src="/images/spacer.gif" width="1" height="2"></td> </tr> </table> |
以上这段HTML源码来自飞机订票网站首页的登录模块,其中稍做了修改。这段HTML代码中有一个table元素,并且这个table元素包含5行内容,但对于登录操作测试来说,我们需要的只是UserName文本框、Password文本框及Login按钮,所以我们把这3个对象单独取出来并分析。
<input type="text" name="UserName" size="10"> <input type="password" name="Password" size="10"> <input type="image" name="login" value="Login" src="/images/XXX" alt="Sign-In" border="0"> |
上面这段代码一共取出3个控件,第一个是UserName文本框,第二个是Password文本框,第三个是Login按钮。要使用XPath来定位这些对象是很简单的,基本上就是下面这个样子。
定位UserName文本框的XPath://input[@name='userName']。
定位Password文本框的XPath://input[@name='Password']。
定位Login按钮的XPath://input[@name='Login']。
作为最基本的XPath表达式,它们看上去还是非常简单的。这里的“//”表示相对路径,代表直接查找input标签。但是,有些时候程序中的对象不是固定的,例如,id可能会是一个动态的值,或者根本就没有id和name属性。下面列举了几个常见的问题。
1.查找的id或者name属性是动态的值
把以上UserName文本框的HTML代码修改成如下形式。
| <input type="text" name="UserName-9527" size="10"> |
相信有一定项目经验的读者一定遇到过这类控件,name为类似UserName-XXX这样的形式,其中XXX为一个动态生成的值。如果我们直接使用之前的方式来定位此对象,脚本在下次打开页面时会重新生成一个动态值,这样就无法识别到此对象了。
解决方法是包含匹配法—使用contains方法抓取不变的字符串。给出定位此对象的XPath—//input[contains(@name,'userName')]。
处理这种情况只需要加上contains方法。此方法的第一个参数为属性名,第二个参数为包含的关键字。这样写的好处就是,无论UserName之后的XXX怎么变动,都不会影响最终成功识别到这个对象。
有些时候,使用contains也会出现比较尴尬的情况。如果使用了contains后页面上存在两个同样关键字的对象,那么就要考虑重新选取关键字或者通过其他方式来解决。这个只能在遇到问题后具体原因具体分析。
2.查找既没有id也没有name但有参照物的对象
先分析下面的这段代码。
<td align="right"> UserName: </td> <td width="112"> <input type="text"/> </td> |
这里需要定位的对象为一个文本框。
| <input type="text"/> |
一定有读者会认为这非常简单,直接用//input[@type='text']就可以了。的确可以这样来定位这个对象,但是这样的XPath是非常不利于脚本维护的。此文本框没有id,没有name,只有一个type。也就是说,假设页面上有第二个text,那么对象肯定是会无法识别的。解决方法是使用参照物定位法。
其实如果在浏览器中显示以上代码,UserName文本框与此文本框其实是在同一行的。也就是说,此文本框就代表UserName文本框,因此我们要做的就是先想办法定位UserName这个关键字对象,随后再相对于UserName定位那个既没有id又没有name的文本框对象。
下面给出定位此对象的XPath。
| //td[text()='UserName:']/following-sibling::td/input |
首先,通过text()=UserName获取到第一个td节点。然后,你会看到following-sibling::td,它的意思是取得当前节点后面的td节点,以节点的标签名td结尾。最后,跟上/input即可轻松获取到那个既没有id又没有name的文本框。
实际上,除了following-sibling之外,还有一个具有类似功能的方法—preceding- sibling。两者的作用几乎是一样的,只是following-sibling向后搜索,而preceding-sibling正好相反,往前搜索。无论采用哪个方法,都别忘记加上两个冒号。
3.查找第一个或者最后一个元素
<div> <label>XXX</label> <label>YYY</label> <label>ZZZ</label> </div> |
当我们需要处理一些动态数据时,某些情况下会需要获取最新的一条数据或者最早生成的数据。假设在上面这段代码片中,label的内容都是动态的,而我们需要获取最新一条XXX的元素,应该怎么做呢?这个比较简单,只需要使用索引并将其设置为1即可。当然,很多时候我们也需要取得最后一条记录的数据。讲到这里,相信一些读者应该有些经验,作者也见过很多人是这样做的:首先通过//div/label这个XPath获取所有label对象,并返回label对象的个数,最后通过索引的方式来获取。这个方法其实很正确,但很烦琐,它需要通过两个步骤才能实现。
(1)写一个XPath获取所有对象并通过代码获取所有个数。
(2)写一个XPath,并把索引传入获取对象。
那么,有没有更好的方法呢?其实有一个更好的办法,只需要一步即可轻松实现,并且这个办法在XPath这一层就可以返回我们需要的对象。做法很简单,也不复杂,只需要使用XPath中的last()函数。last()函数会自动返回最后一个索引对应的元素,这样利用last()函数就可以直接获取最后一个元素,既稳定又简单,大大降低了代码量,减少了实现步骤。
解决方法是序列定位法—利用index或last()函数来定位。
下面给出第一个标签XXX的XPath。
| //div/lable[1] |
这行语句的意思是要获取的第一个元素的索引就从1开始,切记不是从0开始!
下面给出最后一个标签ZZZ的XPath的获取语句。
| //div/label[last()] |
直接把last()函数放到索引的位置,last()返回的就是一个最后位置的索引。
2.1.3 CSS选择器—另一种不得不学的定位方式
看到本节的标题,读者一定会问:既然学会了XPath而且XPath也挺好用,为什么要学习CSS选择器呢?因为作者希望读者能够在掌握了CSS选择器,对两者有一个整体认识后,再讨论它们的优缺点。
与XPath类似,CSS选择器其实也是一种查找界面上元素的方式。下面来看一下之前用XPath的实例现在用CSS选择器是如何实现的。
<input type="text" name="UserName" size="10"> <input type="password" name="Password" size="10"> <input type="image" name="Login" value="Login" src="/images/XXX" alt="Sign-In" border="0"> |
使用CSS选择器获取以上3个元素的方式如下。
定位UserName文本框的CSS:input[name=UserName]。
定位Password文本框的CSS:input[name=Password]。
定位Login按钮的CSS:input[name=Login]。
从以上3个CSS的定位器可以看到,两者还是有一定相似度的,但CSS选择器在可读性上比XPath表达式好很多,没有了双斜杠,没有了“@”符号,整体看上去语句非常简洁。再来看一下以下3个常见问题用CSS选择器如何处理,为了能让读者更清晰地了解两者的不同,此处我们列出与之前完全一样的HTML实例代码。
1.动态id问题的处理
实现语句如下。
| <input type="text" name="UserName-9527" size="10"> |
解决方法是子字符串匹配法—利用“*=”自动匹配子字符串。
给出定位此对象的CSS选择器。
| input[name*=UserName] |
“*=”是相当简洁的表述方式,推荐使用CSS选择器处理匹配字符串的方式。这样识别字符串既简单又快速,而使用XPath处理“包含”问题时,需要在语句中加入contains方法,加入各种括号、逗号、引号。
CSS选择器的字符串匹配方式一共有3种,除了使用最多的“*=”子字符串匹配之外,CSS选择器还支持前缀匹配与后缀匹配的识别方式,前缀匹配需要使用“^=”,后缀匹配需要使用“$=”。
前缀匹配:input[name^=<需要匹配的前缀部分>]。
后缀匹配:input[name$=<需要匹配的后缀部分>]。
2.参照定位法
我们需要定位<input type="text">这个文本框,实现语句如下。
<td align="right"> UserName: </td> <td width="112"> <input type="text"/> </td> |
解决方法:相对定位法—使用参照物定位法处理。
下面给出定位此对象的CSS选择器。
| td:contains('UserName') + td > input |
contains表示节点的文本内容包含了UserName字符串,如果用XPath来表示就是contains(text(),“UserName”);随后你会看到一个“+”,然后紧跟着td标签;在CSS选择器中,“+ tagname”表示位于当前节点之后的a标签;符号“>”代表其子节点。
那么这个语句的含义就是先查找节点文本为UserName的td标签,接着查找此标签紧挨着的td标签下的子元素input标签。其整体思路与XPath表达式获取的思路一致,但是CSS选择器的写法更简洁一些,特别是CSS中“+”这个功能,它比XPath中实现同样功能的following-sibling好记很多。
3.查找最先和最后定位法
实现语句如下。
<div> <label>XXX</label> <label>YYY</label> <label>ZZZ</label> </div> |
解决方法:最先和最后定位法—利用first-child或last-child函数来定位。
下面给出第一个标签XXX的CSS选择器。
| div > lable: nth-child(1) |
此处与XPath一样,可以通过索引的方式读取某个标签,但是作者感觉还是用XPath表达式中括号的可读性更高,也更容易识记。
下面给出最后一个标签ZZZ的CSS选择器。
| div > label:last-child |
与XPath一样,CSS选择器同样包含一个方法,可以用于直接获取最后一个元素,这个方法就是last-child方法。
CSS选择器除了用last-child获取最后一个元素外,还可以使用一个first-child方法,顾名思义,后一个方法用于获取第一个元素,其作用等价于nth-child(1),但是推荐用nth-child(1)这样的写法,感觉更直观。
版权声明:51Testing软件测试网获得人民邮电出版社和作者授权连载本书部分章节。
任何个人或单位未获得明确的书面许可,不得对本文内容复制、转载或进行镜像,否则将追究法律责任。












