

谈到数据产品,很多时候有一种误解,认为这些产品无法通过自动化来进行测试。 尽管流水线的某些部分由于其实验性和随机性而无法通过传统的测试方法进行测试,但大部分流水线可以。 除此之外,更加不可预测的算法可以通过专门的验证过程。
让我们来看看传统的测试方法,以及我们如何将这些方法应用到我们的数据/ ML 流水线中。
测试金字塔
标准简化的测试金字塔如下所示:
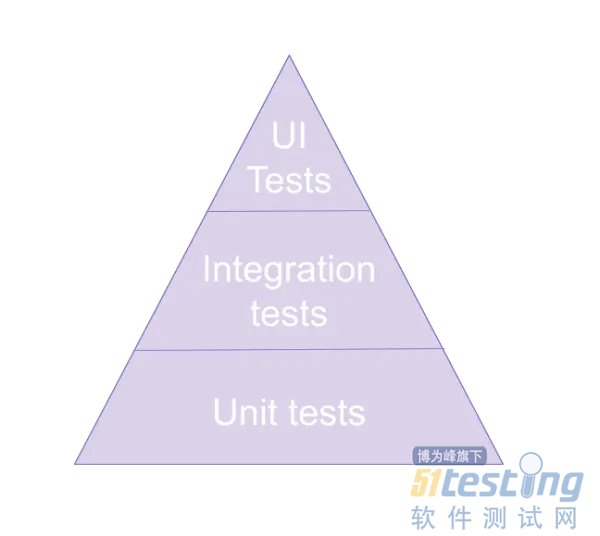
这个金字塔表示您将为应用程序编写的测试类型。 我们从大量的单元测试开始,这些单元测试独立于其他功能来测试单个功能。 然后我们编写集成测试来检查将我们隔离的组件组合在一起是否按预期工作。 最后,我们编写 UI 或验收测试,从用户的角度检查应用程序是否按预期工作。
在数据产品方面,金字塔并没有太大的不同。 我们有或多或少相同的等级。
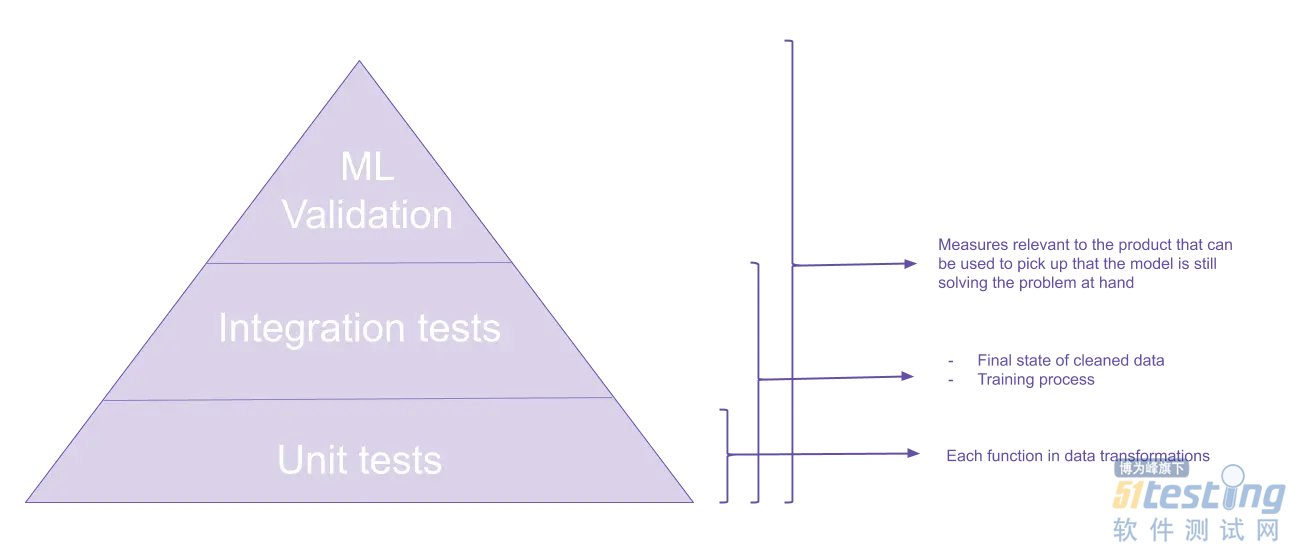
注意:该产品仍将进行UI测试,但本文主要关注与数据流水线最相关的测试。
在一些科幻作家的帮助下,让我们更仔细地看一下,在机器学习的背景下,每一项都意味着什么。
单元测试
数据流水线中的大部分代码都包含数据清理过程。 用于进行数据清洗的每个功能都有一个明确的目标。 例如,假设我们为输出的模型选择的特征之一是前一天和当天之间的值的变化。 我们的代码可能看起来像这样:
def add_difference(asimov_dataset):
asimov_dataset['total_naughty_robots_previous_day'] =
asimov_dataset['total_naughty_robots'].shift(1)
asimov_dataset['change_in_naughty_robots'] =
abs(asimov_dataset['total_naughty_robots_previous_day'] -
asimov_dataset['total_naughty_robots'])
return asimov_dataset[['total_naughty_robots', 'change_in_naughty_robots',
'robot_takeover_type']]
在这里,我们知道对于给定的输入,我们期望得到一定的输出,因此,我们可以使用以下代码进行测试:
import pandas as pd
from pandas.testing import assert_frame_equal
import numpy as np
from unittest import TestCase
def test_change():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
expected = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'change_in_naughty_robots': [np.nan, 3, 1, 2],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
result = add_difference(asimov_dataset_input)
assert_frame_equal(expected, result)
对于每个独立的功能,您将编写一个单元测试,以确保数据转换过程的每个部分都对数据产生预期的影响。对于每个功能,您还应该考虑不同的场景(是否有 if 语句?那么应该测试所有条件)。然后,这些将在每次提交时作为持续集成 (CI) 流水线的一部分运行。
除了检查代码是否符合预期之外,单元测试还可以帮助我们调试问题。通过添加一个重现新发现的错误的测试,我们可以确保在我们认为已经修复的情况下修复了该错误,并且我们可以确保该错误不会再次发生。
最后,这些测试不仅检查代码是否符合预期,还帮助我们记录了我们在创建功能时的期望。
集成测试
这些测试旨在确定单独开发的模块组合在一起时是否按预期工作。就数据流水线而言,可以检查如下事项:
数据清理过程产生适合模型的数据集
模型训练可以处理提供给它的数据并输出结果(确保将来可以重构代码)
因此,如果我们采用上面的单元测试函数并添加以下两个函数:
def remove_nan_size(asimov_dataset):
return asimov_dataset.dropna(subset=['robot_takeover_type'])
def clean_data(asimov_dataset):
asimov_dataset_with_difference = add_difference(asimov_dataset)
asimov_dataset_without_na = remove_nan_size(asimov_dataset_with_difference)
return asimov_dataset_without_na
然后我们可以使用以下代码来测试组合 clean_data 中的函数是否会产生预期的结果:
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3],
'robot_takeover_type': ['A', 'B', np.nan, 'A']
})
expected = pd.DataFrame({
'total_naughty_robots': [1, 4, 3],
'change_in_naughty_robots': [np.nan, 3, 2],
'robot_takeover_type': ['A', 'B', 'A']
}).reset_index(drop=True)
result = clean_data(asimov_dataset_input).reset_index(drop=True)
assert_frame_equal(expected, result)
现在假设我们要做的下一件事是将上述数据输入逻辑回归模型。
from sklearn.linear_model import LogisticRegression
def get_reression_training_score(asimov_dataset, seed=9787):
clean_set = clean_data(asimov_dataset).dropna()
input_features = clean_set[['total_naughty_robots',
'change_in_naughty_robots']]
labels = clean_set['robot_takeover_type']
model = LogisticRegression(random_state=seed).fit(input_features, labels)
return model.score(input_features, labels) * 100
虽然我们不知道期望值,但我们可以确保我们始终得到相同的值。 测试这种集成对我们很有用,以确保:
模型可以使用数据(每个输入都存在一个标签,数据类型由所选模型的类型决定,等等)
我们能够在未来重构我们的代码,而不会破坏端到端的功能。
我们可以通过为随机生成器提供相同的种子来确保结果始终相同。 所有主要的库都允许您设置种子(Tensorflow 有点特殊,因为它需要您通过 numpy 设置种子,所以请记住这一点)。 测试可能如下所示:
from numpy.testing import assert_equal
def test_regression_score():
asimov_dataset_input = pd.DataFrame({
'total_naughty_robots': [1, 4, 5, 3, 6, 5],
'robot_takeover_type': ['A', 'B', np.nan, 'A', 'D', 'D']
})
result = get_reression_training_score(asimov_dataset_input, seed=1234)
expected = 40.0
assert_equal(result, 50.0)
这类测试不会像单元测试那样多,但它们仍然是 CI 流水线的一部分。 您将使用这些来检查组件的端到端功能,因此,将测试更多主要场景。
机器学习验证
现在我们已经测试了我们的代码,我们还需要测试 ML 组件是否正在解决我们试图解决的问题。当我们谈论产品开发时,ML 模型的原始结果(无论基于统计方法多么准确)几乎从来都不是所需的最终输出。这些结果通常在被用户或其他应用程序使用之前与其他业务规则相结合。因此,我们需要验证模型是否解决了用户问题,而不仅仅是准确率/f1-score/其他统计量度是否足够高。
这对我们有什么帮助?
它确保模型真正帮助产品解决手头的问题
例如,如果20%的准确率不正确导致患者无法获得所需的治疗,那么将蛇咬伤分类为致命或非致命的模型就不是一个好模型。
它确保模型产生的价值在行业方面是有意义的
例如,如果向用户显示的最终价格的值太低/太高,而在该行业/市场中没有意义,那么以 70% 的准确度预测价格变化的模型就不是一个好的模型。
它提供了一层额外的决策文档,帮助工程师在流程的后期加入团队。
它以通用语言提供产品的ML组件的可见性;让客户、产品经理和工程师以同样的方式理解。
这种验证应该定期运行(通过 CI 流水线或 cron 作业),其结果应该对组织可见。这确保了组织可以看到数据科学组件的进展,并确保及早发现由更改或陈旧数据引起的问题。
总结
ML 组件可以通过多种方式进行测试,为我们带来以下优势:
产生一种数据驱动的方法,以确保代码执行预期的操作
确保我们可以在不破坏产品功能的情况下重构和清理代码
记录功能、决策和以前的错误
提供产品 ML 组件的进度和状态的可见性
因此,不要害怕,如果你有编写代码的技能,你就有编写测试的技能,并获得上述所有优势。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












