

目录
前言
问题分析
Selenium简介
Selenium安装
Selenium基础知识
Xpath
动手实战
总结
前言
问题分析
我们以如何下载下面这篇文章为例,分析问题:
URL:https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html
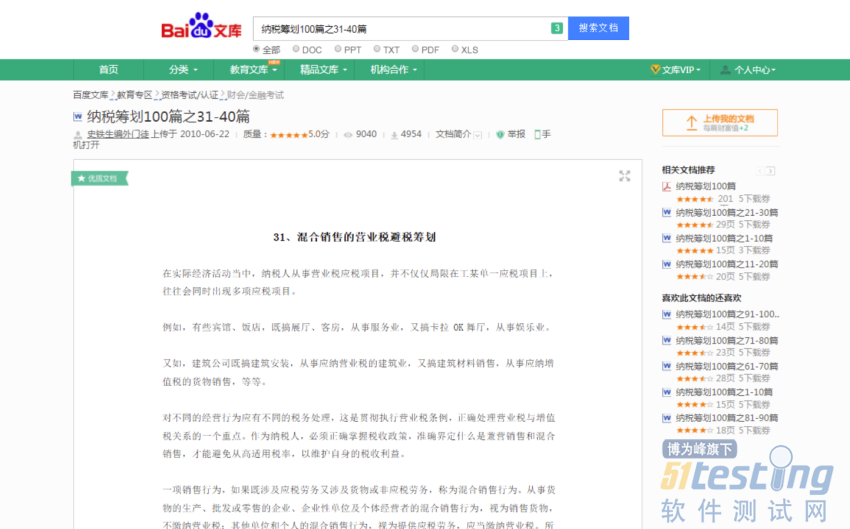
如果只是纯粹爬取这种文章还是挺好爬的,但是我们翻到文章的最下方,我们可以看到如下内容:
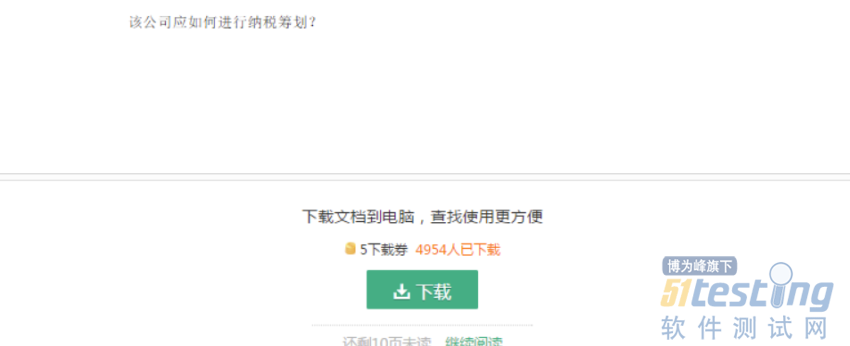
我们可以看到我们需要点击继续阅读才能显示后续的内容。照之前的思路,我们当然是抓包分析,但是抓包后我们却发现:
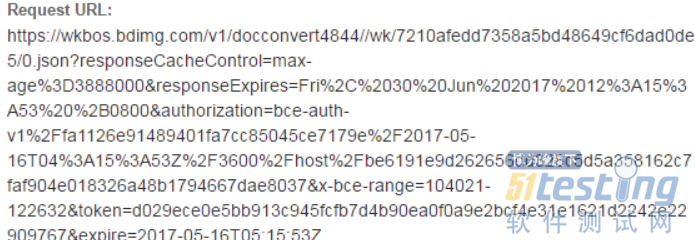
Request URL太长,而且除了后面expire时间信息外其他信息不好解决,所以我们果断放弃这个方法。
问题:获取当前页好办,怎么获取接下来页面的内容?
带着这个思考,Selenium神器走入了我的视线。
预备知识
Selenium简介
Selenium是什么?一句话,自动化测试工具。它支持各种浏览器,包括Chorome,Safari,Firefox等主流界面式浏览器,如果你在这些浏览器里面安装一个Selenium的插件,那么便可以方便地实现Web界面的测试。换句话说叫Selenium支持这些浏览器驱动。Selenium支持多种语言开发,比如Java,C,Ruby等等,而对于Python,当然也是支持的。
安装
| pip3 install selenium |
基础知识
详细内容可查看官方文档http://selenium-python.readthedocs.io/index.html
小试牛刀
我们先来一个小例子感受一下Selenium,我们用Chorme浏览器来测试。
| from selenium import webdriver browser = webdriver.Chrome() browser.get('http://www.baidu.com/') |
运行这段代码,会自动打开浏览器,然后访问百度。
如果程序执行错误,浏览器没有打开,那么应该是没有安装Chrome浏览器或者Chrome驱动没有配置在环境变量里,大家自行下载驱动,然后将驱动文件路径配置在环境变量即可。
驱动下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
当然,你不设置环境变量也是可以的,程序也可以这样写:
from selenium import webdriver browser = webdriver.Chrome('path\to\your\chromedriver.exe') browser.get('http://www.baidu.com/') |
上面的path\to\your\chromedriver.exe是你爹chrome驱动文件位置,可以使用绝对路径。我们通过驱动的位置传递参数,也可以调用驱动,结果如下图所示:

模拟提交
下面的代码实现了模拟提交搜索的功能,首先等页面加载完成,然后输入到搜索框文本,点击提交,然后使用page_source打印提交后的页面的信息。
from selenium import webdriver from selenium.webdriver.common.keys import Keys driver = webdriver.Chrome() driver.get("http://www.python.org") assert "Python" in driver.title elem = driver.find_element_by_name("q") elem.send_keys("pycon") elem.send_keys(Keys.RETURN) print(driver.page_source) |
全自动效果图如下所示:
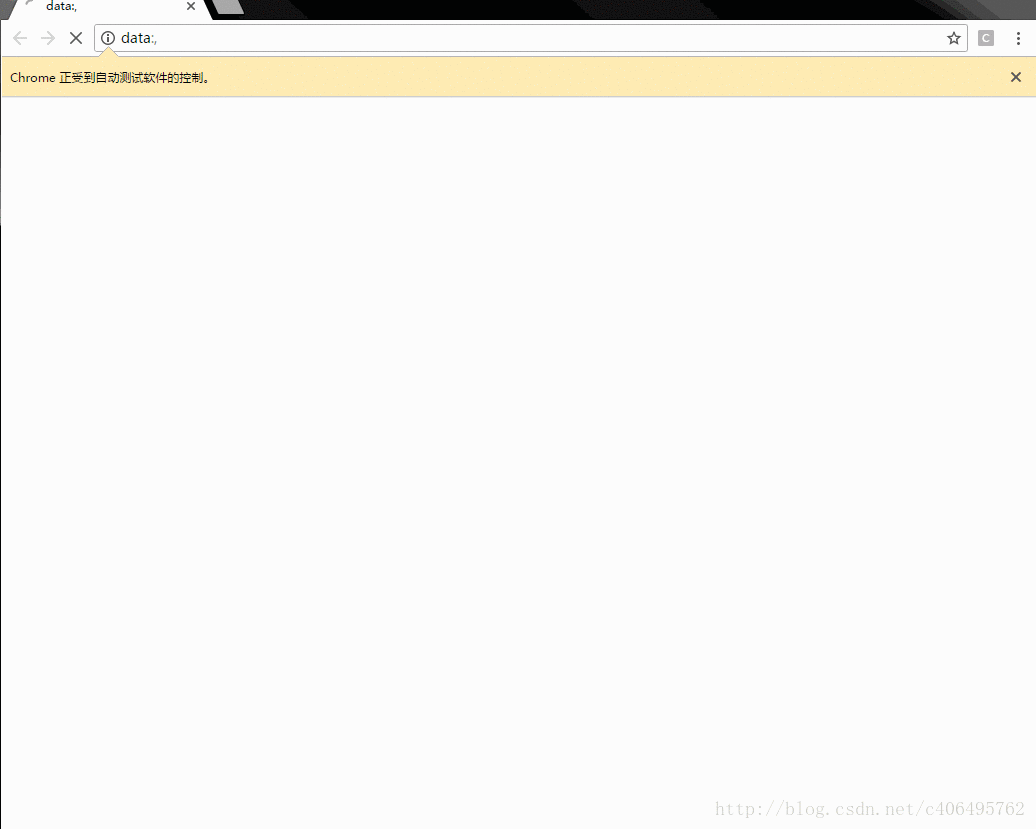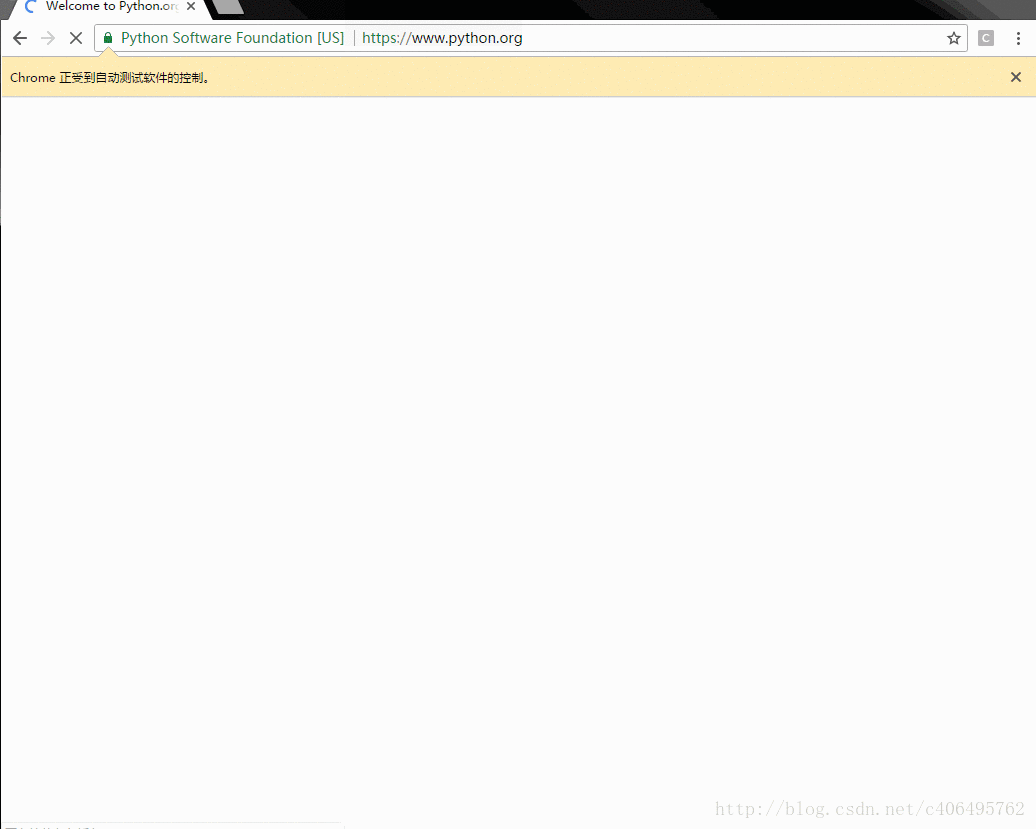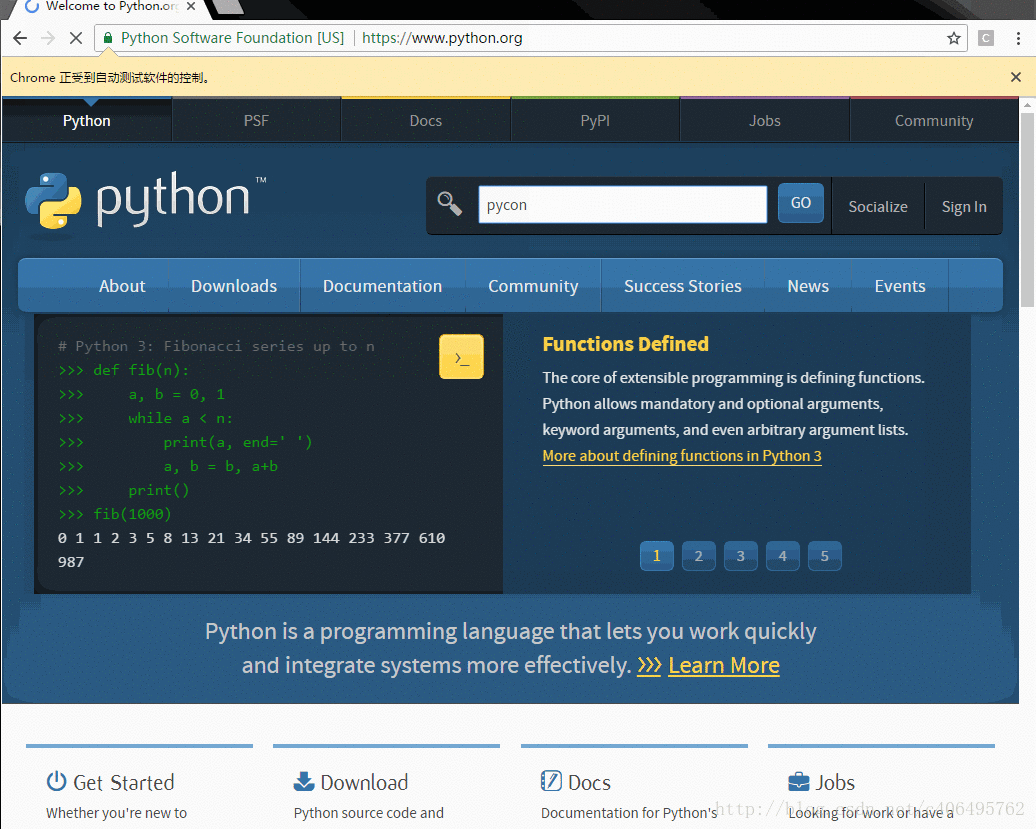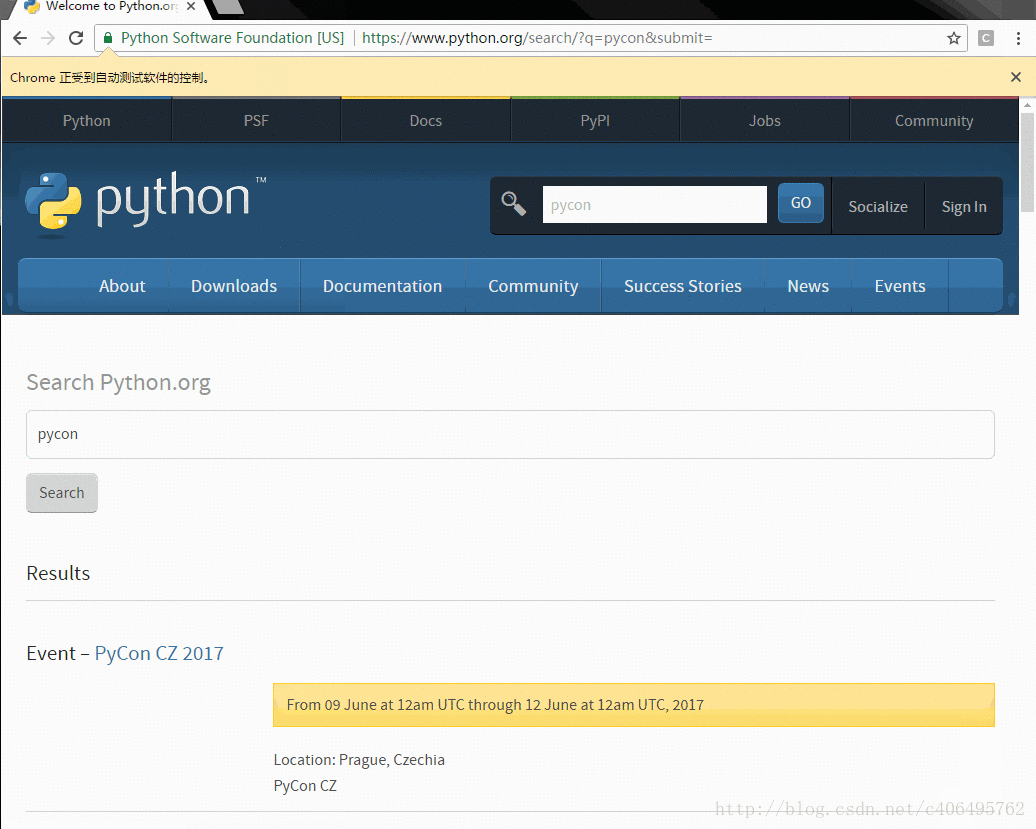
其中driver.get方法会打开请求的URL,WebDriver会等待页面完全加载完成之后才会返回,即程序会等待页面的所有内容加载完毕,JS渲染完毕之后才继续往下执行。注意,如果这里用到了特别多的Ajax的话,程序可能不知道是否已经完全加载完毕。
WebDriver提供了许多寻找网页元素的方法,譬如find_element_by_*的方法。例如一个输入框可以通过find_element_by_name方法寻找name属性来确定。
然后我们输入文本并模拟了点击回车,就像我们敲击键盘一样。我们可以利用Keys这个类来模拟键盘输入。
最后最重要的一点是可以获取网页渲染后的源代码。通过输出page_source属性即可。这样,我们就可以做到网页的动态爬去了。
元素选取
关于元素选取,有如下的API:
单个元素选取:
find_element_by_id find_element_by_name find_element_by_xpath find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name find_element_by_css_selector |
多个元素选取:
find_elements_by_name find_elements_by_xpath find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name find_elements_by_css_selector |
另外还可以利用By类来确定那种选择方式:
from selenium.webdriver.common.by import By driver.find_element(By.XPATH, '//button[text()="Some text"]') driver.find_elements(By.XPATH, '//button') |
By类的一些属性如下:
find_elements_by_name find_elements_by_xpath find_elements_by_link_text find_elements_by_partial_link_text find_elements_by_tag_name find_elements_by_class_name find_elements_by_css_selector |
这些方法跟JS的一些方法有相似之处,find_element_by_id,就是根据标签的id属性查找元素,find_element_by_name,就是根据标签的name属性查找元素。举个简单的例子,比如我想找到下面这个元素:
| <input type="text" name="passwd" id="passwd-id" /> |
我们可以这样获取他:
element = driver.find_element_by_id("passwd-id") element = driver.find_element_by_name("passwd") element = driver.find_elements_by_tag_name("input") element = driver.find_element_by_xpath("//input[@id='passwd-id']") |
前三个都很好理解,最后一个xpath是什么意思?xpath是一个非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素,在后面我会单独讲解。
界面交互
通过元素选取,我们能够找到元素的位置,我们可以根据这个元素的位置进行相应的事件操作,例如输入文本框内容、鼠标点击、填充表单、元素拖拽等等。由于篇幅原因,我就不一个一个讲解了,主要讲解本次实战用到的鼠标点击,更详细的内容可以查看官方文档
lem = driver.find_element_by_xpath("//a[@data-fun='next']") elem.click() |
比如上面这句话,我使用find_element_by_xpath()找到元素位置,暂且不用理会这句话是什么意思,暂且理解为找到了一个按键的位置。然后我们使用click()方法,就可以触发鼠标左键点击时间。是不是很简单?但是有一点需要注意,就是在点击的时候,元素不能有遮挡。什么意思?就是说我在点击这个按键之前,窗口最好移动到那里,因为如果这个按键被其他元素遮挡,click()就触发异常。因此稳妥起见,在触发鼠标左键单击事件之前,滑动窗口,移动到按键上方的一个元素位置:
page = driver.find_elements_by_xpath("//div[@class='page']") driver.execute_script('arguments[0].scrollIntoView();', page[-1]) #拖动到可见的元素去 |
上面的代码,就是将窗口滑动到page这个位置,在这个位置,我们能够看到我们需要点击的按键。
添加User-Agent
使用webdriver,是可以更改User-Agent的,代码如下:
from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"') driver = webdriver.Chrome(chrome_options=options) driver.get('https://www.baidu.com/') |
Xpath
Xpath是很强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。在正式开始使用之前,我们先了解下什么是Xpath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设我们现在以图所示HTML代码为例,要引用对应的对象,XPath语法如下:

绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):
| /html/body/form[1] |
注意:
元素的xpath绝对路径可通过firebug直接查询。
般不推荐使用绝对路径的写法,因为一旦页面结构发生变化,该路径也随之失效,必须重新写。
绝对路径以单/号表示,而下面要讲的相对路径则以//表示,这个区别非常重要。另外需要多说一句的是,当xpath的路径以/开头时,表示让Xpath解析引擎从文档的根节点开始解析。当xpath路径以//开头时,则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当/出现在xpath路径中时,则表示寻找父节点的直接子节点,当//出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级(这些下面都有例子,大家可以参照来试验)。弄清这个原则,就可以理解其实xpath的路径可以绝对路径和相对路径混合在一起来进行表示,想怎么表示就怎么表示。
下面是相对路径的引用写法:
查找页面根元素://
查找页面上所有的input元素://input
查找页面上第一个form元素内的直接子input元素(即只包括form元素的下一级input元素,使用绝对路径表示,单/号)://form[1]/input
查找页面上第一个form元素内的所有子input元素(只要在form元素内的input都算,不管还嵌套了多少个其他标签,使用相对路径表示,双//号)://form[1]//input
查找页面上第一个form元素://form[1]
查找页面上id为loginForm的form元素://form[@id='loginForm']
查找页面上具有name属性为username的input元素://input[@name='username']
查找页面上id为loginForm的form元素下的第一个input元素://form[@id='loginForm']/input[1]
查找页面具有name属性为contiune并且type属性为button的input元素://input[@name='continue'][@type='button']
查找页面上id为loginForm的form元素下第4个input元素://form[@id='loginForm']/input[4]
Xpath功能很强大,所以也可以写的更负责一些,如下图html源码:
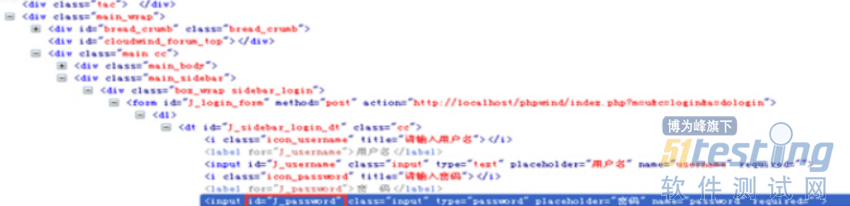
如果我们现在要引用id为“J_password”的input元素,该怎么写呢?我们可以像下面这样写:
| //*[@id='J_login_form']/dl/dt/input[@id='J_password'] |
也可以写成:
| //*[@id='J_login_form']/*/*/input[@id='J_password'] |
这里解释一下,其中//*[@id=’ J_login_form’]这一段是指在根元素下查找任意id为J_login_form的元素,此时相当于引用到了form元素。后面的路径必须按照源码的层级依次往下写。按照代码,我们要找的input元素包含在一个dt标签里面,而dt又包含在dl标签内,所以中间必须写上dl和dt两层,才到input这层。当然我们也可以用*号省略具体的标签名称,但元素的层级关系必须体现出来,比如我们不能写成//*[@id='J_login_form']/input[@id='J_password'],这样肯定会报错的。
前面讲的都是xpath中基于准确元素属性的定位,其实xpath作为定位神器也可以用于模糊匹配。本次实战,可以进行准确元素定位,因此就不讲模糊匹配了。如果有兴趣,可以自行了解。
动手实战
以上面提到的文章为例,进行爬取讲解。
页面切换
由于网页的百度文库负责,可能抓取内容不全,因此使用User-Agent,模拟手机登录,然后打印文章标题,文章页数,并进行翻页。先看下这个网站。
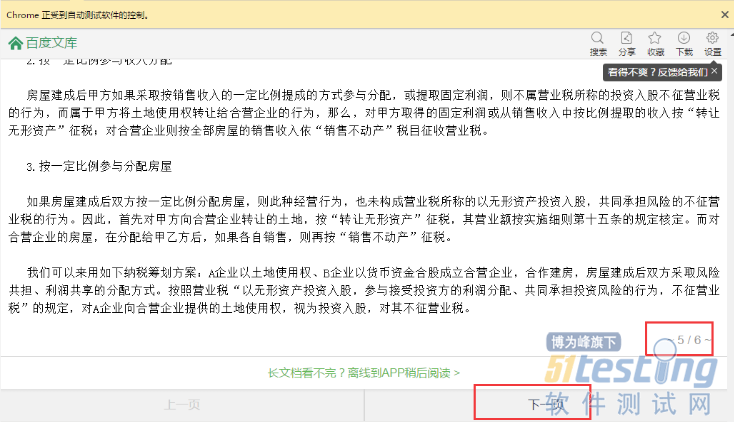
我们需要找到两个元素的位置,一个是页码元素的位置,我们根据这个元素的位置,将浏览器的滑动窗口移动到这个位置,这样就可以避免click()下一页元素的时候,有元素遮挡。然后找到下一页元素的位置,然后根据下一页元素的位置,触发鼠标左键单击事件。
我们审查元素看一下,这两个元素:
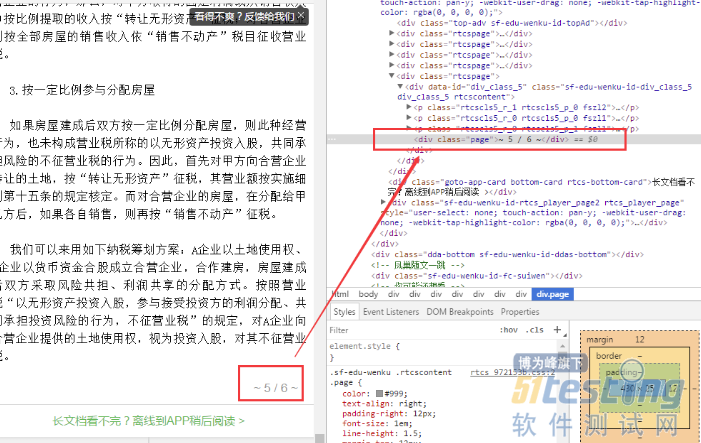

我们根据这两个元素,就可以通过xpath查找元素位置,代码分别如下:
page = driver.find_elements_by_xpath("//div[@class='page']") nextpage = driver.find_element_by_xpath("//a[@data-fun='next']") |
由于page元素有很多,所以我们使用find_elements_by_xpath()方法查找,然后使用page[-1],也就是链表中的最后一个元素的信息进行浏览器窗口滑动,代码如下:
from selenium import webdriver options = webdriver.ChromeOptions() options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"') driver = webdriver.Chrome(chrome_options = options) driver.get('https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html') page = driver.find_elements_by_xpath("//div[@class='page']") driver.execute_script('arguments[0].scrollIntoView();', page[-1]) #拖动到可见的元素去 nextpage = driver.find_element_by_xpath("//a[@data-fun='next']") nextpage.click() |
内容爬取
爬取内容使用的是BeautifulSoup,这里不细说,审查元素,自己分析一下就可以。代码如下:
from selenium import webdriver from bs4 import BeautifulSoup options = webdriver.ChromeOptions() options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"') driver = webdriver.Chrome(chrome_options=options) driver.get('https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html') html = driver.page_source bf1 = BeautifulSoup(html, 'lxml') result = bf1.find_all(class_='rtcspage') for each_result in result: bf2 = BeautifulSoup(str(each_result), 'lxml') texts = bf2.find_all('p') for each_text in texts: main_body = BeautifulSoup(str(each_text), 'lxml') for each in main_body.find_all(True): if each.name == 'span': print(each.string.replace('\xa0',''),end='') elif each.name == 'br': print('') |
爬取结果如下:

整体代码
我们能够翻页,也能够爬取当前页面内容,代码稍作整合,就可以爬取所有页面的内容了。找下网页的规律就会发现,5页文章放在一个网页里。思路:爬取正文内容,再根据爬取到的文章页数,计算页数/5.0,得到一个分数,如果这个分数大于1,则翻页继续爬,如果小于或等于1,代表到最后一页了。停止翻页。有一点注意一下,翻页之后,等待延时一下,等待页面加载之后在爬取内容,这里,我们使用最简单的办法,用sleep()进行延时。因此总体代码如下:
from selenium import webdriver from bs4 import BeautifulSoup import re if __name__ == '__main__': options = webdriver.ChromeOptions() options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"') driver = webdriver.Chrome(chrome_options=options) driver.get('https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html') html = driver.page_source bf1 = BeautifulSoup(html, 'lxml') result = bf1.find_all(class_='rtcspage') bf2 = BeautifulSoup(str(result[0]), 'lxml') title = bf2.div.div.h1.string pagenum = bf2.find_all(class_='size') pagenum = BeautifulSoup(str(pagenum), 'lxml').span.string pagepattern = re.compile('页数:(\d+)页') num = int(pagepattern.findall(pagenum)[0]) print('文章标题:%s' % title) print('文章页数:%d' % num) while True: num = num / 5.0 html = driver.page_source bf1 = BeautifulSoup(html, 'lxml') result = bf1.find_all(class_='rtcspage') for each_result in result: bf2 = BeautifulSoup(str(each_result), 'lxml') texts = bf2.find_all('p') for each_text in texts: main_body = BeautifulSoup(str(each_text), 'lxml') for each in main_body.find_all(True): if each.name == 'span': print(each.string.replace('\xa0',''),end='') elif each.name == 'br': print('') print('\n') if num > 1: page = driver.find_elements_by_xpath("//div[@class='page']") driver.execute_script('arguments[0].scrollIntoView();', page[-1]) #拖动到可见的元素去 nextpage = driver.find_element_by_xpath("//a[@data-fun='next']") nextpage.click() time.sleep(3) else: break |
运行结果:

总结
这样的爬取只是为了演示Selenium使用,缺点很明显:
没有处理图片
代码通用性不强
等待页面切换方法太out,可以使用显示等待的方式,等待页面加载
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












