

在做自动化测试的时候,经常会遇到需要输入验证码的地方,有些可以让开发屏蔽,但是有些不行,这时候,我们可以调用tesseract来实现图像的识别。
在JAVA中调用tesseract,主要有两种方式:cmd方式,tess4j方式。我要介绍的是用tess4j的方式来识别图像,得到验证码。
首先要在工程中加入tess4j的jar包,如果是maven
项目,可以从中央仓库中获取https://mvnrepository.com/ 直接搜索tess4j
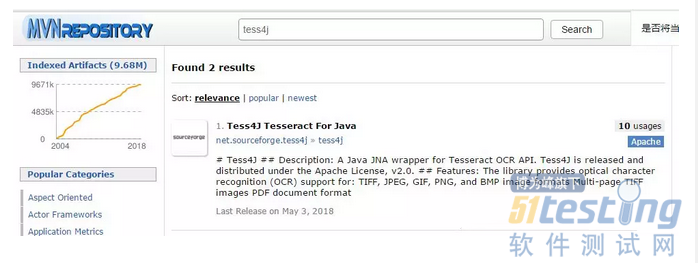
点击打开

选择使用比较多的,点进去
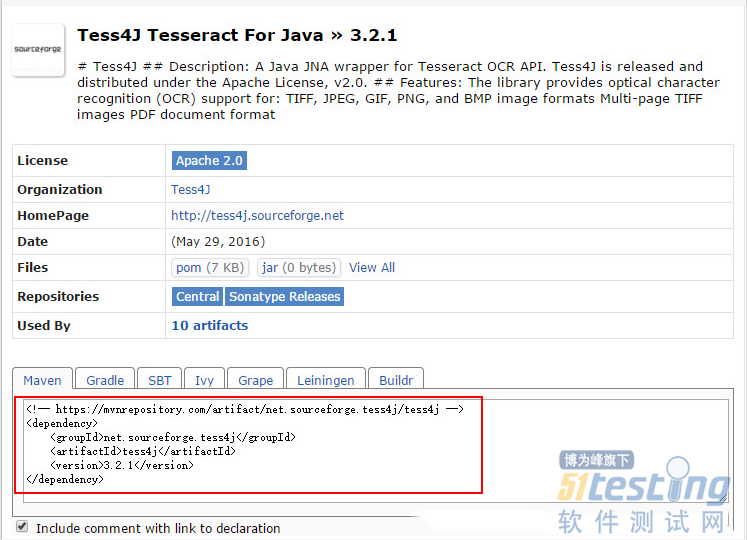
复制这段代码粘贴到maven工程的pom.xml里面
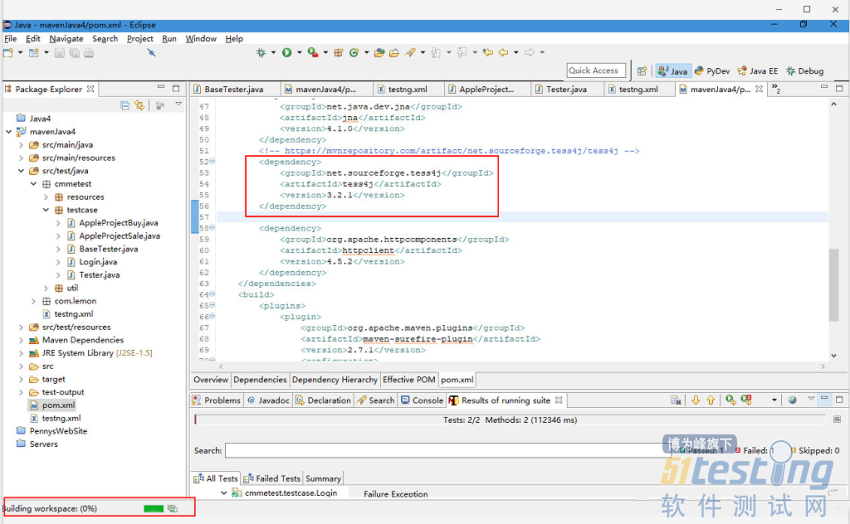
等待下载完成
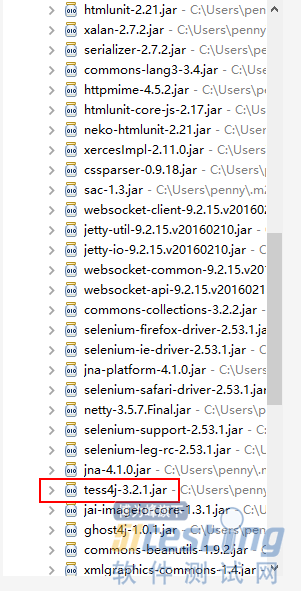
安装完成之后,在Maven Dependencies库中会出现tess4j的jar包,官方解释tess4j:A Java JNA wrapper for Tesseract OCR API.
也就是说:tess4j是针对tesseract进行封装的javaAPI。安装好依赖库之后,就不需要另外再安装tessereact-ocr了,因为tess4j的jar包里面自带了tessereact-ocr。
安装好之后,如果没有把文字库tessdata放到项目中,调用的时候会报错,如下
Error opening data file ./tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Could not initialize tesseract.
这里提示的是环境变量没有设置,这是针对安装tessreact-ocr的调用的错误提示,所以按照这个去加环境变量,问题还是会出现的(这里我折腾了好久才解决)。
针对依赖库的方法调用,解决这个问题的正确做法是在maven项目的resources路径下添加tessdata文字库
eng.traineddata是英文语言包,识别字母和数字。
如果想要识别中文(数字 + 中文),需要在下载chi_sim.traineddata语言包。这样tess4j就能正常使用了。
接下来是调用过程,要是别验证码,主要的步骤是得到验证码图片,进行识别,输出识别结果。
得到验证码图片分为三步:
1、 将验证码页面截图保存
public byte[] takeScreenshot(WebDriver driver) throws IOException { byte[] screenshot = null; screenshot = ((TakesScreenshot) driver) .getScreenshotAs(OutputType.BYTES);//得到截图 return screenshot; } |
2、得到的图片是整个屏幕的截图,我们可以处理一下,对图片进行截取,只保留验证码那一部分
public BufferedImage createElementImage(WebDriver driver, WebElement webElement, int x, int y, int width, int heigth)//开始裁剪的位置和截图的宽和高 throws IOException { Dimension size = webElement.getSize(); BufferedImage originalImage = ImageIO.read(new ByteArrayInputStream( takeScreenshot(driver))); BufferedImage croppedImage = originalImage.getSubimage(x, y, size.getWidth() + width, size.getHeight() + heigth);//进行裁剪 return croppedImage; |
3、tesseract读取图片,获得验证码,默认是英文,如果要使用中文包,加上instance.setLanguage("chi_sim");
private String getVerificationCode(String path) { File imageFile = new File(path); try { imageFile.createNewFile(); } catch (IOException e1) { e1.printStackTrace(); } WebElement element = driver.findElement(By .cssSelector("img[id='codeImg']")); try { BufferedImage image = createElementImage(driver, element, 687, 362, 54, 18);//得到裁剪的图片 ImageIO.write(image, "png", imageFile);//进行保存 } catch (IOException e) { e.printStackTrace(); } ITesseract instance = new Tesseract();//调用Tesseract URL url = ClassLoader.getSystemResource("tessdata");//获得Tesseract的文字库 String tesspath = url.getPath().substring(1); instance.setDatapath(tesspath);//进行读取,默认是英文,如果要使用中文包,加上instance.setLanguage("chi_sim"); String result = null; try { result = instance.doOCR(imageFile); } catch (TesseractException e1) { e1.printStackTrace(); } result = result.replaceAll("[^a-z^A-Z^0-9]", "");//替换大小写及数字 return result; } |
执行结果,得到的图片

得到的验证码

总结:tess4j安装比较方便,只要引入jar就行,不需要额外安装其他软件,tess4j下也封装了图片处理的工具类:如缩放,旋转等(这些我还没用到)。
另外在读取图片的时候,还是比较容易出错的 比如t和l,i和l,e和o容易出现错读的情况,希望有大佬可以完善我的方法,提高正确率。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












