

1、前言
上周一位朋友在进行一些项目开发时,其中需要用到腾讯动漫中动漫的图片,但是自己手动一张一张另存为图片进行保存太浪费时间了,于是就用Python来进行抓取,但是很无奈腾讯动漫的章节动漫DOM元素是异步加载的,另外图片也使用了懒加载,使用一般的抓取方式肯定是行不通,于是我们就进行分析了一波,最终成功的获取到图片链接,之后就可以为所欲为了~
2、正文
首先,我们需要选取一部动漫,就拿《最强兵王》 作为例子吧,获取他第一章节的url,即为http://ac.qq.com/ComicView/index/id/631111/cid/4 ,首先我们先看看页面渲染的HTML:

由上图可以看出,漫画的主题部分均是使用JS模板来进行渲染的,所以我们需要等页面加载完成之后,在获取他的HTML元素:
from selenium import webdriverimport timeif __name__ == '__main__': driver = webdriver.PhantomJS() driver.get("http://ac.qq.com/ComicView/index/id/631111/cid/4") time.sleep(3) out_html= driver.find_element_by_xpath("//*").get_attribute("outerHTML") |
上述代码中,我们将webdriver获取到页面之后进行睡眠3秒(即为等待3秒后继续执行下面的代码),那么这个时候JS已经将完整的漫画DOM元素渲染完成,我们就可以直接获取到渲染之后的完整的HTML。
不过这个时候我们发现一个问题:就是所有的漫画内的图片的URL都是相同的:
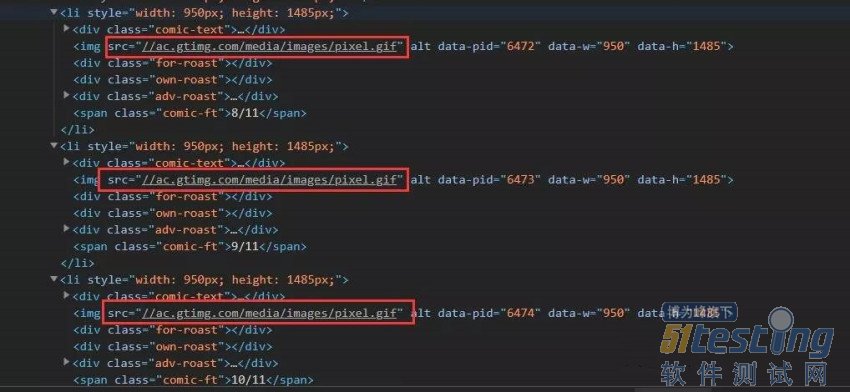
然后进行简单的测试发现,漫画章节图使用了懒加载的模式,即为滚动到某个图片的上方固定PX值时才进行加载真实的URL图片,那么我们就需要执行一段JS来模拟浏览器滚动,但是滚动不能太快,否则懒加载不会进行图片加载。修改之后的代码为:
| driver = webdriver.PhantomJS() driver.get("http://ac.qq.com/ComicView/index/id/631111/cid/4") time.sleep(3) driver.execute_script(""" var temp_index = 100; setInterval(function(){ window.scrollTo(0,temp_index+=100); },30); """) time.sleep(5) out_html = driver.find_element_by_xpath("//*").get_attribute("outerHTML") |
到这一步,我们就拿到了动漫章节包含真实的图片URL的完整HTML代码,接下来就可以为所欲为了,这里我使用了BeautifulSoup来进行获取属性值,所以最终的代码脚本为:
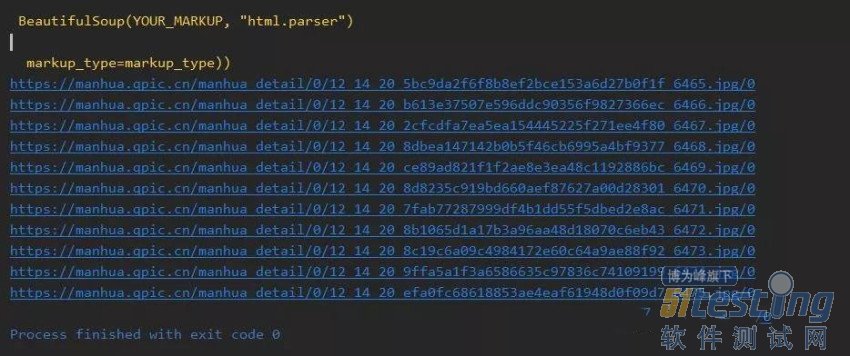
| from selenium import webdriverimport timefrom bs4 import BeautifulSoup if __name__ == '__main__': driver = webdriver.PhantomJS() driver.get("http://ac.qq.com/ComicView/index/id/631111/cid/4") time.sleep(3) driver.execute_script(""" var temp_index = 100; setInterval(function(){ window.scrollTo(0,temp_index+=100); },30); """) time.sleep(5) out_html = driver.find_element_by_xpath("//*").get_attribute("outerHTML") soup = BeautifulSoup(out_html) comic_contain = soup.find('ul', id='comicContain') img_list = comic_contain.find_all('img', class_='loaded') for i in img_list: print(i['src']) # 章节内每个漫画图的真实URL |
效果为:
3、后记
总体来说,本次代码的编写过程还算顺利,其对整个的情况分析也是比较清楚,另外现在越来越多的网站都是使用的异步加载,感觉之后又要有一波新的技术即将来袭~
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












