

RFM是客户分析及衡量客户价值的重要模型之一,其中的R表示最近一次消费(Recency),F表示消费频率(Frequency),M表示消费金额(Monetary)。依据这三个指标RFM可以将客户动态分组,并进一步指导客户运营的下一步工作。本篇文章使用python的聚类算法创建一个粗糙的RFM模型。

1. 开始前的准备工作
首先是开始前的准备工作,这里除了常用的numpy和pandas以外,有几个库文件单独说明下,pymysql是python连接mysql进行数据提取的库,cluster用于聚类,此外还有一些库文件在本篇文章中并没有使用到,例如DecisionTreeClassifier,grid_search和cross_validation等等。这些会在后面对RFM模型进行进一步分类预测,模型持久化和依据RFM模型做内容推荐时使用到。因此先一起放在这里,后面的系列文章会进行使用说明。
#导入库文件 import numpy as np import pandas as pd import pymysql from sklearn.cluster import KMeans from sklearn.tree import DecisionTreeClassifier import os from sklearn import cross_validation import matplotlib.pyplot as plt from sklearn.externals import joblib from math import sqrt from sklearn import grid_search from sklearn.ensemble import RandomForestClassifier |
2. 从mysql提取RFM指标数据
原始的用户数据存储在mysql中,因此需要使用python连接mysql进行数据提取。下面是具体的代码和数据提取过程。
#连接数据库连接 db = pymysql.connect(host="",user=" ",passwd=" ",port=,db=" " ) # 使用 cursor() 方法创建一个游标对象 cursor cursor = db.cursor() #计算并提取RFM指标的SQL语句 sql="SELECT a.`user_id`,ABS(TIMESTAMPDIFF(YEAR,NOW(),DATE_FORMAT(MID(b.`id_no`,7,8),'%Y-%m-%d'))) AS age, a.`client_type`,a.`acct_bal`,a.`amount`,TIMESTAMPDIFF(DAY,NOW(),MAX(FROM_UNIXTIME(trans_time,'%y-%m-%d %H:%i:%s'))) AS R,COUNT(id) AS F,SUM(a.`amount`)AS M FROM qb_account_detail AS a JOIN qb_user_info AS b ON a.`user_id`=b.`user_id` WHERE a.`trans_time`> '1498838400' AND a.`trans_type`='201' AND NOT ISNULL(id_no) AND id_no <> 'null' GROUP BY b.`id_no`;" # 使用 execute() 方法执行 SQL 查询 cursor.execute(sql) 895 # 使用 fetchall() 方法获取全部数据. data = cursor.fetchall() #查看数据 print(data) data |
使用提取的数据创建DataFrame数据表,取名为rfm。
#创建RFM数据表 columnlist=['user_id','age','client_type','acct_bal','amount','recency','frequency','monetary'] rfm=pd.DataFrame.from_records(list(data),columns=columnlist) |
查看数据表的前5行数据,这里除了创建RFM模型必要的指标以外,还保留了用户ID,年龄等信息,也是为了后面的分类和推荐使用。
#查看数据表前5行 rfm.head() rfm |

3. 使用K-Means进行RFM模型聚类
单独提取数据表中frequency,monetary,和recency三个字段进行聚类。首先转化为数组。
#转化为数组 rfm_new = np.array(rfm[['frequency','monetary','recency']]) #设置随机数 seed=9 |
设置KMeans模型参数,并代入指标数据进行拟合。
#对数据进行聚类 clf=KMeans(n_clusters=8,random_state=seed) #拟合模型 clf=clf.fit(rfm_new) |
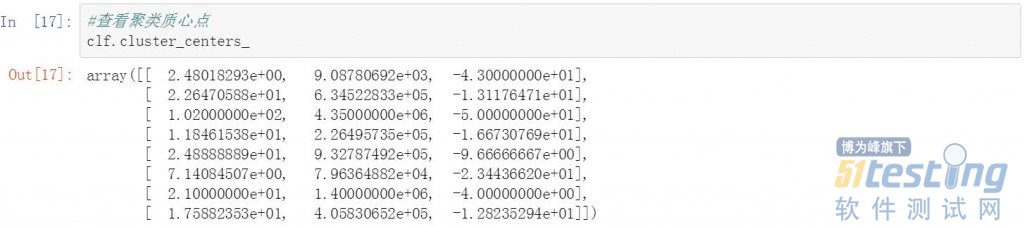
查看KMeans聚类后的8个质心点的值。
#查看聚类质心点 clf.cluster_centers_ |
查看聚类质心点
在原始数据表中对每个用户进行聚类结果标记。这样我们就可以知道每个用户ID在RFM模型中所属的类别。
#对原数据表进行类别标记 rfm['label']= clf.labels_ #查看标记后的数据 rfm.head() |
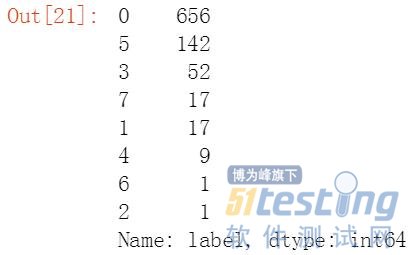
查看RFM模型8个类别中的用户数量。
#计算每个类别的数据量 c=rfm["label"].value_counts() |
计算每个类别的数据量
本篇文章的内容到这里结束了,后面的系列文章我们还会使用决策树学习用户聚类的结果,然后对新用户进行价值分类的预测,或根据前端渠道数据更准确的捕获高价值客户。以及对现有聚类后的用户连接更多的行为数据,对不同类别的用户甚至新用户进行内容推荐,进一步提升用户的价值。更兴趣的朋友请继续关注。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












