
我们是这样做大数据测试
上一篇 / 下一篇 2021-01-07 15:42:07 / 个人分类:大数据
先交代一下背景,上游各种业务系统数据进入到TIDB,再TIDB到HIVE。开发同事开发一个报表,需要写flow,一个flow会包含一个或者多个job。每个job就是执行sql,从HIVE表中查询数据,根据业务逻辑计算数据,将结果写入HIVE,最终生成报表。flow执行过程是由azkaban调度。
测试工具的示意图来一个。
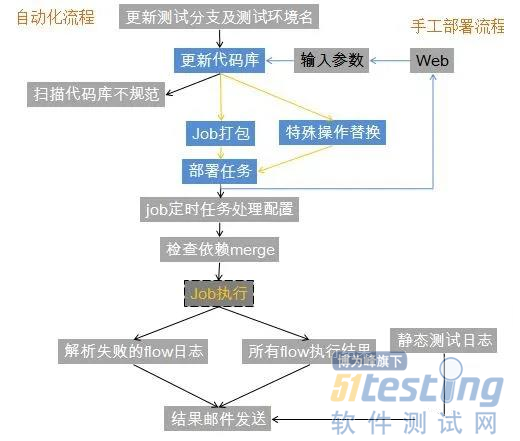
第一部分,更新环境名及分支信息。这是很多工具共用的。很多工具需要知道当前应该跑什么分支,在哪个环境执行。所有就做了一个公共的工具。在文件中配置了版本日期及对应的环境,比较当前日期和版本日期关系,可以算出应该跑什么分支的代码,在哪套环境运行。每天0点1分执行,将结果写入一个配置文件,如branch=20.12.12,env=test2,当天所有的需要用到这两个参数的都可以到这个配置文件来取。
第二部分,更新代码库,先去第一部分获取当前的环境和版本信息,然后去更新代码库。
basepath=${cd `dirname $0`;pwd} if [ ! $1 ];then echo 'miss argumet' exit 1 fi cd ${basepath}'/code/reponame' git clean -xdf git reset --hard git checkout 'branch'$1 if [ $? != 0 ];then git checkout master runbranch='master' else runbranch='branch'${1} fi git pull if [ $? == 0 ];then echo 'pull successfully' else echo 'pull fail,exit' exit 1 fi |
更新代码库后做一些替换,因为我们生产一个库,测试环境多有个库,开发提测的代码是按照生产的库名。所以在测试环境执行时需要替换成对应的库名即需要环境名。
if [ ! $2 ];then echo 'miss argument' exit 1 elif [ $2 == 'full' ];then sourcedir='aa/bb/cc' targetdir='bb/cc/dd' else sourcedir='AA/BB/BB/'$2 if [ -d ${sourcedir} ];then target='BB/CC/DD/'$2 else echo 'flow not exist' exit 1 fi fi function getfilelist(){ for file in `$1` do dorf=$1'/'${file} if [ -d ${dorf} ];then getfilelist ${dorf} else echo ${dorf} fi done filelist=`getfilelist ${sourcedir}` baddbname=${basepath}'/tmp/baddb.log' cd ${basepath}'/tmp' if [ -f ${baddbname} ];then rm -rf ${baddbname} fi touch ${baddbname} cd - for file in ${filelist} do baddb=`sed -n /_test1\丨_test2\丨_dev\./Ip ${file}` if [ -n "${baddb}" ];then echo ${file} 丨awk -F 'code' '{print $2}' >> ${baddbname} echo ${baddb} >> ${baddbname} fi sed -i "s/hivedb\./hivedb_${1}\./ig" ${file} done sshpass -p password rsync -rpt ${sourcedir} user@host:${targetdir} if [ $? == 0 ];then echo 'delopy successfully' else echo 'delopy fail' exit 1 fi |
到这里,我们更新了最新的代码库,静态扫描是不是有库名写错的,然后替换成测试环境的库名。然后将文件部署到目前服务器,就是azkaban的task目录。库名如果有问题写入日志中。
第三部分了,我们就打包azkaban的job,在打包前先把要替换的进行替换这里的$1是指环境名如test1。
sourcedir=${basepath}'/code/azkaban/' tmpdir=${basepath}/'tmp/' envpath=${basepath}'/code/azkaban/env.properties' sed -i "s/mammoth\.sh/mammoth${1}\.sh/ig" ${envpath} cd ${sourcedir} zipdir=${tmpdir}'/azkaban.zip' if [ -f ${zipdir} ];then rm -rf ${zipdir} fi zip -r ${zipdir} azkaban cd - |
需要把azkaban的包部署到服务器,azkaban提供了接口上传。记录上传的结果到日志文件。
def uploadzip(filepath): files = {'file':('azkaban.zip',open(filepath,'rb'),'application/zip')} uploaddata = {'project':'project','file':files,'ajaz':'upload'} try: r1 = requests.post(managerul,data=uploaddata,file=files).json() if 'projectId' in r1.keys(): result = 'upload successfully' else result = 'upload fail' except: result = 'upload fail' return result |
第四部分,配置定时任务,同样azkaban有接口可以调用。定时任务脚本的MD5值检查一下,如果有变化就执行,没有就不用执行了。
basepath=${cd `dirname $0`;pwd} parpath=$(dirname ${basepath}) source ${parpath}'/branch.config' echo ${branch} fullbranch='20'${branch//\./} oldmdfile=${basepath}'/tmp/md5.config' arrary=(${1//,/ }) for repo in ${arrary[@]} do schedulefile=${basepath}'/code/'${repo}'/schedule/'${fullbranch}'/schedule.txt' if [[ -s ${schedulefile} ]];then newmd5=`md5sum ${schedulefile} 丨 awk '{print $1}'` oldmd5=`sed '/^${repo}='/!d;s/.*=//` ${oldmdfile} sed -i '/'${repo}'/d' ${oldmdfile} echo ${repo}'='${newmd5} >> ${oldmdfile} if [ "${newmd5}" != "${oldmd5}" ];then python3 schedule.py ${repo} ${schedulefile} fi fi done |
如果schedule文件有更新,就调用接口,没有就不更新。将更新结果写入日志中。
reponame = sys.argv[1] schedule_fule = sys.argc[2] def configschedule(): url = 'host:8000/schedule' data = {'projectName':project,'flow':flow,'cronExpression':'cron','ajax':'scheduleCronFlow'} r = reuqests.post(url,data) |
在任务执行前,我们还有一个静态测试,就是任务会检查依赖的表是否都完成了同步。如果没有完成同步,任务执行不下去。所以我们在任务执行前先检查所有的表是不是都完成merge,如果没有的,插入一个成功标识,保证job可以运行。并且将没有merge完成的表写入日志。
def getmergetable(env): fulltablesql = '''select task_name from table1 where a='bb' ''' passtablesql = '''select tablename from table2 where status='PASS' ''' failtable = [] fulltable = exelistsql(env,fulltablesql) successtable = exelistsql(env,passtablesql) conn = connectdb(env) cursor = conn.cursor() for table in fulltable: if table not in successtable: failtable.append(table) sql = '''insert into table2(....) VALUES (.....%s)'''%(table) cursor.execute(sql) conn.ommit() conn.close() |
以上这些更新,都是通过定时任务来完成,更新完这些之后,我们就完成了全部的部署,包括job,task,schedule。每天0点之后,第一个job执行之前完成这些操作。中间时间段就是job自己运行了。
早上8点20,正常情况任务基本都已经运行完成,开始分析结果。
先去查询失败的job。将失败job的exec_id复制到azkaban服务器。
def executefaillist(): failjob = querydb() failexclist = [] for job in failjob: failexclist.append(job['exec_id']) failliststr = "execids='" + ' '.join(failexclist) + "'" wirtedatatofile(failliststr) execmd = 'sh ' + currentpath + '/sendfaillist.sh' status,output = execute_cmd(execmd) |
失败的exec_id复制到目标服务器之后,执行log解析。
#!/user/bin/expect set user [lindex $argv 0] set ip [lindex $argv 1] set password [lindex $argv 2] spawn ssh $user@$ip set timeout 120 expect{ "yes/no"{send "yes\r"} "password" {send "$password\r"} } send "path/script.sh&\r" send "exit\r" expect eof |
单个执行
mainpath='path/azakban/executions/'${1} resultfile='result/result.txt' jobinfo=`ls ${mainpath}/_flow.${1}.log` if [[ ${jobinfo} ]];then workdir=`cat ${jobinfo} | grep 'working.dir' |awk -F 'working.dir' '{print $2}' |awk -F ',' '{print $1}' |sort -u` for logfile in ${workdir} do loglist = `ls ${logfile}/*.log` for filepath in ${loglist} failreason=`cat ${filepath} | grep 'ActiongException|AnalysisException|SparkException|JsonParseException' -m1 -A1` if [[ ${failreason} ]];then echo $1'|'${filepath##*/}'|'${failreason} >>${resultfile} fi done |
执行所有的
mainpath='path/azakban/executions/'${1} resultfile='result/result.txt' jobinfo=`ls ${mainpath}/_flow.${1}.log` if [[ ${jobinfo} ]];then workdir=`cat ${jobinfo} | grep 'working.dir' |awk -F 'working.dir' '{print $2}' |awk -F ',' '{print $1}' |sort -u` for logfile in ${workdir} do loglist = `ls ${logfile}/*.log` for filepath in ${loglist} failreason=`cat ${filepath} | grep 'ActiongException|AnalysisException|SparkException|JsonParseException' -m1 -A1` if [[ ${failreason} ]];then echo $1'|'${filepath##*/}'|'${failreason} >>${resultfile} fi done |
azkaban也提供了日志查询接口,也可以通过接口去查询日志后解析返回值。但是效率是差很多的。以上方法,几百个文件,1分钟以内可以搞定。
8:28,最后一个定时任务,查询所有任务的运行结果,从远程下载失败日志,和前面一样用sshpass就可以了。然后就是查询前面静态测试和各个环节的日志。拼装成一个html文件。以表格的形式直接展示在邮件正文中。哪个环境有哪些问题,失败的日志原因是什么。
mailconent1 = '''<!DOCTYPE html> <html><head>...</head><body>''' mailconent2 = '''</body></html>''' mailtable = '''<table....><thead> <tr....> <td ...>project</td> <td....>exec_id</td> <td....>flow_id</td> <td....>status</td> <td....>start_time</td> <td....>end_endtime</td> <td....>takes_time</td> <td....>reason</td> ''' |
上班前,我们就可以收到结果邮件,早上上班就可以看到所有任务执行情况了。通过一段时间运行,发现了一些潜在风险问题,测试环境提前发现,避免了生产出现问题。也发现了不少开发同事提交代码没有自测,直接失败的。
再补充一下页面部署工具,在白天大家的测试过程中,会需要部署最新的代码,所以我们提供了页面给到大家用。
def delopy(projectid,branch,env,flow): output = '' updatecmd = 'sh updaterepo.sh ' + branch replacecmd = ' sh replace.sh ' + env + ' ' + flow status1,output1 = execute_cmd(updatecmd) status2,output2 = execute_cmd(replacecmd) output = output1 + output2 if status1 == 0 and status2 == 0: delopyresult = 'PASS' else: delopyresult = 'FAIL' return delopyresult,output |
相关阅读:
- 大数据测试之Hive和Hbase的区别 (大椿菜, 2021-1-06)
- 从功能测试的角度谈一谈大数据测试 (大椿菜, 2021-1-06)
- ETL测试工具和面试常见的问题及答案 (大椿菜, 2021-1-06)
- ETL测试或数据仓库测试入门 (大椿菜, 2021-1-06)
- 大数据测试,可以怎么测? (大椿菜, 2021-1-07)
标题搜索
日历
|
|||||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 | |||
| 1 | 2 | 3 | 4 | 5 | 6 | ||||
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | |||
| 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | |||
| 28 | 29 | 30 | |||||||
我的存档
数据统计
- 访问量: 72567
- 日志数: 97
- 建立时间: 2020-08-11
- 更新时间: 2023-10-23
