

1. 问题
虽然scrapy能够完美且快速的抓取静态页面,但是在现实中,目前绝大多数网站的页面都是动态页面,动态页面中的部分内容是浏览器运行页面中的JavaScript脚本动态生成的,爬取相对困难;
比如你信心满满的写好了一个爬虫,写好了目标内容的选择器,一跑起来发现根本找不到这个元素,当时肯定一万个黑人问号。
于是你在浏览器里打开F12,一顿操作,发现原来这你妹的是ajax加载的,不然就是硬编码在js代码里的,blabla的…
然后你得去调ajax的接口,然后解析json啊,转成python字典啊,然后才能拿到你想要的东西
妹的就不能对我们这些小爬爬友好一点吗?
于是大家伙肯定想过,“为啥不能浏览器看到是咋样的html页面,我们爬虫得到的也是同样的html页面呢? 要是可以,那得多么美滋滋啊”。
2. 解决方案
既然是想要得到和浏览器一模一样的html页面,那我们就先用浏览器渲染一波目标网页,然后再将浏览器渲染后的html拿给scrapy进行进一步解析不就好了吗。
2.1 获取浏览器渲染后的html
有了思路,肯定是网上搜一波然后开干啊,搜python操作浏览器的库啊
货比三家之后,找到了selenium这货。
| selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。 |
卧槽,这就是我们要的东西啦!
先试一波看看效果如何,目标网址http://quotes.toscrape.com/js/
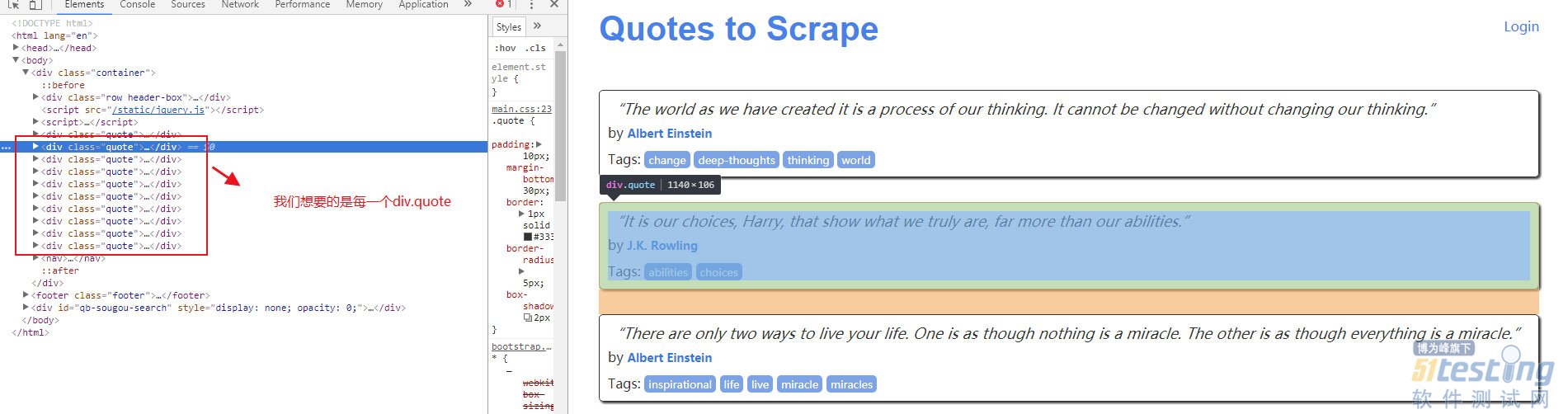
别着急,先来看一下网页源码:

我们想要的div.quote被硬编码在js代码中,用selenium试一下看能不能获取到浏览器渲染后的html。
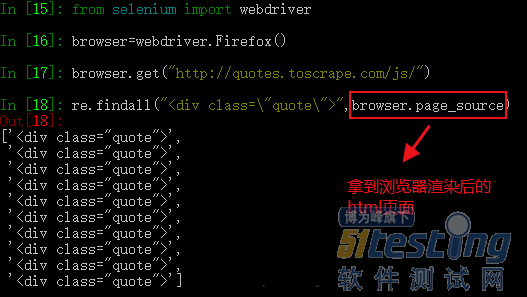
from selenium import webdriver # 控制火狐浏览器 browser = webdriver.Firefox() # 访问我们的目标网址 browser.get("http://quotes.toscrape.com/js/") # 获取渲染后的html页面 html = browser.page_source |
perfect,到这里我们已经顺利拿到浏览器渲染后的html了,selenium大法好啊?
2.2 通过下载器中间件返回渲染过后html的Response
这里先放一张scrapy的流程图:
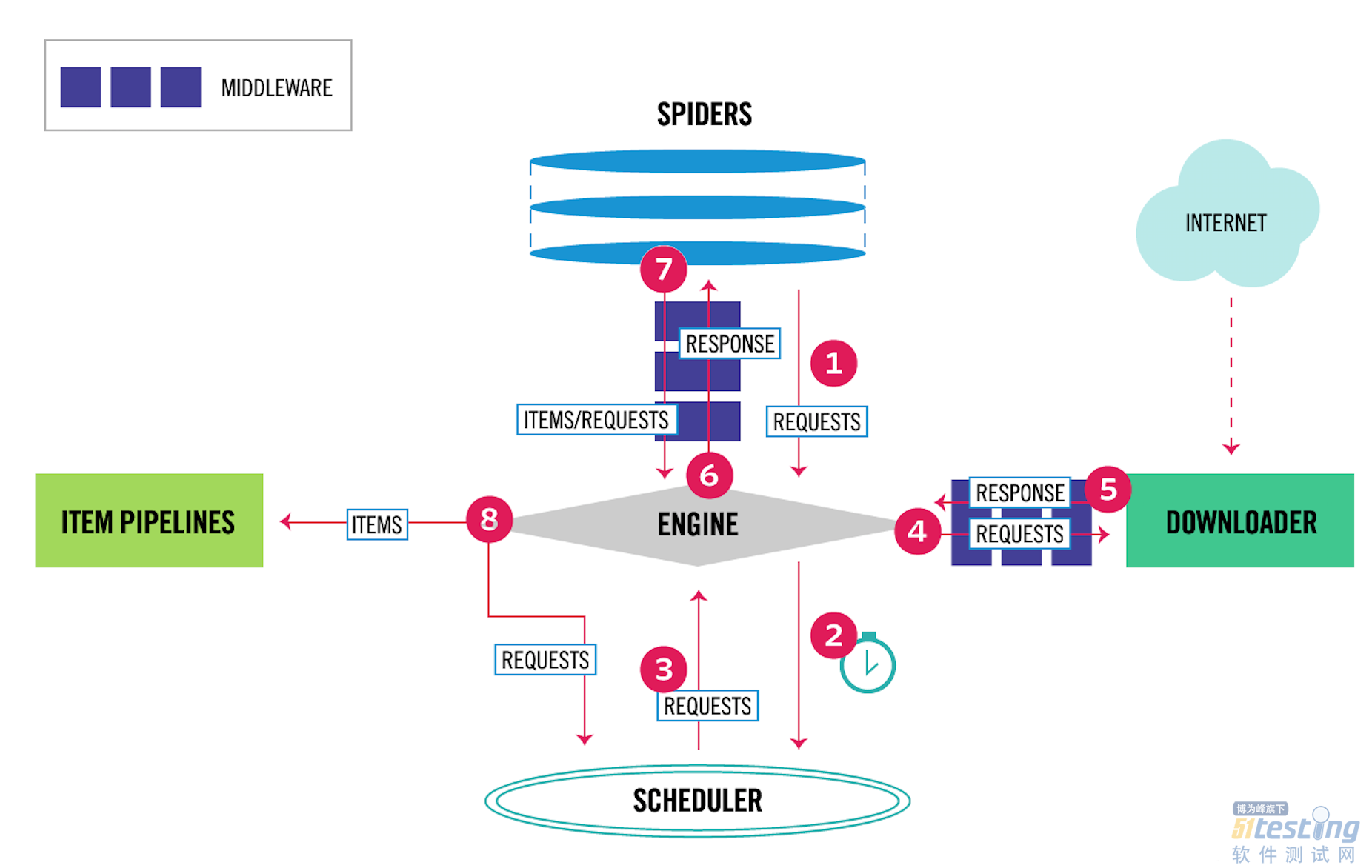
所以我们只需要在scrapy下载网页(downloader下载好网页,构造Response返回)之前,通过下载器中间件返回我们自己<通过渲染后html构造的Response>不就可以了吗?
道理我都懂,关键是在哪一步使用浏览器呢?
分析:
(1)我们的scrapy可能是有很多个爬虫的,有些爬虫处理的是纯纯的静态页面,而有些是处理的纯纯的动态页面,又有些是动静态结合的页面(有可能列表页是静态的,正文页是动态的),如果把<浏览器调用代码>放在下载器中间件中,那么除非特别区分哪些爬虫需要selenium,否则每一个爬虫都用selenium去下载解析页面的话,实在是太浪费资源了,就相当于杀鸡用牛刀了,所以得出结论,<浏览器调用代码>应该是放置于Spider类中更好一点;
(2)如果放置于Spider类中,就意味着一个爬虫占用一个浏览器的一个tab页,如果这个爬虫里的某些Request需要selenium,而某些不需要呢? 所以我们还要在区分一下Request;
结论:
SeleniumDownloaderMiddleware(selenium专用下载器中间件):负责返回浏览器渲染后的Response。
SeleniumSpider(selenium专用Spider):一个spider开一个浏览器。
SeleniumRequest:只是继承一下scrapy.Request,然后pass,好区分哪些Request需要启用selenium进行解析页面,相当于改个名。
3. 撸代码,盘他
3.1 自定义Request
#!usr/bin/env python # -*- coding:utf-8 _*- """ @author:Joshua @description: 只是继承一下scrapy.Request,然后pass,好区分哪些Request需要启用selenium进行解析页面,相当于改个名 """ import scrapy class SeleniumRequest(scrapy.Request): """ selenium专用Request类 """ pass |
3.2 自定义Spider
#!usr/bin/env python # -*- coding:utf-8 _*- """ @author:Joshua @description: 一个spider开一个浏览器 """ import logging import scrapy from selenium import webdriver class SeleniumSpider(scrapy.Spider): """ Selenium专用spider 一个spider开一个浏览器 浏览器驱动下载地址:http://www.cnblogs.com/qiezizi/p/8632058.html """ # 浏览器是否设置无头模式,仅测试时可以为False SetHeadless = True # 是否允许浏览器使用cookies EnableBrowserCookies = True def __init__(self, *args, **kwargs): super(SeleniumSpider, self).__init__(*args, **kwargs) # 获取浏览器操控权 self.browser = self._get_browser() def _get_browser(self): """ 返回浏览器实例 """ # 设置selenium与urllib3的logger的日志等级为ERROR # 如果不加这一步,运行爬虫过程中将会产生一大堆无用输出 logging.getLogger('selenium').setLevel('ERROR') logging.getLogger('urllib3').setLevel('ERROR') # selenium已经放弃了PhantomJS,开始支持firefox与chrome的无头模式 return self._use_firefox() def _use_firefox(self): """ 使用selenium操作火狐浏览器 """ profile = webdriver.FirefoxProfile() options = webdriver.FirefoxOptions() # 下面一系列禁用操作是为了减少selenium的资源耗用,加速scrapy # 禁用图片 profile.set_preference('permissions.default.image', 2) profile.set_preference('browser.migration.version', 9001) # 禁用css profile.set_preference('permissions.default.stylesheet', 2) # 禁用flash profile.set_preference('dom.ipc.plugins.enabled.libflashplayer.so', 'false') # 如果EnableBrowserCookies的值设为False,那么禁用cookies if hasattr(self, "EnableBrowserCookies") and self.EnableBrowserCookies: # ?值1 - 阻止所有第三方cookie。 # ?值2 - 阻止所有cookie。 # ?值3 - 阻止来自未访问网站的cookie。 # ?值4 - 新的Cookie Jar策略(阻止对跟踪器的存储访问) profile.set_preference("network.cookie.cookieBehavior", 2) # 默认是无头模式,意思是浏览器将会在后台运行,也是为了加速scrapy # 我们可不想跑着爬虫时,旁边还显示着浏览器访问的页面 # 调试的时候可以把SetHeadless设为False,看一下跑着爬虫时候,浏览器在干什么 if self.SetHeadless: # 无头模式,无UI options.add_argument('-headless') # 禁用gpu加速 options.add_argument('--disable-gpu') return webdriver.Firefox(firefox_profile=profile, options=options) def selenium_func(self, request): """ 在返回浏览器渲染的html前做一些事情 1.比如等待浏览器页面中的某个元素出现后,再返回渲染后的html; 2.比如将页面切换进iframe中的页面; 在需要使用的子类中要重写该方法,并利用self.browser操作浏览器 """ pass def closed(self, reason): # 在爬虫关闭后,关闭浏览器的所有tab页,并关闭浏览器 self.browser.quit() # 日志记录一下 self.logger.info("selenium已关闭浏览器...") |
之所以不把获取浏览器的具体代码写在__init__方法里,是因为笔者之前写的代码里考虑过。
1.两种浏览器的调用(支持firefox与chrome),虽然后来感觉还是firefox比较方便,因为所有版本的火狐浏览器的驱动都是一样的,但是谷歌浏览器是不同版本的浏览器必须用不同版本的驱动(坑爹啊- -’’)。
2.自动区分不同的操作系统并选择对应操作系统的浏览器驱动。
额… 所以上面spider的代码是精简过的版本。
备注: 针对selenium做了一系列的优化加速,启用了无头模式,禁用了css、flash、图片、gpu加速等… 因为爬虫嘛,肯定是跑的越快越好啦?
3.3 自定义下载器中间件
#!usr/bin/env python # -*- coding:utf-8 _*- """ @author:Joshua @description: 负责返回浏览器渲染后的Response """ import hashlib import time from scrapy.http import HtmlResponse from twisted.internet import defer, threads from tender_scrapy.extendsion.selenium.spider import SeleniumSpider from tender_scrapy.extendsion.selenium.requests import SeleniumRequest class SeleniumDownloaderMiddleware(object): """ Selenium下载器中间件 """ def process_request(self, request, spider): # 如果spider为SeleniumSpider的实例,并且request为SeleniumRequest的实例 # 那么该Request就认定为需要启用selenium来进行渲染html if isinstance(spider, SeleniumSpider) and isinstance(request, SeleniumRequest): # 控制浏览器打开目标链接 browser.get(request.url) # 在构造渲染后的HtmlResponse之前,做一些事情 #1.比如等待浏览器页面中的某个元素出现后,再返回渲染后的html; #2.比如将页面切换进iframe中的页面; spider.selenium_func(request) # 获取浏览器渲染后的html html = browser.page_source # 构造Response # 这个Response将会被你的爬虫进一步处理 return HtmlResponse(url=browser.current_url, request=request, body=html.encode(), encoding="utf-8") |
这里要说一下下载器中间件的process_request方法,当每个request通过下载中间件时,该方法被调用。
1.process_request() 必须返回其中之一: 返回 None 、返回一个 Response 对象、返回一个 Request 对象或raise IgnoreRequest 。
2.如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
3.4 额外的工具
眼尖的读者可能注意到SeleniumSpider类里有个selenium_func方法,并且在SeleniumDownloaderMiddleware的process_request方法返回Resposne之前调用了spider的selenium_func方法。
这样做的好处是,我们可以在构造渲染后的HtmlResponse之前,做一些事情(比如…那种…很骚的那种…你懂的)。
比如等待浏览器页面中的某个元素出现后,再返回渲染后的html;
比如将页面切换进iframe中的页面,然后返回iframe里面的html(够骚吗);
等待某个元素出现,然后再返回渲染后的html这种操作很常见的,比如你访问一篇文章,它的正文是ajax加载然后js添加到html里的,ajax是需要时间的,但是selenium并不会等待所有请求都完毕后再返回。
解决方法:
1.您可以通过browser.implicitly_wait(30),来强制selenium等待30秒(无论元素是否加载出来,都必须等待30秒)
2.可以通过等待,直到某个元素出现,然后再返回html
所以笔者对<等待某个元素出现>这一功能做了进一步的封装,代码如下:
#!usr/bin/env python # -*- coding:utf-8 _*- """ @author:Joshua @description: """ import functools from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC def waitFor(browser, select_arg, select_method, timeout=2): """ 阻塞等待某个元素的出现直到timeout结束 :param browser:浏览器实例 :param select_method:所使用的选择器方法 :param select_arg:选择器参数 :param timeout:超时时间 :return: """ element = WebDriverWait(browser, timeout).until( EC.presence_of_element_located((select_method, select_arg)) ) # 用xpath选择器等待元素 waitForXpath = functools.partial(waitFor, select_method=By.XPATH) # 用css选择器等待元素 waitForCss = functools.partial(waitFor, select_method=By.CSS_SELECTOR) |
waitForXpath与waitForCss 是waitFor函数的两个偏函数,意思这两个偏函数是设置了select_method参数默认值的waitFor函数,分别应用不同的选择器来定位元素。
4. 中间件当然要在settings中激活一下

在我们scrapy项目的settings文件中的DOWNLOADER_MIDDLEWARES字典中添加到适当的位置即可
5. 使用示例
5.1一个完整的爬虫示例
# -*- coding: utf-8 -*- """ @author:Joshua @description: 整合selenium的爬虫示例 """ import scrapy from my_project.requests import SeleniumRequest from my_project.spider import SeleniumSpider from my_project.tools import waitForXpath # 这个爬虫类继承了SeleniumSpider # 在爬虫跑起来的时候,将启动一个浏览器 class SeleniumExampleSpider(SeleniumSpider): """ 这一网站,他的列表页是静态的,但是内容页是动态的 所以,用selenium试一下,目标是扣出内容页的#content """ name = 'selenium_example' allowed_domains = ['pingdingshan.hngp.gov.cn'] url_format = 'http://pingdingshan.hngp.gov.cn/pingdingshan/ggcx?appCode=H65&channelCode=0301&bz=0&pageSize=20&pageNo={page_num}' def start_requests(self): """ 开始发起请求,记录页码 """ start_url = self.url_format.format(page_num=1) meta = dict(page_num=1) # 列表页是静态的,所以不需要启用selenium,用普通的scrapy.Request就可以了 yield scrapy.Request(start_url, meta=meta, callback=self.parse) def parse(self, response): """ 从列表页解析出正文的url """ meta = response.meta all_li = response.css("div.List2>ul>li") # 列表 for li in all_li: content_href = li.xpath('./a/@href').extract() content_url = response.urljoin(content_href) # 内容页是动态的,#content是ajax动态加载的,所以启用一波selenium yield SeleniumRequest(url=content_url, meta=meta, callback=self.parse_content) # 翻页 meta['page_num'] += 1 next_url = self.url_format.format(page_num=meta['page_num']) # 列表页是静态的,所以不需要启用selenium,用普通的scrapy.Request就可以了 yield scrapy.Request(url=next_url, meta=meta, callback=self.parse) def parse_content(self, response): """ 解析正文内容 """ content = response.css('#content').extract_first() yield dict(content=content) def selenium_func(self, request): # 这个方法会在我们的下载器中间件返回Response之前被调用 # 等待content内容加载成功后,再继续 # 这样的话,我们就能在parse_content方法里应用选择器扣出#content了 waitForXpath(self.browser, "//*[@id='content']/*[1]") |
5.2 更骚一点的操作…
假如内容页的目标信息处于iframe中,我们可以将窗口切换进目标iframe里面,然后返回iframe的html
要实现这样的操作,只需要重写一下SeleniumSpider子类中的selenium_func方法
要注意到SeleniumSpider中的selenium_func其实是啥也没做的,一个pass,所有的功能都在子类中重写
def selenium_func(self, request): # 找到id为myPanel的iframe target = self.browser.find_element_by_xpath("//iframe[@id='myPanel']") # 将浏览器的窗口切换进该iframe中 # 那么切换后的self.browser的page_source将会是iframe的html self.browser.switch_to.frame(target) |
6. scrapy整合selenium的一些缺点
1)selenium是阻塞的,所以速度会慢些。
2)对于一些稍微简单的动态页面,最好还是自己去解析一下接口,不要太过依赖selenium,因为selenium带来便利的同时,是更多资源的占用。
3)整合selenium的scrapy项目不宜大规模的爬取,比如你在自己的机子上写好了一个一个的爬虫,跑起来也没毛病,速度也能接受,然后你很开心地在服务器上部署了你项目上的100+个爬虫(里面有50%左右的爬虫启用了selenium),当他们跑起来的时候,服务器就原地爆炸了… 为啥? 因为相当于服务器同时开了50多个浏览器在跑,内存顶不住啊(土豪忽略…)。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












