ΓΓΓΓΓΨΧβΡΩΓΩ
ΓΓΓΓΙΪΥΨΒΡappΘ®άύΥΤΒΈΒΈΓΔuberΘ©ΈΣ”ΟΜßΧαΙ©¥ρ≥ΒΖΰΈώΓΘœ÷”–ΥΡ’≈±μΘ§Ζ÷±π «ΓΑΥΨΜζ ΐΨίΓ±±μΘ§ΓΑΕ©ΒΞ ΐΨίΓ±±μΘ§ΓΑ‘ΎœΏ ±≥Λ ΐΨίΓ±±μΘ§ΓΑ≥« –ΤΞ≈δ ΐΨίΓ±±μΓΘΘ®ΒΈΒΈΟφ ‘ΧβΘ©
ΓΓΓΓœ¬ΆΦΉσ±μ «ΓΑΥΨΜζ ΐΨίΓ±±μΒΡ≤ΩΖ÷ ΐΨίΓΘΈΣΝΥ±ψ”ΎΫ≤ΫβΘ§÷°Κσ‘Ύ…φΦΑΒΫ±μΒΡ ±ΚρΘ§”Οœ¬ΆΦ”“±μά¥¥ζΧφΓΘ”“±μ÷–’Ι ΨΝΥΉσ±μΒΡ≤ΩΖ÷¥ζ±μ–‘ ΐΨίΓΘ
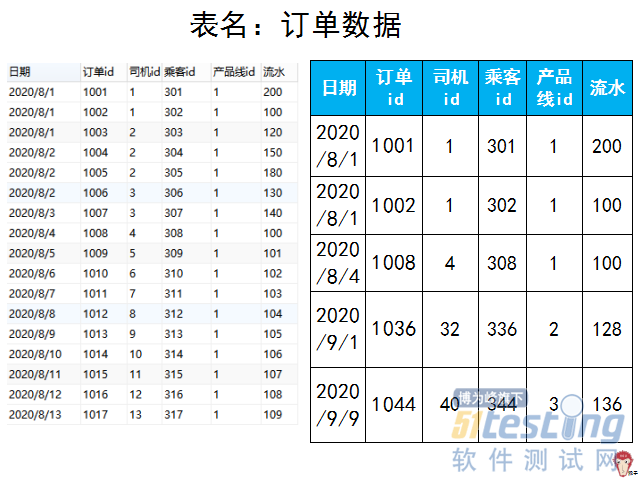
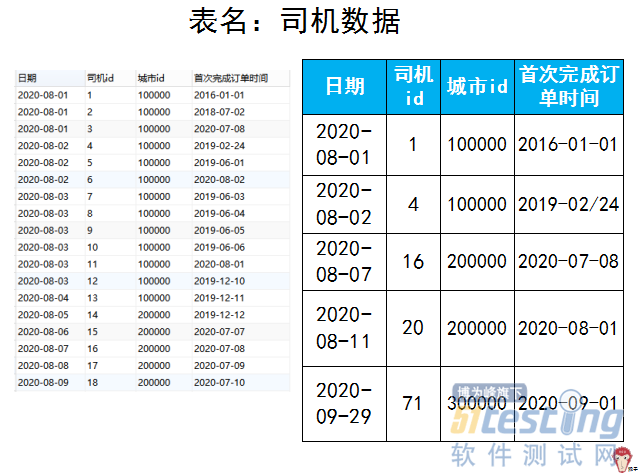
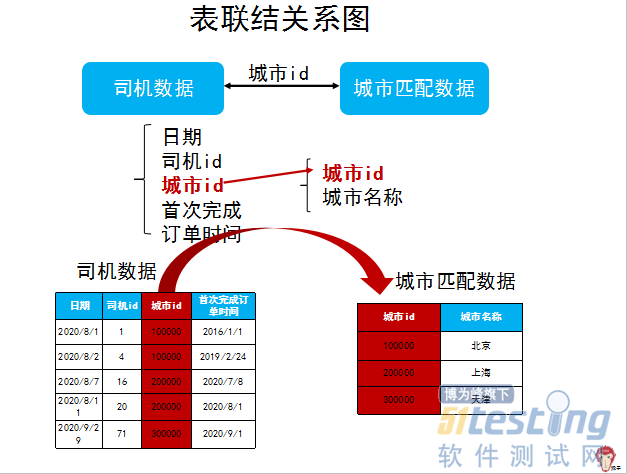
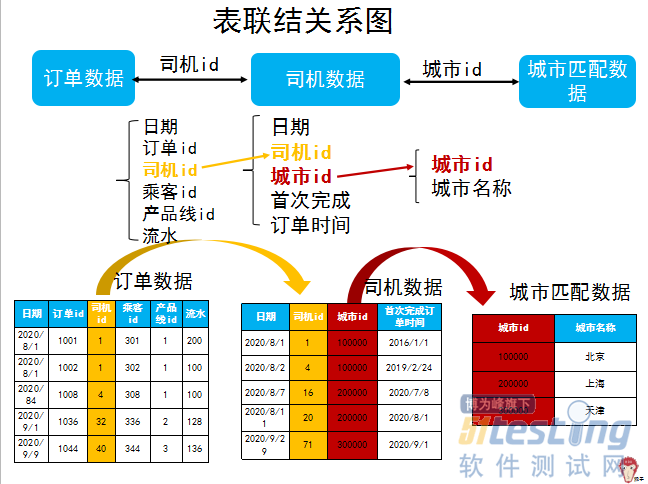
ΓΓΓΓ…œ±μ÷–ΒΡΓΑ≤ζΤΖœΏidΓ±:1 «±μ ΨΉ®≥ΒΘ§2±μ ΨΤσ“ΒΘ§3±μ ΨΩλ≥ΒΘ§4±μ ΨΤσ“ΒΩλ≥Β
ΓΓΓÓ¸ώΈ Χβ
ΓΓΓΓ1. Ζ÷Έω≥ω2020Ρξ8‘¬Ης≥« –ΟΩΧλΒΡΥΨΜζ ΐΓΔΩλ≥ΒΕ©ΒΞΝΩΚΆΩλ≥ΒΝςΥ° ΐΨίΓΘ
ΓΓΓΓΓΨΫβΧβΥΦ¬ΖΓΩ
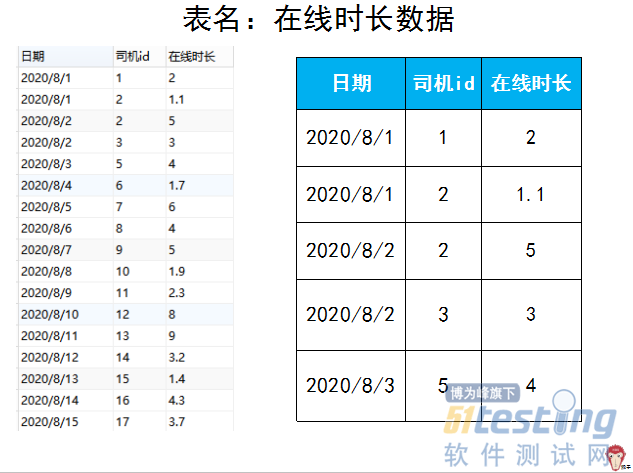
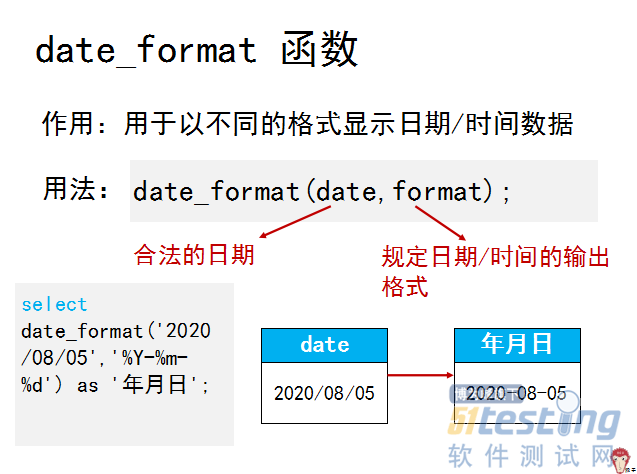
ΓΓΓΓΈΣΝΥΖΫ±ψ ΐΨί¥ΠάμΘ§ Ήœ»ΫΪ’β–©±μ÷–Υυ”–ΒΡ»’ΤΎ ΐΨίΉΣΜ·ΈΣ»’ΤΎΗώ ΫΓ°Ρξ-‘¬-»’Γ· ΒΡ–Έ ΫΓΘ–η“Σ Ι”Οdate_fromat Κ· ΐΓΘ
ΓΓΓΓsql”οΨδΈΣ
ΓΓΓΓupdateΥΨΜζ ΐΨί
ΓΓΓΓset»’ΤΎ=date_format(»’ΤΎ,'%Y-%m-%d');
ΓΓΓΓupdate ΥΨΜζ ΐΨί
ΓΓΓΓset Ή¥ΈΆξ≥…Ε©ΒΞ ±Φδ=date_format( Ή¥ΈΆξ≥…Ε©ΒΞ ±Φδ,'%Y-%m-%d');
ΓΓΓΓupdate Ε©ΒΞ ΐΨί
ΓΓΓΓset »’ΤΎ=date_format(»’ΤΎ,'%Y-%m-%d');
ΓΓΓΓupdate ‘ΎœΏ ±≥Λ ΐΨί
ΓΓΓΓset»’ΤΎ=date_format(»’ΤΎ,'%Y-%m-%d');
ΓΓΓΓ¥ΠάμΚσΒΡ±μ»γœ¬ΆΦΘ§Ω…“‘ΖΔœ÷Ε‘”Π»’ΤΎΝ–“―Ψ≠–όΗΡΙΐά¥ΝΥΓΘ
ΓΓΓΓΫ”œ¬ά¥Ω¥–η“ΣΖ÷ΈωΒΡ“ΒΈώΈ ΧβΓΘ
ΓΓΓΓ1. Χα»Γ2020Ρξ8‘¬Ης≥« –ΟΩΧλΒΡΥΨΜζ ΐΓΔΩλ≥ΒΕ©ΒΞΝΩΚΆΩλ≥ΒΝςΥ° ΐΨίΓΘ
ΓΓΓΓ(1)2020Ρξ8‘¬Ης≥« –ΟΩΧλΒΡΥΨΜζ ΐ
ΓΓΓΓ Ι”Ο¬ΏΦ≠ ςΖ÷ΈωΖΫΖ®Θ§≤πΫβ“ΒΈώ–η«σΒΡΟΩΗω≤ΩΖ÷ΓΘ
ΓΓΓΓΓΑ2020Ρξ8‘¬Γ±Θ§Ω…“‘”Ο between and Κ· ΐά¥Ε‘ ±ΦδΫχ––ΧθΦΰœό÷ΤΓΘ
ΓΓΓΓΓΑΟΩΧλΒΡΥΨΜζ ΐΓ±Θ§ΥΨΜζ ΐΒΡΦΤΥψ”ΟΒΫΒΡ±μ «ΓΑΥΨΜζ ΐΨίΓ± ±μΓΘΒ±≥ωœ÷ΓΑΟΩΧλΓ±“ΣœκΒΫΓΕΚοΉ” ¥”Νψ―ßΜαsqlΓΖάοΫ≤ΙΐΒΡΖ÷ΉιΜψΉήΘ§ά¥ΫβΨωΓΑΟΩΧλΓ±’β―υΒΡΈ ΧβΓΘ”ΟΓΑ»’ΤΎΓΑά¥Ζ÷ΉιΘ®group byΘ©Θ§”Ο count(ΥΨΜζid) ά¥ΜψΉήΥΨΜζ ΐΓΘ
ΓΓΓΓΓΑΗς≥« –Γ±Θ§≥« –‘ΎΓΑ≥« –ΤΞ≈δ ΐΨίΓΑ±μ÷–ΓΘ“≤ΨΆ «ΓΑΟΩΗω≥« –Γ±Υυ“‘”ΟΓΑ≥« –ΓΑά¥Ζ÷ΉιΘ®group byΘ©ΓΘ
ΓΓΓΓ’βάο…φΦΑΒΫΝΫΗω±μΓΑΥΨΜζ ΐΨίΓ± ±μΚΆΓΑ≥« –ΤΞ≈δ ΐΨίΓΑ±μΘ§Υυ“‘”ωΒΫΕύ±μ≤ι―·ΒΡ«ιΩωΘ§“ΣœκΒΫΓΕΚοΉ” ¥”Νψ―ßΜαsqlΓΖάοΫ≤ΙΐΒΡΕύ±μΝΣΫαΓΘœ¬ΆΦ «ΝΫ±μΝΣΫαΒΡΧθΦΰΘ®Ά®Ιΐ≥« –idΝΣΫαΘ©ΓΘ
ΓΓΓΓ Ι”ΟΡΡ÷÷ΝΣΫαΡΊΘΩ
ΓΓΓΓ“ρΈΣ“Σ≤ι―·ΒΡ «ΥΨΜζ ΐΘ§Υυ“‘“Σ±ΘΝτΓΑΥΨΜζ ΐΨίΓ±±μ÷–ΒΡ»Ϊ≤Ω ΐΨίΘ§“ρ¥Υ Ι”ΟΉσΝΣΫαΓΘ
ΓΓΓΓsql”οΨδ»γœ¬
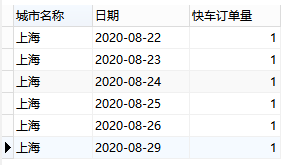
ΓΓΓΓ≤ι―·ΫαΙϊ»γœ¬ΆΦ(≤ΩΖ÷’Ι Ψ)
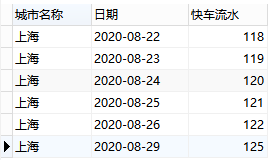
ΓΓΓΓ(2)2020Ρξ8‘¬Ης≥« –ΟΩΧλΒΡΩλ≥ΒΕ©ΒΞΝΩ
ΓΓΓΓΓΑ2020Ρξ8‘¬Γ±Θ§Ω…“‘”Ο between and Κ· ΐά¥Ε‘ ±ΦδΫχ––ΧθΦΰœό÷ΤΓΘ
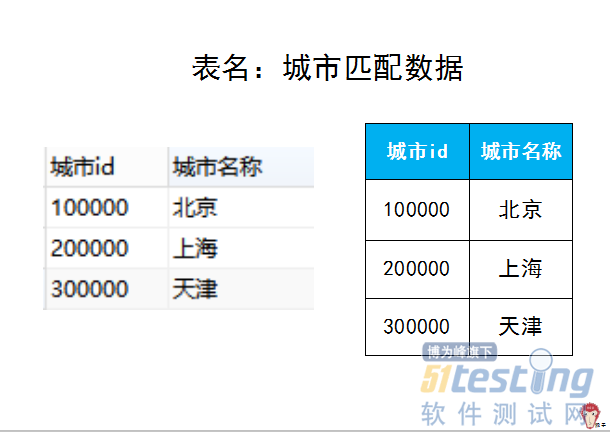
ΓΓΓΓΓΑΟΩΧλΒΡΩλ≥ΒΕ©ΒΞΝΩΓ±Θ§Ε‘”ΎΦΤΥψΩλ≥ΒΕ©ΒΞΝΩΘ§”ΟΒΫΒΡ±μ «ΓΑΕ©ΒΞ ΐΨίΓ± ±μΓΘΗυΨίΧβΡΩΒΡΉ÷ΕΈΫβ ΆΘ§ΓΑ≤ζΤΖœΏidΓ±: 1 «±μ ΨΉ®≥ΒΘ§2±μ ΨΤσ“ΒΘ§3±μ ΨΩλ≥ΒΘ§4±μ ΨΤσ“ΒΩλ≥ΒΓΘΩ…“‘”ΟwhereΉ”ΨδΑ―Ωλ≥Β ΐΨίœ»…Η―Γ≥ωά¥Θ®≤ζΤΖœΏid=3Θ©ΓΘ
ΓΓΓΓΒ±≥ωœ÷ΓΑΟΩΧλΓ±“ΣœκΒΫΓΕΚοΉ” ¥”Νψ―ßΜαsqlΓΖάοΫ≤ΙΐΒΡΖ÷ΉιΜψΉήΘ§ά¥ΫβΨωΓΑΟΩΧλΓ±’β―υΒΡΈ ΧβΓΘ”ΟΓΑ»’ΤΎΓΑά¥Ζ÷ΉιΘ®group byΘ©Θ§”Ο count(Ε©ΒΞid) ά¥ΜψΉήΕ©ΒΞΝΩΓΘ
ΓΓΓΓΓΑΗς≥« –Γ±Θ§≥« –‘ΎΓΑ≥« –ΤΞ≈δ ΐΨίΓΑ±μ÷–ΓΘ“≤ΨΆ «ΓΑΟΩΗω≥« –Γ±Υυ“‘”ΟΓΑ≥« –ΓΑά¥Ζ÷ΉιΘ®group byΘ©ΓΘ
ΓΓΓΓ‘ΎΓΑΕ©ΒΞ ΐΨίΓ± ±μΓΔΓΑΥΨΜζ ΐΨίΓ±±μ÷–ΕΦΟΜ”–≥« – ΐΨίΘ§Υυ“‘–η“Σ»ΐ±μΝΣΫαΘ§œ¬Οφ «3±μΒΡΙΊœΒΆΦΓΘ
ΓΓΓΓ Ι”ΟΡΡ÷÷ΝΣΫαΡΊΘΩ
ΓΓΓΓ“ρΈΣ“Σ≤ι―·ΒΡ «Ωλ≥ΒΕ©ΒΞΝΩΘ§Υυ“‘“Σ±ΘΝτΓΑΕ©ΒΞ ΐΨίΓ±±μ÷–ΒΡ»Ϊ≤Ω ΐΨίΘ§“ρ¥Υ Ι”ΟΉσΝΣΫαά¥”κΓΑΥΨΜζ ΐΨίΓ±Ϋχ––ΝΣΫαΘ®ΝΣΫα“άΨίΈΣΓΑΥΨΜζidΓ±Θ©ΓΘ»ΜΚσΘ§“ρΈΣ“ΣΕ‘ΒΎ“Μ¥ΈΝΣΫαΚσΒΡ±μΒΡΓΑ≥« –idΓ±”κΓΑ≥« –Οϊ≥ΤΓ±Ϋχ––ΤΞ≈δΘ§Υυ“‘Έ“Ο«”ΟΉσΝΣΫαά¥Ϋχ––ΤΞ≈δΓΘ
ΓΓΓΓsql”οΨδ»γœ¬
ΓΓΓΓ≤ι―·ΫαΙϊ»γœ¬ΆΦ