


如果数据有一点点就不错了,那么数据是海量的话就一定棒极了,对不对?这就好比说, 如果一个炎日夏日里的微风让你感觉凉爽,那么你会为一阵一阵的凉风感到欣喜若狂。以下为译文:
为了确保你组织的大数据计划保持正轨,你需要消除以下10种常见的误解。
1. 大数据就是‘很多数据’
大数据从其核心来讲,它描述了结构化或非结构化数据如何结合社交媒体分析,物联网的数据和其他外部来源,来讲述一个”更大的故事”。该故事可能是一个组织运营的宏观描述,或者是无法用传统的分析方法捕获的大局观。从情报收集的角度来看,其所涉及的数据的大小是微不足道的。
2.大数据必须非常干净
在商业分析的世界里,没有“太快”之类的东西。相反,在IT世界里,没有“进垃圾,出金子”这样的东西,你的数据有多干净?一种方法是运行你的分析应用程序,它可以识别数据集中的弱点。一旦这些弱点得到解决,再次运行分析以突出 “清理过的” 区域。
3.所有人类分析人员会被机器算法取代
数据科学家的建议并不总是被前线的业务经理们执行。行业高管Arijit Sengupta在 TechRepublic 的一篇文章中指出,这些建议往往比科学项目更难实施。然而,过分依赖机器学习算法也同样具有挑战性。Sengupta说,机器算法告诉你该怎么做,但它们没有解释你为什么要这么做。这使得很难将数据分析与公司战略规划的其余部分结合起来。

预测算法的范围从相对简单的线性算法到更复杂的基于树的算法,最后是极其复杂的神经网络。
来源:dataiku, dataconomy 。
4.数据湖是必须的
据丰田研究所数据科学家Jim Adler说,巨量存储库,一些IT经理们设想用它来存储大量结构化和非结构化数据,根本就不存在。企业机构不会不加区分地将所有数据存放到一个共享池中。Adler说,这些数据是 “精心规划”的,存储于独立的部门数据库中,鼓励”专注的专业知识”。这是实现合规和其他治理要求所需的透明度和问责制的唯一途径。
5.算法是万无一失的预言家
不久前, 谷歌流感趋势项目 被大肆炒作,声称比美国疾病控制中心和其他健康信息服务机构更快、更准确地预测流感疫情的发生地。正如《纽约客》的Michele Nijhuis 在 2017年6月3日的文章 中所写的那样, 人们认为与流感有关词语的搜索会准确地预测疫情即将爆发的地区。事实上,简单地绘制本地温度是一个更准确的预测方法。
谷歌的流感预测算法陷入了一个常见的大数据陷阱——它产生了无意义的相关性,比如将高中篮球比赛和流感爆发联系起来,因为两者都发生在冬季。当数据挖掘在一组海量数据上运行时,它更可能发现具有统计意义而非实际意义的信息之间的关系。一个例子是将缅因州的离婚率与美国人均人造黄油的消费量挂钩:尽管没有任何现实意义,但这两个数字之间确实存在“统计上显著”的关系。
6.你不能在虚拟化基础架构上运行大数据应用
大约10年前,当”大数据”首次出现在人们眼前时,它就是Apache hadoop的代名词。就像VMware的Justin Murray在 2017年5月12日的文章 中所写的,大数据这一术语现在包括一系列技术,从NoSQL(MongoDB,Apache Cassandra)到Apache Spark。
此前,批评者们质疑Hadoop在虚拟机上的性能,但Murray指出,Hadoop在虚拟机上的性能与物理机相当,而且它能更有效地利用集群资源。Murray还炮轰了一种误解,即认为虚拟机的基本特性需要存储区域网络(SAN)。实际上,供应商们经常推荐直接连接存储,这提供了更好的性能和更低的成本。
7.机器学习是人工智能的同义词
一个识别大量数据中模式的算法和一个能够根据数据模式得出逻辑结论的方法之间的差距更像是一个鸿沟。ITProPortal 的Vineet Jain在 2017年5月26日的文章 中写道,机器学习使用统计解释来生成预测模型。这是算法背后的技术,它可以根据一个人过去的购买记录来预测他可能购买什么,或者根据他们的听歌历史来预测他们喜欢的音乐。
虽然这些算法很聪明,但它们远远不能达到人工智能的目的,即复制人类的决策过程。基于统计的预测缺乏人类的推理、判断和想象力。从这个意义上说,机器学习可能被认为是真正AI的必要先导。即使是迄今为止最复杂的AI 系统,比如 IBM沃森 ,也无法提供人类数据科学家所提供的大数据的洞察力。
8.大多数大数据项目至少实现了一半的目标
IT经理们知道没有数据分析项目是100%成功的。当这些项目涉及大数据时,成功率就会直线下降,NewVantage Partners最近的调查结果显示了这一点。在过去的五年中,95%的企业领导人表示,他们的公司参与了一个大数据项目,但只有48.4%的项目取得了”可衡量的结果”。
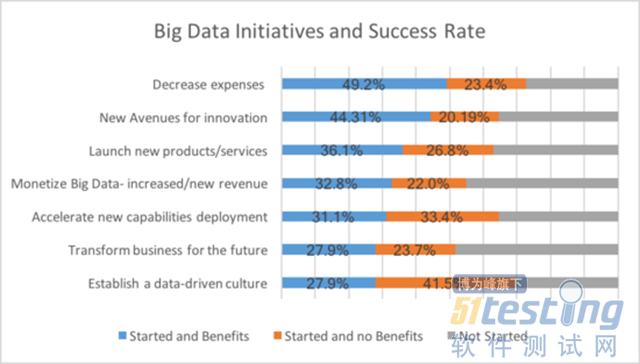
NewVantage Partners的大数据执行调查显示, 只有不到一半的大数据项目实现了目标,而 “文化”变化是最难实现的。资料来源: Data Informed 。
事实上,根据2016年10月发布的 Gartner的研究结果 ,大数据项目很少能跨过试验阶段。Gartner的调查发现,只有15%的大数据实现被部署到生产中,与去年调查报告的14%的成功率相对持平。
9.大数据的增长将减少对数据工程师的需求
如果你公司大数据计划的目标是尽量减少对数据科学家的需求,你可能会得到令人不快的惊喜。 2017 Robert Half 技术薪资指南 指出, 数据工程师的年薪平均跃升到13万美元和19.6万美元之间, 而数据科学家的薪资目前平均在11.6万美元和16.3万美元之间, 而商业情报分析员的薪资目前平均在11.8万美元到13.875万美元之间。
10.员工和一线经理将张开双臂拥抱大数据
NewVantage Partners的调查发现,85.5%的公司都致力于创造一个“数据驱动的文化”。然而,新的数据计划的整体成功率仅为37.1%。这些公司最常提到的三个障碍是缺乏组织一致性(42.6%),缺乏中层管理人员的采纳和理解(41%),以及业务阻力或缺乏理解(41%)。
未来可能属于大数据,但获得这一技术的好处需要大量的针对多样人性的老式辛勤工作。
End.












