

解Bug之路-TCP粘包Bug
笔者很热衷于解决Bug,同时比较擅长(网络/协议)部分,所以经常被唤去解决一些网络IO方面的Bug。现在就挑一个案例出来,写出分析思路,以飨读者,希望读者在以后的工作中能够少踩点坑。
TCP粘包Bug
Bug现场
出Bug的系统是做与外部系统进行对接之用。这两者并不通过http协议进行交互,而是在通过TCP协议之上封装一层自己的报文进行通讯。如下图示:

通过监控还发现,此系统的业务量出现了不正常的飙升,大概有4倍的增长。而且在监控看来,这些业务还是成功的。
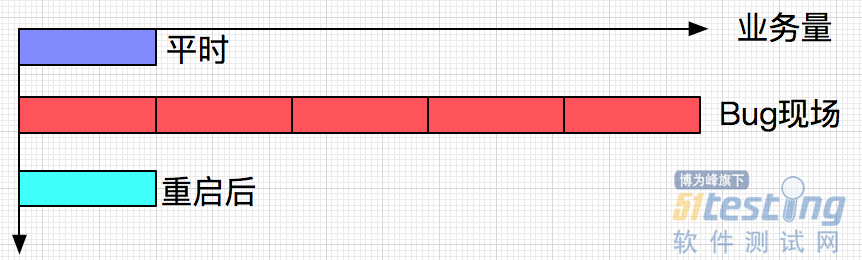
第一反应,当然是祭出重启大法,第一时间重启了机器。此后一切正常,交易量也回归正常,仿佛刚才的Bug从来没有发生过。在此之前,此系统已经稳定运行了好几个月,从来没出现过错误。
但是,这事不能就这么过去了,下次又出这种Bug怎么办,继续重启么?由于笔者对分析这种网络协议比较在行,于是Bug就抛到了笔者这。
错误日志
线上系统用的框架为Mina,不停的Dump出其一堆以16进制表示的二进制字节流。 输入图片说明,并抛出异常

首先定位异常抛出点
以下代码仅为笔者描述Bug之用,和当时代码有较大差别。
private boolean handeMessage(IoBuffer in,ProtocolDecoderOutput out){ int lenDes = 4; byte[] data = new byte[lenDes]; in.mark(); in.get(data,0,lenDes); int messageLen = decodeLength(data); if(in.remaining() < messageLen){ logger.warn("未接收完毕"); in.reset(); return false; }else{ ...... } } |
笔者本身经常写这种拆包代码,第一眼就发现有问题。让我们再看一眼报文结构:

上面的代码首先从报文前4个字节中获取到报文长度,同时检测在buffer中的存留数据是否够报文长度。
if(in.remaining() < messageLen)
为何没有在一开始检测buffer中是否有足够的4byte字节呢。此处有蹊跷。直觉上就觉的是这导致了后来的种种现象。
事实上,在笔者解决各种Bug的过程中,经常通过猜想等手段定位出Bug的原因。但是从现场取证,通过证据去解释发生的现象,通过演绎去说服同事,并对同事提出的种种问题做出合理的解释才是最困难的。
猜想总归是猜想,必须要有实锤,没有证据也说服不了自己。
为何会抛出异常
这个异常由这句代码抛出:
int messageLen = decodeLength(data);
从上面的Mina框架Dump出的数据来看,是解析前四个字节出了问题,前4个字节为30,31,2E,01(16进制)
最前面的包长度是通过字符串来表示的,翻译成十进制就是48、49、46、1,再翻译为字符串就是('0','1', 非数字, 非数字)
30, 31, 2E, 01 (16进制)
48, 49, 46, 1 (10进制)
'0','1',非数字, 非数字 (字符串)
很明显,解析字符串的时候遇到前两个byte,0和1可以解析出来,但是遇到后面两个byte就报错了。至于为什么是For input String,'01',而不是2E,是由于传输用的是小端序。
为何报文会出现非数字的字符串
鉴于上面的错误代码,笔者立马意识到,应该是粘包了。这时候就应该去找发生Bug的最初时间点的日志,去分析为何那个时间会粘包。
由于最初那个错误日志Dump数来的数据过于长,在此就不贴出来了,以下示意图是笔者当时人肉decode的结果:

抛出的异常为: 
这个异常抛出点恰恰就在笔者怀疑的
in.get(data,0,lenDes);
这里。至此,笔者就几乎已经确定是这个Bug导致的。
演绎
Mina框架在Buffer中解帧,前5帧正常。但是到第六帧的时候,只有两个字节,无法组成报文的4byte长度头,而代码没有针对此种情况做处理,于是报错。为何会出现这种情况:
TCP窗口的大小取决于当前的网络状况、对端的缓冲大小等等因素,
TCP将这些都从底层屏蔽。开发者无法从应用层获取这些信息。
这就意味着,当你在接收TCP数据流的时候无法知道当前接收了
有多少数据流,数据可能在任意一个比特位(seq)上。
这就是所谓的"粘包"问题。
详情见笔者另一篇博客https://my.oschina.net/alchemystar/blog/833937
第六帧的头两个字节是30,32正好和后面dump出来的30 31 2e 01中的30、31组成报文长度
30,32,30,31 (16进制)
48,50,48,49 (10进制)
0, 2, 0, 1 (字符串)
2, 0, 1, 0 (整理成大端序)
这四个字节组合起来才是正常的报文头,再经过运算得到整个Body的长度。
第一次Mina解析的时候,后面的两个30,31尚未放到buffer中,于是出错:
public ByteBuffer get(byte[] dst, int offset, int length) { checkBounds(offset, length, dst.length); // 此处抛出异常 if (length > remaining()) throw new BufferUnderflowException(); int end = offset + length; for (int i = offset; i < end; i++) dst[i] = get(); return this; } |
为何流量会飙升
解释这个问题前,我们先看一段Mina源码:
// if there is any data left that cannot be decoded, we store // it in a buffer in the session and next time this decoder is // invoked the session buffer gets appended to if (buf.hasRemaining()) { if (usingSessionBuffer && buf.isAutoExpand()) { buf.compact(); } else { storeRemainingInSession(buf, session); } } else { if (usingSessionBuffer) { removeSessionBuffer(session); } } |
Mina框架为了解决粘包问题,会将这种尚未接收完全的包放到sessionBuffer里面,待解析完毕后把这份Buffer删除。
如果代码正确,对报文头做了校验,那么前5个报文的buffer将经由这几句代码删除,只留下最后两个没有被decode的两字节。
if (usingSessionBuffer && buf.isAutoExpand()) {
buf.compact();
} else {
storeRemainingInSession(buf, session);
}
但是,由于decode的时候抛出了异常,没有走到这段逻辑,所以前5个包还留在sessionBuffer中,下一次解包的时候,又会把这5个包给解析出来,发送给后面的系统。如下图示: 
这也很好的解释了为什么业务量激增,因为系统不停的发相同的5帧给后面系统,导致监控认为业务量飙升。后查询另一个系统的日志,发现一直同样的5个序列号坐实了这个猜想。
完结了么?
NO,整个演绎还有第二段日志的推演
就是系统后来不停dump出的日志,再贴一次:













