ЁЁЁЁзюНќдкЦѓвЕРяУцПДСЫвЛаЉВтЪдАИР§ЕФЪ§ОнзМБИЃЌЗЂЯжСЫвЛИіЙВадЮЪЬтЃКВтЪдЪ§ОнжаДцдкДѓСПШпгрЃЌетаЉШпгрЛсИјКѓајЕФВтЪдАИР§МАЪ§ОнЮЌЛЄДјРДДѓСПЕФГЩБОЁЃ
ЁЁЁЁЮЊСЫБугкДѓМвРэНтЃЌЯШОйвЛИіР§згЃК
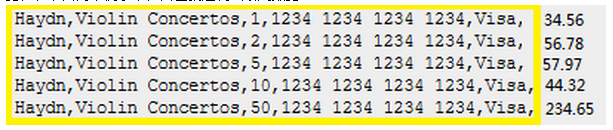
ЁЁЁЁВтЪдаХгУПЈНЛвзН№ЖюЛузмЃЌВтЪдЪ§ОнЭъШЋДгcsvжаМгдиЃЌУПИіВтЪдАИР§ИљОнcsvжаЕФЪ§ОнЃЌassertЬиЖЈЗЕЛижЕЃЈгЩгкЦЊЗљЯожЦЃЌетРяжЛОйСЫвЛИіМђЕЅЕФР§згЁЃЪЕМЪПДЕНЕФЧщПіЪЧЃЌcsvЭъШЋУЛгазжЖЮУћГЦаХЯЂЃЌвЛааРяУцГЩАйЩЯЧЇИіЪ§ОнЃЌЖјЧвЛЙгааэаэЖрЖрРрЫЦНсЙЙЕФcsvЮФМўзїЮЊВтЪдЪ§ОнЃЉЁЃ
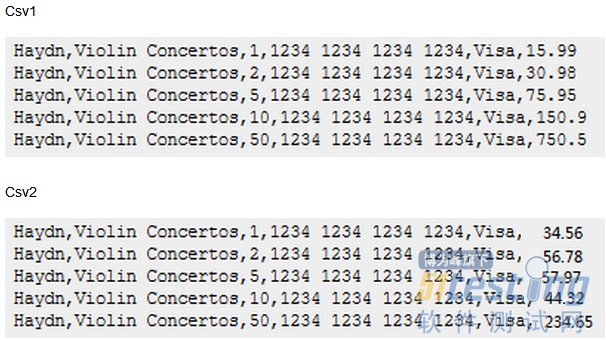
ЁЁЁЁдкетСНИіЮФМўРяУцЃЌЮвзЂвтЕНгаДѓСПШпгрЁЃвдcsvИёЪНЕФВтЪдАИР§ЮЊР§ЃЌЯыЯѓвЛЯТШчЙћЮДРДетИіБэНсЙЙЗЂЩњБфЛЏЃЈдіМгЛђМѕЩйзжЖЮЃЉЃЌФЧУДашвЊаоИФЫљгаетаЉcsvЮФМўЃЌЛсЪЧЪВУДбљЕФЙЄзїСПЃЁ
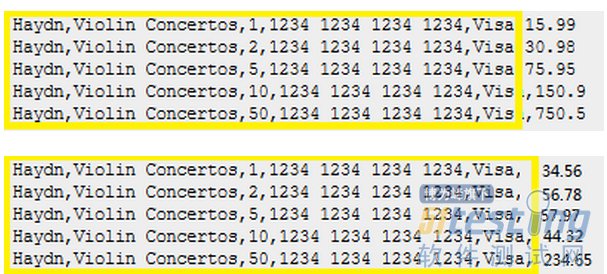
ЁЁЁЁдкЧЧСКЗвыЕФЁЖГжајНЛИЖЃКЗЂВМПЩППШэМўЕФЯЕЭГЗНЗЈЁЗвЛЪщЃЌЦфЪЕвбОИјГіСЫНтОіЫМТЗЃЌжЛВЛЙ§гЩгкУЛгаОпЬхЪЕР§ЃЌВЛЪЧКмШнвзРэНтЁЃ
ЁЁЁЁОКЮУуЬсабЃЌЗЂЯждкЁЖЪЕР§ЛЏашЧѓЁЗвЛЪщжаЃЌвВЬсЕНСЫРрЫЦЫМТЗЃЌЕЋЭЌбљЖМУЛгаЪЕР§ЃЌЃКЃЉЃК
ЁЁЁЁЯТУцЮвУЧОЭвдЩЯУцР§згЮЊЛљДЁЃЌЫЕУївЛЯТСНБОЪщжаЕФЫМТЗШчКЮОпЬхгІгУЃК
ЁЁЁЁгІгУГЬађв§гУЪ§Он(Application reference data)ЪЧВтЪдЮоЙиЪ§ОнЃЌЕЋЫќУЧЪЧгІгУГЬађЦєЖЏЫљБиашЕФЃЌетаЉЪ§ОнЭљЭљЪЧжИвЛаЉЛљБэКЭЛљДЁЪ§ОнЃЛ
ЁЁЁЁВтЪдв§гУЪ§ОнЃЈTest reference dataЃЉЪЧФЧаЉКЭВтЪдЯрЙиЃЌЕЋЪЧЖдВтЪдааЮЊУЛгаЖрДѓгАЯьЕФЪ§ОнЃЌдкЯТУцСНИіР§згжаЃЌЛЦЩЋОЭЪЧВтЪдв§гУЪ§Он