

Spark在Map阶段调度运行的ShuffleMapTask,最后会生成.data和.index文件,可以通过我的这篇文章 Spark Shuffle过程分析:Map阶段处理流程 了解具体流程和详情。同时,在Executor上运行一个ShuffleMapTask,返回了一个MapStatus对象,下面是ShuffleMapTask执行后返回结果的相关代码片段:
var writer: ShuffleWriter[Any, Any] = null try { val manager = SparkEnv.get.shuffleManager writer = manager.getWriter[Any, Any] (dep.shuffleHandle, partitionId, context) writer.write(rdd.iterator (partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]) writer.stop(success = true).get } catch { case e: Exception => try { if (writer != null) { writer.stop(success = false) } } catch { case e: Exception => log.debug("Could not stop writer", e) } throw e } |
如果ShuffleMapTask执行过程没有发生异常,则最后执行的调用为:
writer.stop(success = true).get
这里返回了一个MapStatus类型的对象,MapStatus的定义如下所示:
private[spark] sealed trait MapStatus { def location: BlockManagerId def getSizeForBlock(reduceId: Int): Long } |
其中包含了运行ShuffleMapTask所在的BlockManager的地址,以及后续Reduce阶段每个ResultTask计算需要Map输出的大小(Size)。我们可以看下MapStatus如何创建的,在SortShuffleWriter的write()方法中,可以看到MapStatus的创建,如下代码所示:
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
继续跟踪可以看到,调用了MapStatus的伴生对象的apply()方法:
def apply(loc: BlockManagerId, uncompressedSizes: Array[Long]): MapStatus = { if (uncompressedSizes.length > 2000) { HighlyCompressedMapStatus(loc, uncompressedSizes) } else { new CompressedMapStatus(loc, uncompressedSizes) } } |
uncompressedSizes表示Partition的个数,如果大于2000则创建HighlyCompressedMapStatus对象,否则创建CompressedMapStatus对象,他们具体的实现可以参考源码。
含有Shuffle过程的Spark Application示例
我们先给出一个简单的Spark Application程序代码,如下所示:
val rdd = sc.textFile("/temp/*.h") val finalRdd = rdd.flatMap(line => line.split("\\s+")).map(w => (w, 1)).reduceByKey(_ + _) finalRdd.toDebugString finalRdd.saveAsTextFile("/temp/output") |
通过RDD的toDebugString()方法,打印调试信息:
scala> finalRdd.toDebugString res0: String = (133) ShuffledRDD[6] at reduceByKey at <console>:30 [] +-(133) MapPartitionsRDD[5] at map at <console>:30 [] | MapPartitionsRDD[4] at flatMap at <console>:30 [] | /temp/*.h MapPartitionsRDD[3] at textFile at <console>:29 [] | /temp/*.h HadoopRDD[2] at textFile at <console>:29 [] |
可以看到这个过程中,调用了reduceByKey(),创建了一个ShuffledRDD,这在计算过程中会执行Shuffle操作。
ShuffleMapTask执行结果上报处理流程
Spark Application提交以后,会生成ShuffleMapStage和/或ResultStage,而一个ShuffleMapStage对应一组实际需要运行的ShuffleMapTask,ResultStage对应一组实际需要运行ResultTask,每组Task都是有TaskSetManager来管理的,并且只有ShuffleMapStage对应的一组ShuffleMapTask都运行成功结束以后,才会调度ResultStage。
所以,我们这里关注的是,当ShuffleMapStage中最后一个ShuffleMapTask运行成功后,如何将Map阶段的信息上报给调度器(Driver上的TaskScheduler和DAGScheduler),了解这个处理流程对理解后续的Reduce阶段处理至关重要,这个过程的详细处理流程,如下图所示:
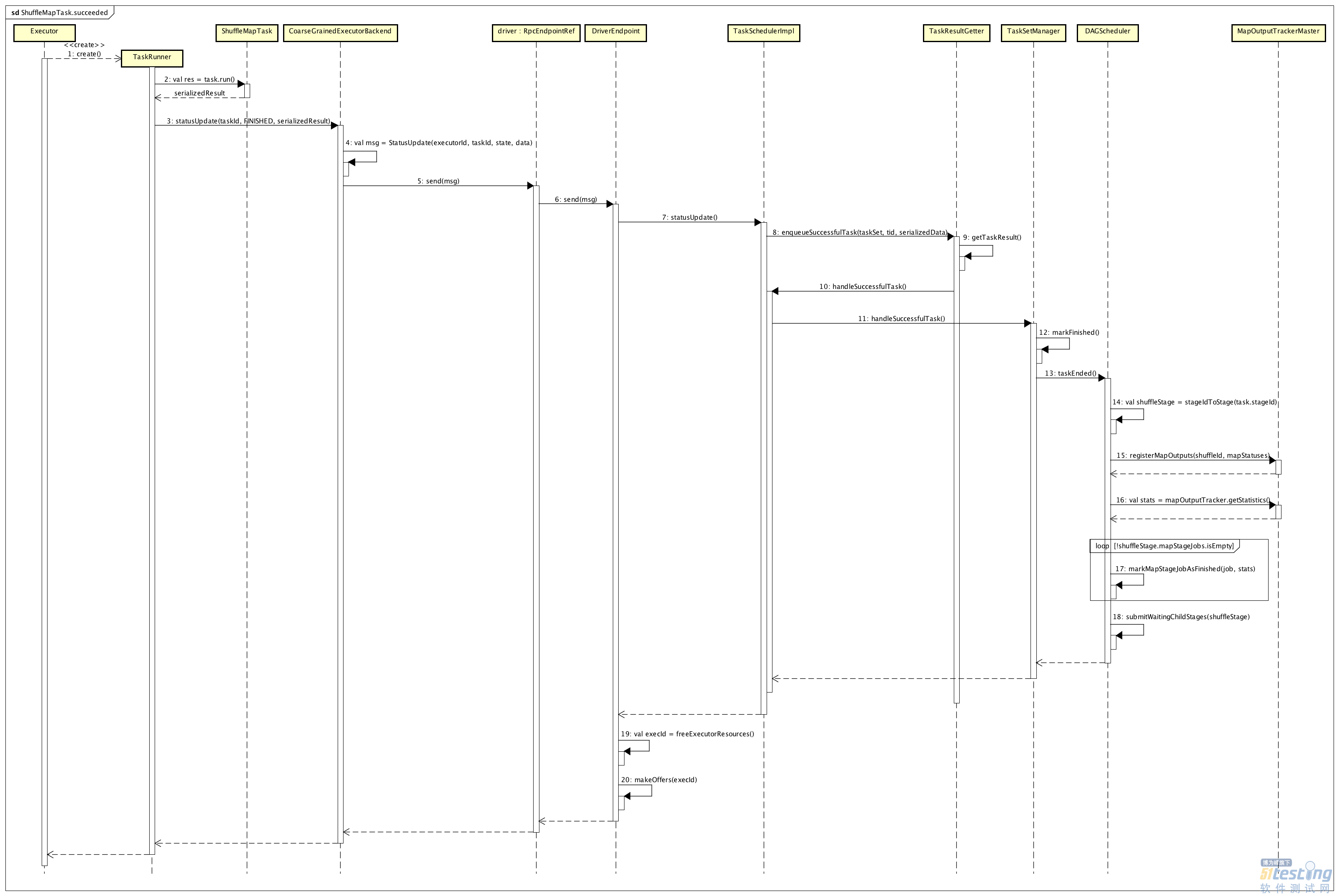
我们将整个流程按照顺序分为如下几个过程来描述:
ShuffleMapTask完成后处理结果
Executor会启动一个TaskRunner线程来运行ShuffleMapTask,ShuffleMapTask完成后,会对结果进行序列化处理,代码如下所示:
val directResult = new DirectTaskResult(valueBytes, accumUpdates) val serializedDirectResult = ser.serialize(directResult) val resultSize = serializedDirectResult.limit |
根据序列化后结果serializedDirectResult的大小resultSize,会进行一些优化,代码如下所示:
val serializedResult: ByteBuffer = { if (maxResultSize > 0 && resultSize > maxResultSize) { logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " + s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " + s"dropping it.") ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize)) } else if (resultSize > maxDirectResultSize) { val blockId = TaskResultBlockId(taskId) env.blockManager.putBytes( blockId, new ChunkedByteBuffer(serializedDirectResult.duplicate()), StorageLevel.MEMORY_AND_DISK_SER) logInfo( s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)") ser.serialize(new IndirectTaskResult[Any](blockId, resultSize)) } else { logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver") serializedDirectResult } } |
最后,结果会调用CoarseGrainedExecutorBackend的statusUpdate方法,如下所示:
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
将Task对应的运行状态、运行结果发送给Driver。
Driver获取Task运行结果
集群模式下,Driver端负责接收Task运行结果的是CoarseGrainedSchedulerBackend,它内部有一个DriverEndpoint来负责实际网络通信,以及接收Task状态及其结果,代码如下所示:
case StatusUpdate(executorId, taskId, state, data) => scheduler.statusUpdate(taskId, state, data.value) if (TaskState.isFinished(state)) { executorDataMap.get(executorId) match { case Some(executorInfo) => executorInfo.freeCores += scheduler.CPUS_PER_TASK makeOffers(executorId) case None => // Ignoring the update since we don't know about the executor. logWarning(s"Ignored task status update ($taskId state $state) " + s"from unknown executor with ID $executorId") } } |
如果消息类型为StatusUpdate,则首先直接调用了TaskSchedulerImpl的statusUpdate()方法,来获取Task的运行状态及其结果,代码如下所示:
if (TaskState.isFinished(state)) { cleanupTaskState(tid) taskSet.removeRunningTask(tid) if (state == TaskState.FINISHED) { taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData) } else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) { taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData) } } |
如果Task状态是TaskState.FINISHED,则通过TaskResultGetter来获取Task运行返回的结果,这里存在DirectTaskResult和IndirectTaskResult两种类型的结果,他们的处理方式不同:对于DirectTaskResult类型的结果,如下所示:
case directResult: DirectTaskResult[_] => if (!taskSetManager.canFetchMoreResultsv (serializedData.limit())) { return } // deserialize "value" without holding any lock so that it won't block other threads. directResult.value (taskResultSerializer.get()) |
直接从DirectTaskResult中就可以通过反序列化得到结果,而对于IndirectTaskResult类型的结果,逻辑相对复杂一些,如下所示:
case IndirectTaskResult(blockId, size) => ... ... scheduler.handleTaskGettingResult(taskSetManager, tid) val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId) ... ... val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]]( serializedTaskResult.get.toByteBuffer) // force deserialization of referenced value deserializedResult.value(taskResultSerializer.get()) sparkEnv.blockManager.master.removeBlock(blockId) |
结果大小超过指定的限制值,在ShuffleMapTask运行过程中会直接通过BlockManager存储到Executor的内存/磁盘上,这里就会根据结果Block ID,通过BlockManager来获取到结果对应的Block数据。
更新Driver端Task、Stage状态,并调度Stage运行
获取到ShuffleMapTask运行的结果数据后,需要更新TaskSetManager中对应的状态信息,以便为后续调度Task运行提供决策支持,代码如下所示:
scheduler.handleSuccessfulTask(taskSetManager, tid, result)
上面代码调用了TaskSetManager的handleSuccessfulTask()方法,更新相关状态,同时继续更新DAGScheduler中对应的状态,代码片段如下所示:
sched.dagScheduler.taskEnded(tasks(index), Success, result.value(), result.accumUpdates, info) maybeFinishTaskSet() |
调用DAGScheduler的taskEnded()方法,更新Stage信息。如果一个ShuffleMapTask运行完成后,而且是对应的ShuffleMapStage中最后一个ShuffleMapTask,则该ShuffleMapStage也完成了,则会注册该ShuffleMapStage运行得到的所有Map输出结果,代码如下所示:
mapOutputTracker.registerMapOutputs( shuffleStage.shuffleDep.shuffleId, shuffleStage.outputLocInMapOutputTrackerFormat(), changeEpoch = true) |
上面MapOutputTracker维护了一个ConcurrentHashMap[Int, Array[MapStatus]]内存结构,用来管理每个ShuffleMapTask运行完成返回的结果数据,其中Key是Shuffle ID,Value使用数组记录每个Map ID对应的输出结果信息。
下面代码判断ShuffleMapStage是否可用,从而进行相应的处理:
if (!shuffleStage.isAvailable) { // Some tasks had failed; let's resubmit this shuffleStage. // TODO: Lower-level scheduler should also deal with this logInfo("Resubmitting " + shuffleStage + " (" + shuffleStage.name + ") because some of its tasks had failed: " + shuffleStage.findMissingPartitions().mkString(", ")) submitStage(shuffleStage) } else { // Mark any map-stage jobs waiting on this stage as finished if (shuffleStage.mapStageJobs.nonEmpty) { val stats = mapOutputTracker.getStatistics(shuffleStage.shuffleDep) for (job <- shuffleStage.mapStageJobs) { markMapStageJobAsFinished(job, stats) } } submitWaitingChildStages(shuffleStage) |
如果ShuffleMapStage不可用,说明还有某些Partition对应的结果没有计算(或者某些计算失败),Spark会重新提交该ShuffleMapStage;如果可用,则说明当前ShuffleMapStage已经运行完成,更新对应的状态和结果信息:标记ShuffleMapStage已经完成,同时提交Stage依赖关系链中相邻下游的Stage运行。如果后面是ResultStage,则会提交该ResultStage运行。
释放资源、重新调度Task运行
一个ShuffleMapTask运行完成,要释放掉对应的Executor占用的资源,在Driver端会增加对应的资源列表,同时调度Task到该释放的Executor上运行,可见CoarseGrainedSchedulerBackend.DriverEndpoint中对应的处理逻,代码如下所示:
if (TaskState.isFinished(state)) { executorDataMap.get(executorId) match { case Some(executorInfo) => executorInfo.freeCores += scheduler.CPUS_PER_TASK makeOffers(executorId) |
上面makeOffers()方法,会调度一个Task到该executorId标识的Executor上运行。如果ShuffleMapStage已经完成,那么这里可能会调度ResultStage阶段的ResultTask运行。
Reduce阶段处理流程
上面我们给出的例子中,执行reduceByKey后,由于上游的RDD没有按照key执行分区操作,所以必定会创建一个ShuffledRDD,可以在PairRDDFunctions类的源码中看到combineByKeyWithClassTag方法,实现代码如下所示:
def combineByKeyWithClassTag[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true, serializer: Serializer = null) (implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope { require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0 if (keyClass.isArray) { if (mapSideCombine) { throw new SparkException("Cannot use map-side combining with array keys.") } if (partitioner.isInstanceOf [HashPartitioner]) { throw new SparkException ("Default partitioner cannot partition array keys.") } } val aggregator = new Aggregator[K, V, C]( self.context.clean (createCombiner), self.context.clean (mergeValue), self.context.clean (mergeCombiners)) if (self.partitioner == Some(partitioner)) { self.mapPartitions(iter => { val context = TaskContext.get() new InterruptibleIterator (context, aggregator.combineValuesByKey(iter, context)) }, preservesPartitioning = true) } else { new ShuffledRDD[K, V, C](self, partitioner) .setSerializer(serializer) .setAggregator(aggregator) .setMapSideCombine(mapSideCombine) } } |
这里,因为我们给出的例子的上下文中,self.partitioner == Some(partitioner)不成立,所以最终创建了一个ShuffledRDD对象。所以,对于Reduce阶段的处理流程,我们基于ShuffledRDD的处理过程来进行分析。
我们从ResultTask类开始,该类中实现了runTask()方法,代码如下所示:
override def runTask(context: TaskContext): U = { // Deserialize the RDD and the func using the broadcast variables. val deserializeStartTime = System.currentTimeMillis() val ser = SparkEnv.get.closureSerializer.newInstance() val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)]( ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader) _executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime func(context, rdd.iterator(partition, context)) } |
其中,最核心的就是上面的rdd.iterator()调用,具体处理过程,如下图所示:
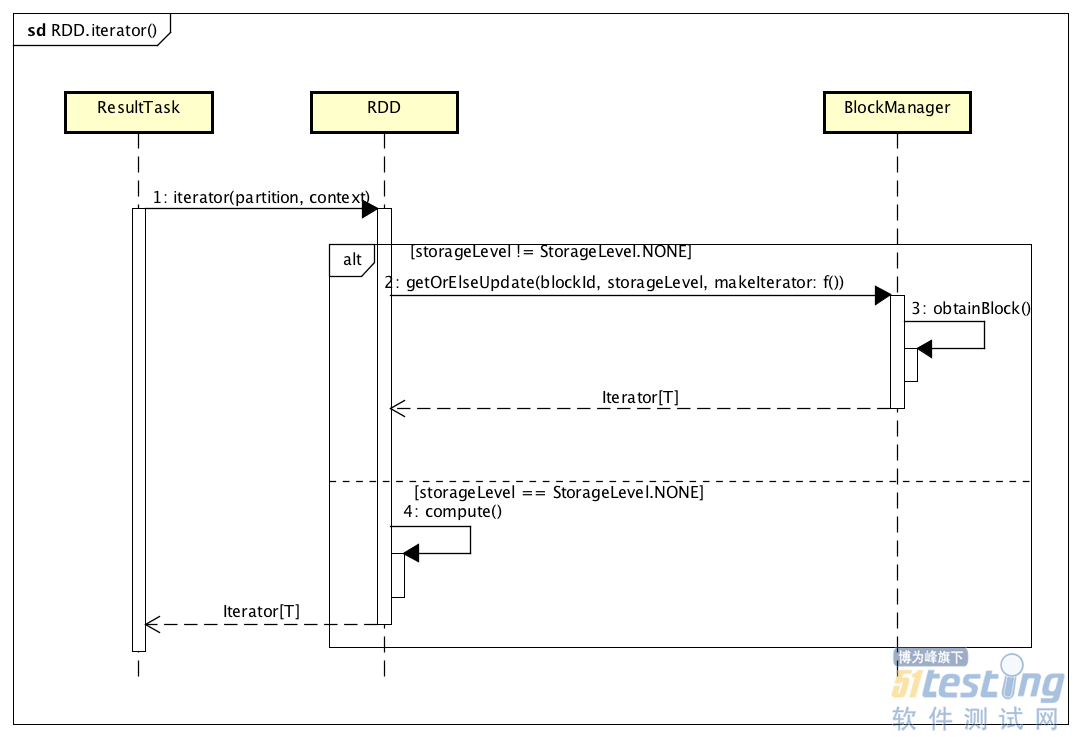
最终,它用来计算一个RDD,即对应ShuffledRDD的计算。iterator()方法是在RDD类中给出的,如下所示:
final def iterator(split: Partition, context: TaskContext): Iterator[T] = { if (storageLevel != StorageLevel.NONE) { getOrCompute(split, context) } else { computeOrReadCheckpoint(split, context) } } |
跟踪getOrCompute()方法,最终应该是在ShuffledRDD类的compute()方法中定义。
ShuffledRDD计算
ShuffledRDD对应的compute方法的实现代码,如下所示:
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { val dep = dependencies.head.asInstanceOf [ShuffleDependency[K, V, C]] SparkEnv.get.shuffleManager.getReader (dep.shuffleHandle, split.index, split.index + 1, context) .read() .asInstanceOf[Iterator[(K, C)]] } |
上面主要是通过BlockStoreShuffleReader的read()方法,来实现ShuffledRDD的计算,我们通过下面的序列图来看一下详细的执行流程:
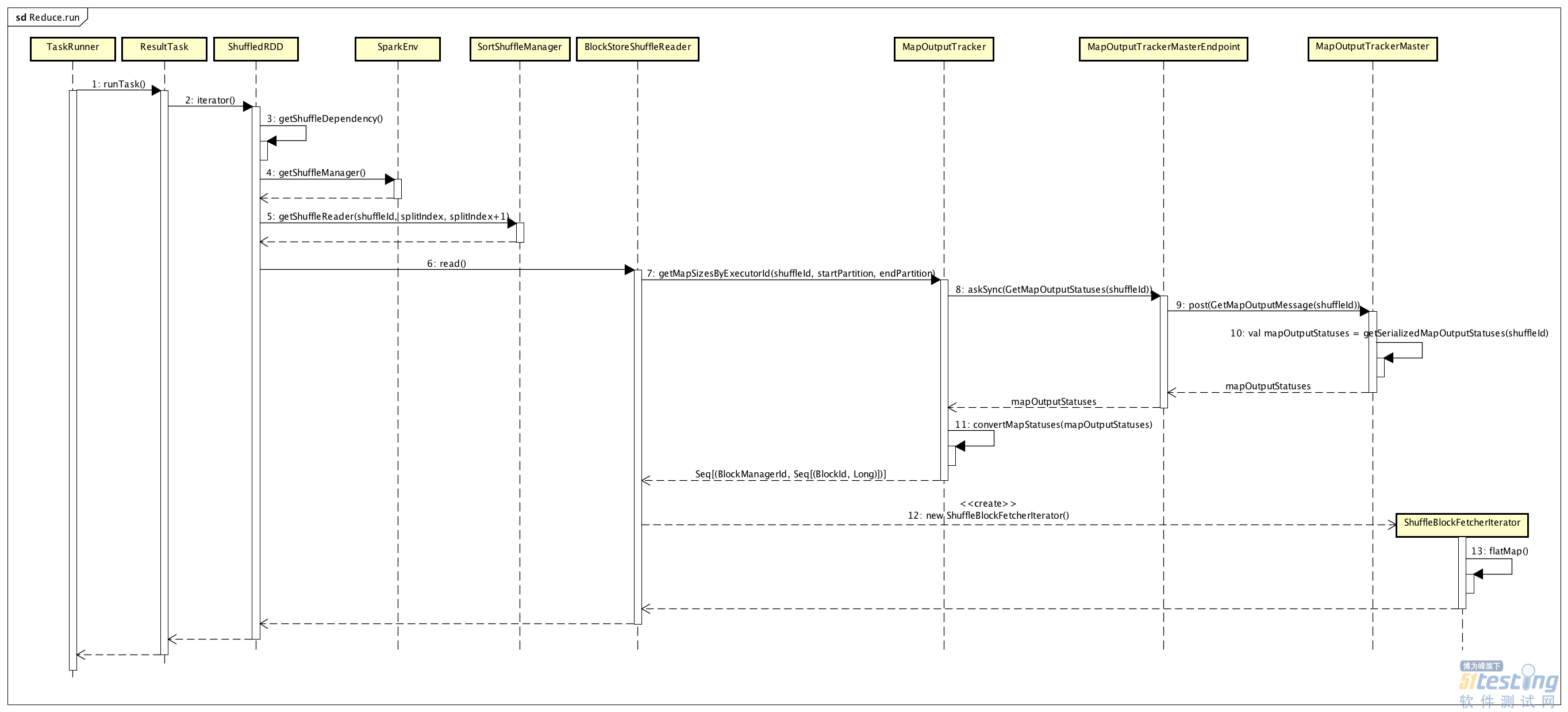
跟踪Map的输出结果,是基于Executor端的MapOutputTracker与Driver端的MapOutputTrackerMaster来实现的,其中MapOutputTrackerMaster作为Server端,MapOutputTracker作为Client端。Driver端管理了一个Spark Application计算程序的ShuffleMapStage中所有ShuffleMapTask的输出,所以在Reduce过程中Executor会通过MapOutputTracker与Driver的MapOutputTrackerMaster进行通信获取。
调用BlockStoreShuffleReader的read()方法,最终得到了Reduce过程中需要的输入,即ShuffleMapTask的输出结果所在的位置。通常,为了能够使计算在数据本地进行,每个ResultTask运行所在的Executor节点会存在对应的Map输出,是通过BlockManager来管理这些数据的,通过Block ID来标识。所以,上图中最后返回了一个BlockManager ID及受其管理的一个Block ID列表,然后Executor上的ResultTask就能够根据BlockManager ID来获取到对应的Map输出数据,从而进行数据的计算。
ResultTask运行完成后,最终返回一个记录的迭代器,此时计算得到的最终结果数据,是在各个ResultTask运行所在的Executor上的,而数据又是按Block来存储的,是通过BlockManager来管理的。
保存结果RDD
根据前面的程序示例,最后调用了RDD的saveAsTextFile(),这会又生成一个ResultStage,进而对应着一组ResultTask。保存结果RDD的处理流程,如下图所示:
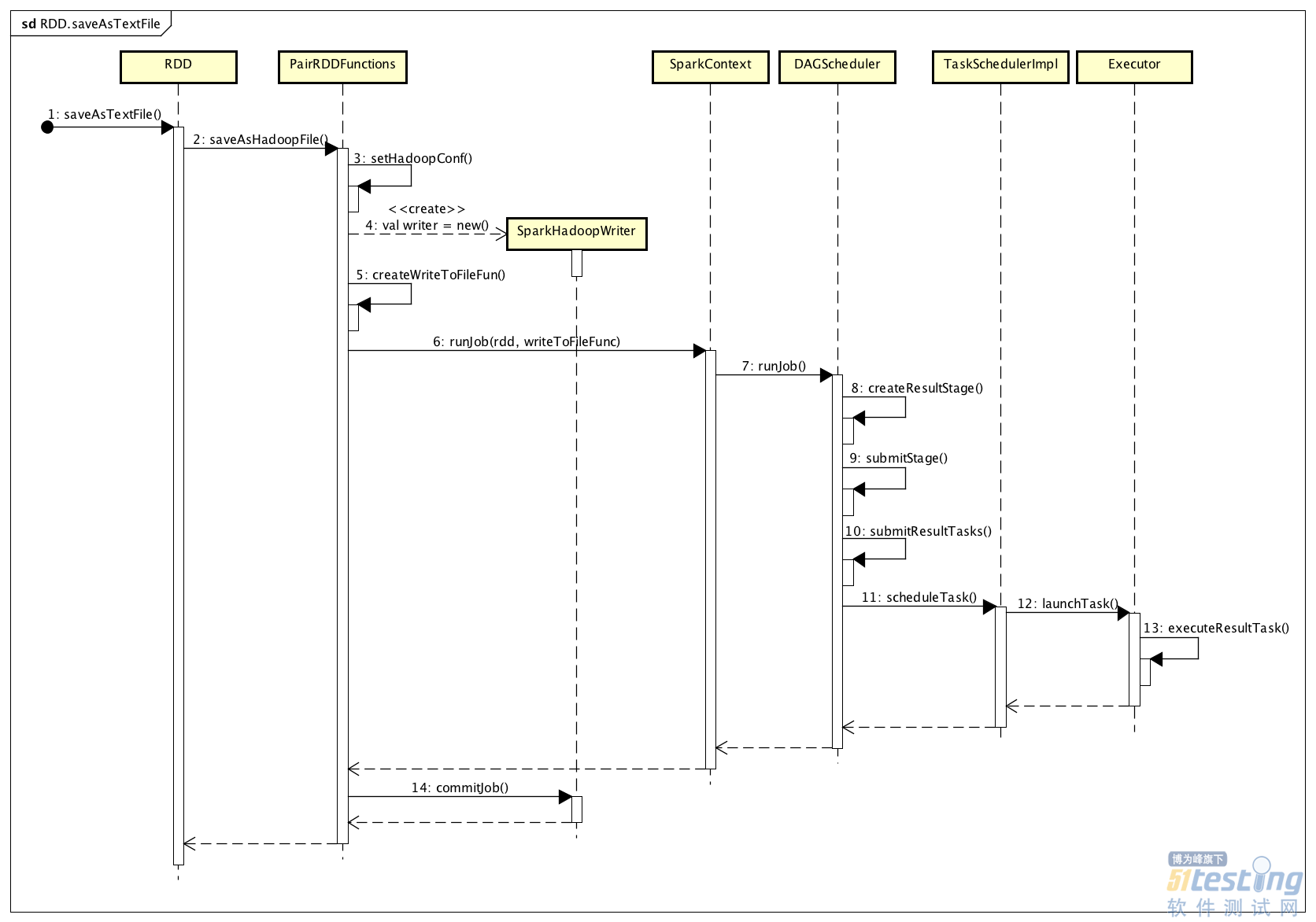
上面整个流程,会执行设置RDD输出到HDFS的Writer(一个写文件的函数)、提交ResultStage、构建包含ResultTask的TaskSet、调度ResultTask到指定Executor上执行这几个核心的过程。实际上,在每个Executor上运行的ResultTask的核心处理逻辑,主要是下面这段函数代码:
val writer = new SparkHadoopWriter(hadoopConf) writer.preSetup() val writeToFile = (context: TaskContext, iter: Iterator[(K, V)]) => { val taskAttemptId = (context.taskAttemptId % Int.MaxValue).toInt val (outputMetrics, callback) = SparkHadoop WriterUtils.initHadoopOutputMetrics (context) writer.setup (context.stageId, context.partitionId, taskAttemptId) writer.open() var recordsWritten = 0L Utils.tryWithSafeFinallyAndFailureCallbacks { while (iter.hasNext) { val record = iter.next() writer.write(record._1.asInstanceOf[AnyRef], record._2.asInstanceOf[AnyRef]) // Update bytes written metric every few records SparkHadoopWriterUtils.maybeUpdateOutputMetrics (outputMetrics, callback, recordsWritten) recordsWritten += 1 } }(finallyBlock = writer.close()) writer.commit() outputMetrics.setBytesWritten (callback()) outputMetrics.setRecordsWritten(recordsWritten) } |
还记得我们在计算ShuffledRDD的过程中,最终的ResultTask生成了一个结果的迭代器。当调用saveAsTextFile()时,ResultStage对应的一组ResultTask会在Executor上运行,将每个迭代器对应的结果数据保存到HDFS上。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












