

3. 方法

如图 5 显示,TBooster 的测试用例框架主要包含两个步骤:(1)自动化地提取依赖意识的测试用例;(2)自动化地推荐前 k 个测试用例给待测方法(新的测试目标)。
3.1 依赖意识的测试用例提取
一个依赖意识的测试用例提取需要四个过程:测试方法提取、测试依赖分析、测试目标识别和单元测试粒度规范化。
3.1.1 测试方法提取(Test Method Extraction)
测试方法提取主要通过结合不同单元测试框架的特征来实施。大多数框架通过使用注解‘@Test’来区别测试方法。同一框架的不同版本存在一些差异。例如,在 JUnit 4.x 和 JUnit 5.x 中是通过使用注解‘@Test’,但是在 JUnit 3.x 要求测试方法所属的类要继承一个特性的类‘TestCase’。我们已经为不同的情况提出了不同的解决方案以至于我们可以提取充足的测试方法。
3.1.2 测试依赖分析(Test Dependency Analysis)
测试依赖分析是后续的测试目标识别的前提条件。四种变量和三种方法调用需要被分析。
变量依赖(Variable dependencies)。对于外部变量,我们根据‘import’信息(例如图 3 的第 1 至 2 行)提取相关的声明。例如,我们为图 3 中测试方法 attachMultipleRequests() 使用的外部变量 URI1 提取声明语句 static final Uri URI1 = Uri .parse(“xxx”); 。对于来自第三方库的变量,我们不为它们提取声明并且直接保存‘import’信息,因为这些变量通常很容易发现和理解通过使用‘import’信息在网上搜索。
方法依赖(Method Dependencies)。对于内部和外部方法调用,我们提取并保存它们的代码块。提别地,对于外部方法调用,我们进一步标记它们来源,例如来源于生产代码或测试代码。这样的标记在测试目标识别中非常有用。对于来自第三方库中的方法调用,像来自第三方库中的变量依赖一样,我们也仅保存‘import’信息。
为测试方法提取完整的测试依赖是一个复杂的任务。我们实践了 JUnit 测试用例的测试依赖分析并且发现及时借助成熟的开源工具 JavaParser,也无法保证提取的测试依赖是完整的。主要原因是 GitHub 是代码托管平台并不保证每个项目是完整的项目。许多项目或多或少丢失了一些工件,例如 maven 依赖。
3.1.3 测试目标识别(Test Target Recognition)
测试目标满足两个条件:(1)测试目标必须与‘assert’语句(例如图 3a 中的第 15 行 assertThat())关联;(2)测试目标一定是外部方法依赖,其中方法是来源于生产代码。因此测试目标识别包括如下两个过程:
首先,我们将‘assert’语句视为起点并且分析其参数中‘actual/condition’的位置。根据前期对开源项目的观察,我们发现断言是多种多样的。除了 JUnit 自带的断言,AssertJ 和 Truth 也是常用的断言库。这些断言虽然有着相似的功能,但是形式上明显存在差异。参数‘actual/condition’的位置在不同断言中是不同的,例如 assertTrue(condition) 和 assertEquals(message, expected, actual )。
然后,我们根据方法标签从所有的方法依赖中挑选出外部方法依赖。对于每个‘actual/condition’参数,我们计算其与在它之间出现的所有方法调用之间的距离(两个代码行数的相减)。例如,在图 3a 中,‘actual’参数 hunter.actions (第 17 行)和方法调用 attach() 之间的距离是 1;hunter.actions 与 TestableBitmapHunter() 距离是 3。在这种情况下,方法 attach() 和 TestableBitmapHunter() 是两个候选的测试目标。我们进一步基于是否测试目标是来源于生产代码决定测试目标。如果候选的测试目标都是来源于生产代码,我们基于就近原则(即上述提到的距离)决定测试目标。例如,对于‘actual’参数 hunter.actions 出现的断言语句,最有可能的测试目标是 attach() 而不是 TestableBitmapHunter() 。
3.1.4 单元测试粒度规范化(Unit Test Granularity Normalization)
如前面提到的,每个测试用例应当仅包含一个测试目标。在完成测试依赖分析和测试目标识别任务后,在 MAF 工作的指导下,我们采用切片技术来规范化每个测试方法的单元测试粒度。调用测试目标的执行语句将被选为关键点用于切片。在测试方法中,在测试目标调用之前,其需要设置初始状态(例如,对象实例化)以及准备必要的参数。此外,在测试目标调用后,测试方法需要使用断言检查测试的结果。因此,我们采用双向(后向和前向)静态切片根据变量依赖来搜索所与关键点语句相关的所有语句。例如,图 3 中的第 14 和 16 行的语句是两个关键点,在切片后,我们可以得到两个规范的测试方法如图 4 所示。我们根据其测试目标将测试方法重命名,例如测试方法 testBitmapHunter() 和 testAttach()。一个有效的测试用例由规范化的测试方法及对应的测试依赖组成。所有依赖意识的测试用例被持久化存储到候选测试用例集 CTC 中供后续的推荐使用。
3.2 测试用例推荐
3.2.1 用于推荐策略的准则
准则 I:注释间距离(DC)。如公式(2)所示,我们轻微地调整 Jaccard Index 来计算两个关键词集合间的相似度,其中 Ki 和 Kj 分别表示自然语言描述(即,注释)的关键词集合;synonyms(Ki, Kj) 是我们开发的用于计算在 和 中发现的同义词对的数量;AdaptedJI(Ki, Kj) 表示两个关键词集合 Ki 和 Kj 间的相似度。公式(1) 中的 DC(mi, mj) 表示两个方法 mi 和 mj 的注释之间的距离。
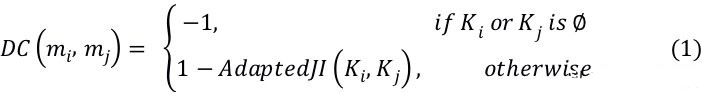
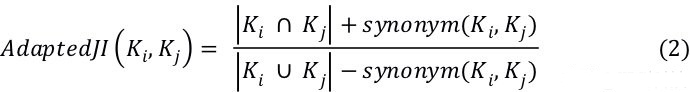
准则 II:字面文本间的距离(DL)。Chaiyong 等人对代码相似度分析器进行了广泛的研究。在他们的研究中,方法级别的相似度分析也被称为 Boiler-plate 代码检测问题。Boiler-plate 代码发生在开发者重用方法代码以实现一个特定的任务时。对比专门的代码相似性工具,尽管 Difflib 是一个文本相似性度量工具,但其在 Boiler-plate 代码检测场景中获得了最大的 AUC(Area Under ROC Curve)。具体的,其提供一个 ratio() 接口,该接口返回序列的相似性的度量值为 [0, 1] 的浮点数,其中 1.0 表示序列相同,0.0 表示完全不同。公式(3) 是 ratio() 接口背后的计算公式。其中,matches(s1, s2) 是 Difflib 检测到的匹配到数量,| s1| 和 | s2| 分别表示 s1 和 s2 种的元素数量。 注意,公式(3)是非堆成的,因为
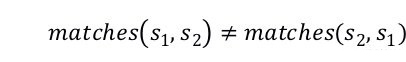
。因此,我们使用公式(4)来计算两个字面文本上的距离。
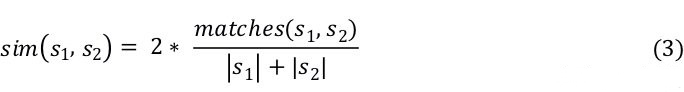
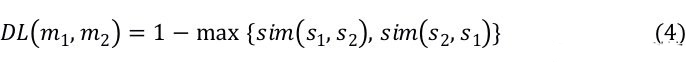
准则 III:控制流图间的距离(DG)。我们采用 Hu 等人提出的基于图编辑距离的算法来度量控制流图的相似性。该算法可以近似将一个图转变成另一个图需要的最小的编辑操作数量。在本文中,我们假设统一的编辑操作代价为 1。Hu 等人提出的算法的基本思路是(1)构建一个代价矩阵表示两个控制流图之间的映射代价;然后(2)使用匈牙利算法发现总代价最小的节点间匹配。两个控制流图间的距离通过公式(7)计算,其中 |Ni| 和 |Ei| 分别表示 CFG 中的节点和边的数量;the minimum cost 是通过匈牙利算法在代价矩阵上运行得到的。

进一步,我们使用 DG(mi, mj) 表示两个测试目标 mi 和 mj 在控制流上的距离,即
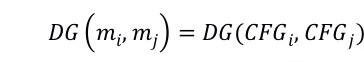
3.2.2 我们的推荐策略
基于上述准则,我们将这些距离组合产生一个混合的距离。具体而言,公式(8)组合了两个方法的字面文本和控制流上的距离,用于表示代码块上的距离 DB。其中
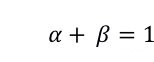

我们设计了算法 1 用于从 CTC 中搜索前 k 个测试用例用于推荐给开发者。给定一个待测方法(新的测试目标) mi,我们首先使用其签名(line 2)搜索测试目标。对于两个具有相同签名的方法,我们进一步检查是否他们的代码在字面上是否是相同的。如果是相同的,我们采用及联搜索来提高搜索效率(lines 4 - 11)。如果 CTC 中不存在与 mi 具有相同签名的测试目标,算法达到 line 13。对于每一个测试用例 tcj,我们首先获取其测试目标 ttj (line 14)。我们度量两个测试目标 mi 和 ttj 之间的字面距离 (dl),如果
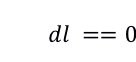
,我们将启动及联搜索以提高搜索效率(lines 16 – 20)。其次,如果
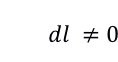
,我们将度量距离 bd (lines 21 - 23)。公式(9)被设计用来计算 bd 的值。基于距离 bd,我们动态地更新推荐的测试用例集 TC (lines 24 -28)。一旦所有测试用例已经被搜索,算法将排序 TC (line 31)。默认是根据平衡距离对 TC 中的测试用例进行排序。如果两个候选测试用例平衡距离相同,我们进一步根据 DL 对它们进行排序。最终算法输出前 k 个测试用例并结束。
及联搜索(Cascade search)。在构建候选测试用例 CTC 集期间,我们不仅存储例测试用例及其测试目标,我们还存储了注释的关键词和测试目标的控制流图。这样做有两个好处:(1)加速测试用例搜索过程,对于每个
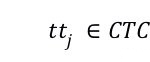
,其不需要花费更多的时间为注释提取关键词以及为代码块生成控制流;(2)其允许我们提前对 CTC 中的所有测试用例执行成对比较,这是离线任务不占用 TC 的搜索时间。注意我们之前提到的所有准则(距离)都是对称的,因此平衡距离也是对称的,即
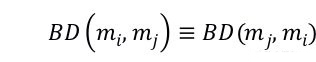
。因此,假设 ,其意味着 mi 和 mj 是完全相同的,我们可以得到
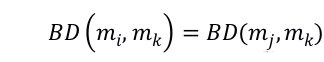
其中
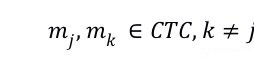
。我们将使用 mj 替代 mi 来执行进一步的测试用例搜索称为及联搜索。由于
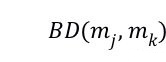
是提前计算并存储在 CTC 中的,因此,其可以降低搜索测试用例的耗时。

本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












