


下面对其进行介绍:
安装selenium

确保pip命令可用,如果提示pip不是内部或外部命令,需要将pip的安装目录(如:C:\Python36\Scripts)添加到环境变量PATH中。
接下来通过pip命令安装selenium:

安装完成后,打开一款Python编辑器,默认Python自带的IDLE也行。创建 baidu.py文件,输入以下内容:

如果执行出错,我们就要下载浏览器驱动。
下载浏览器驱动
当selenium升级到3.0之后,对不同的浏览器驱动进行了规范。如果想使用selenium驱动不同的浏览器,必须单独下载并设置不同的浏览器驱动。
各浏览器下载地址:
Firefox浏览器驱动:geckodriver
Chrome浏览器驱动:chromedriver
IE浏览器驱动:IEDriverServer
Edge浏览器驱动:MicrosoftWebDriver
Opera浏览器驱动:operadriver
PhantomJS浏览器驱动:phantomjs
注:部分浏览器驱动地址需要科学上网。
设置浏览器驱动
设置浏览器的地址非常简单。 我们可以手动创建一个存放浏览器驱动的目录,如: C:\driver , 将下载的浏览器驱动文件(例如:chromedriver、geckodriver)丢到该目录下。
我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path,将“C:\driver”目录添加到Path的值中。
?Path
?;C:\driver
然后验证不同的浏览器驱动是否正常使用:

环境搭建好了,接下来开始爬取。
爬取淘宝美食
首先来到淘宝网,搜索美食
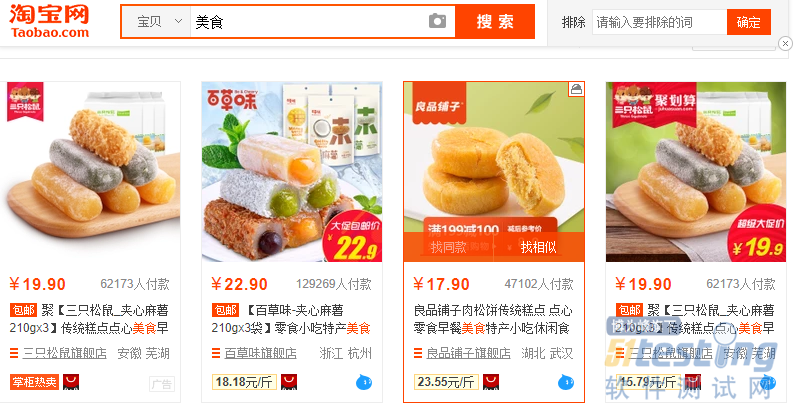
淘宝美食
可以看到,每个页面有很多商品,我们想通过点击下一页或者输入页面数进入下一页,不断从页面爬取到商品信息。
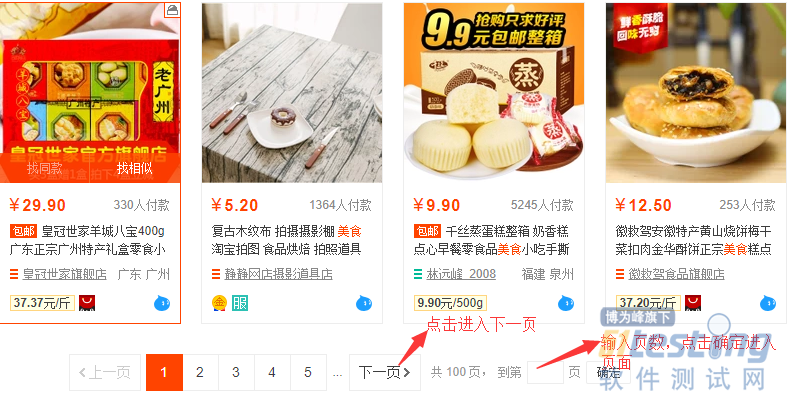
搜素关键字进入页面
代码如下:
from selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium import webdriver browser_chrome = webdriver.Chrome() wait = WebDriverWait(browser_chrome, 10) def search_keywrd_return_pagenum(keyword='美食'): browser_chrome.get('https://www.taobao.com') try: # 判断输入框是否加载出来 input_box = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, "#q")) ) # 判断搜索按钮是否存在 submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, "#J_TSearchForm > div.search-button > button")) ) # 在输入框输入关键字 input_box.send_keys(keyword) # 点击搜索按钮 submit.click() # 判断页面总数是否加载出来 total = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.total")) ) # 返回页数 return total.text except TimeoutError: # 超时就重新搜索 return search() |
运行结果:
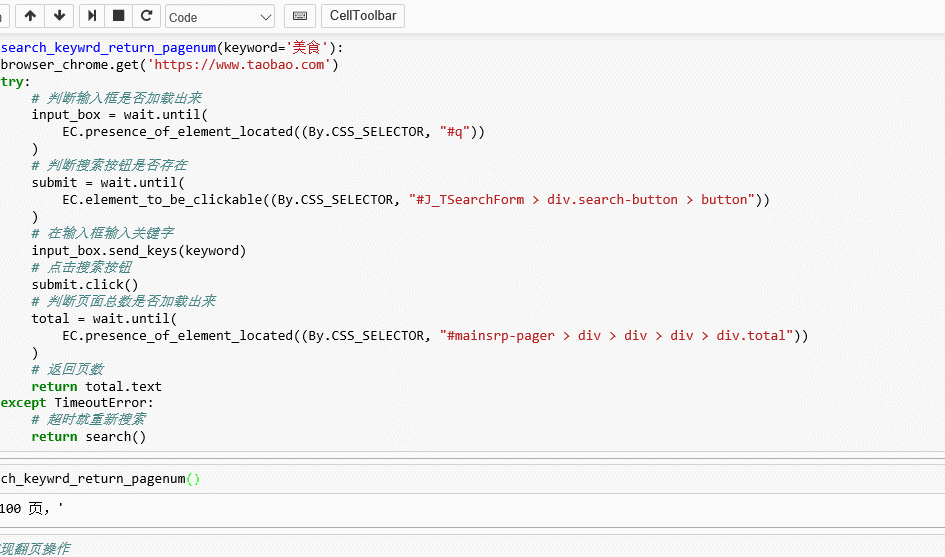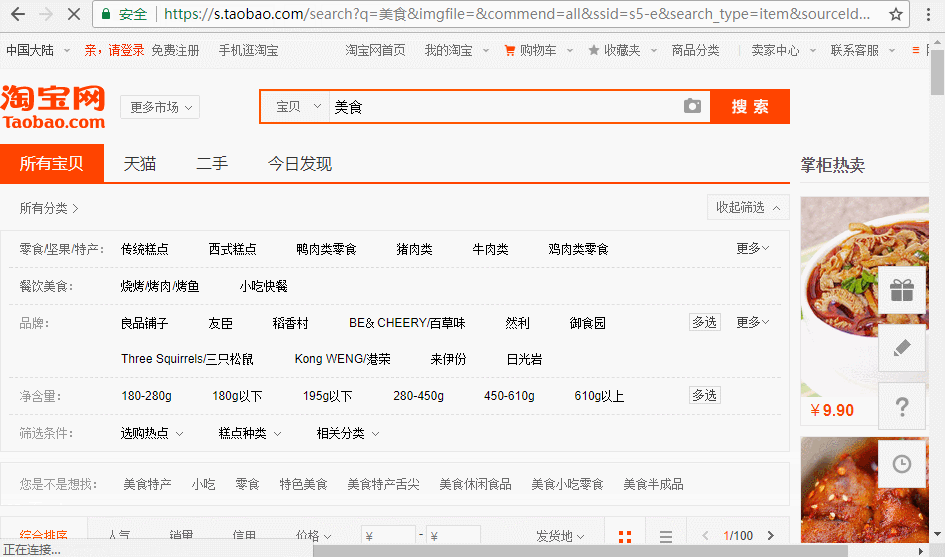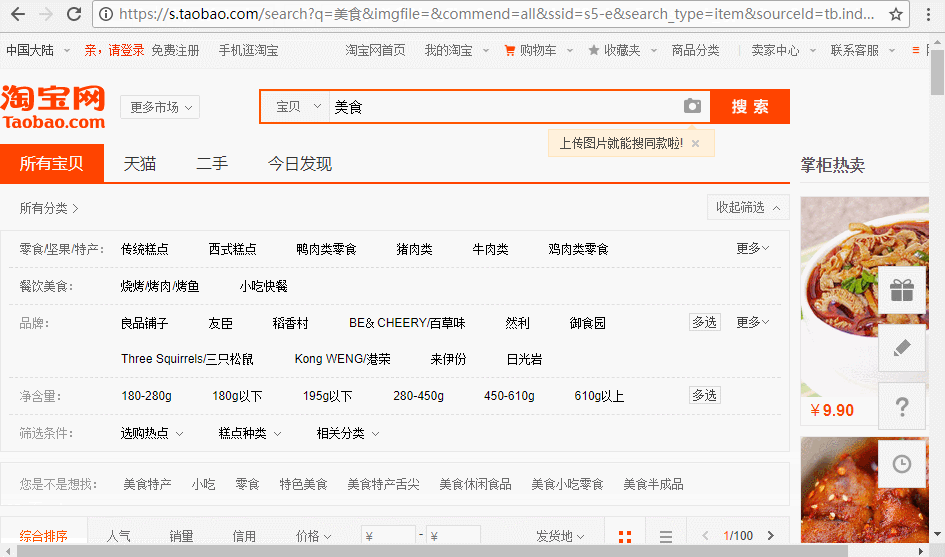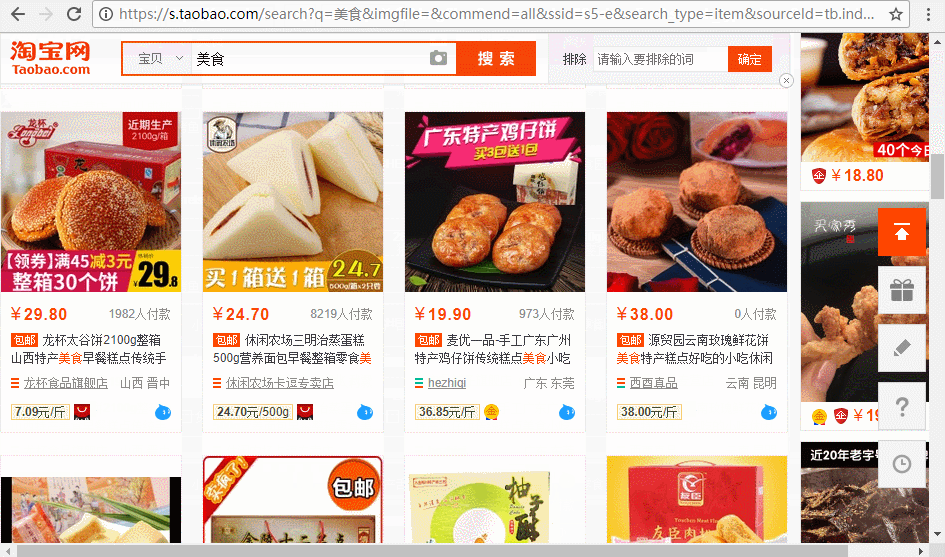
如图,程序运行后自动搜索到美食页面,下面实现翻页。
翻页
代码如下:
def next_page(page_number): try: input_box = wait.until( EC.presence_of_element_located((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > input")) ) submit = wait.until( EC.element_to_be_clickable((By.CSS_SELECTOR, "#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit")) ) # 清除输入框内容 input_box.clear() input_box.send_keys(page_number) submit.click() wait.until( EC.text_to_be_present_in_element((By.CSS_SELECTOR,"#mainsrp-pager > div > div > div > ul > li.item.active > span"),str(page_number)) ) get_products() except TimeoutError: next(page_number) |
运行结果:
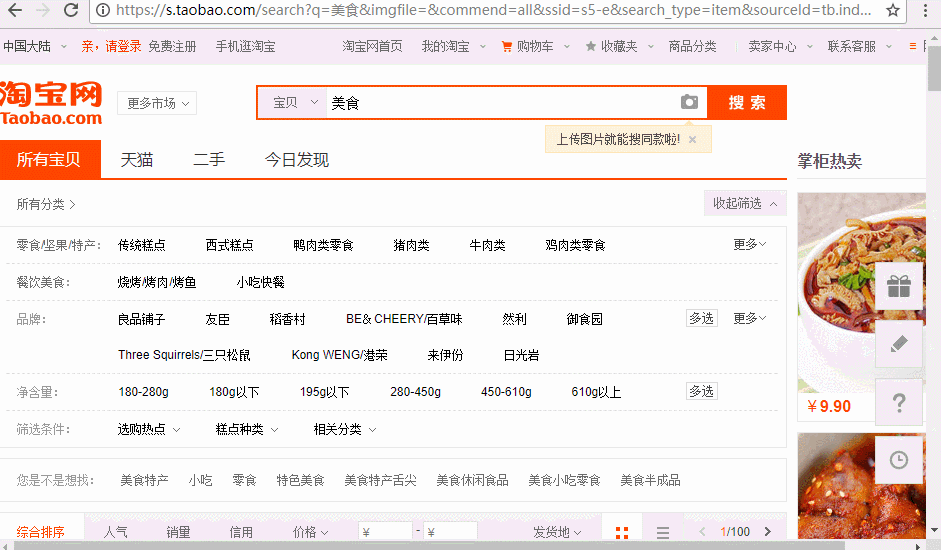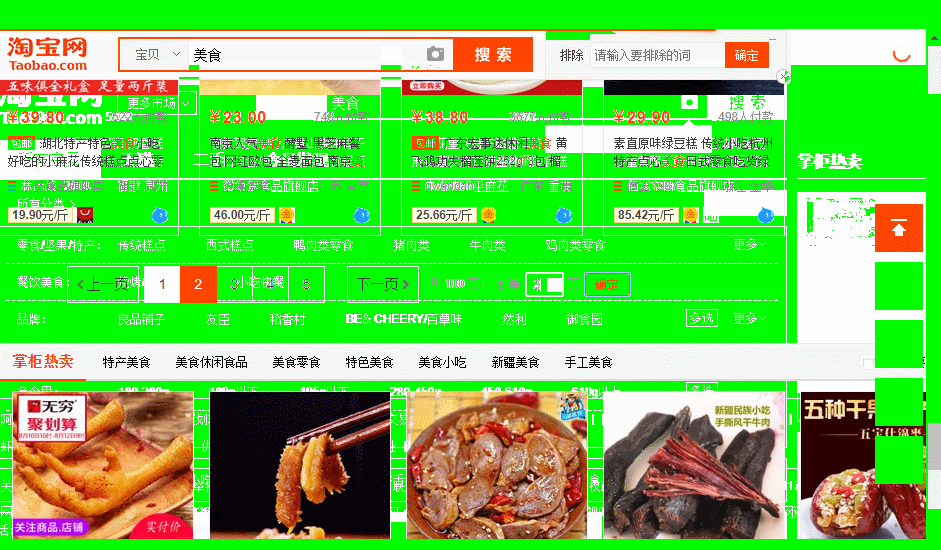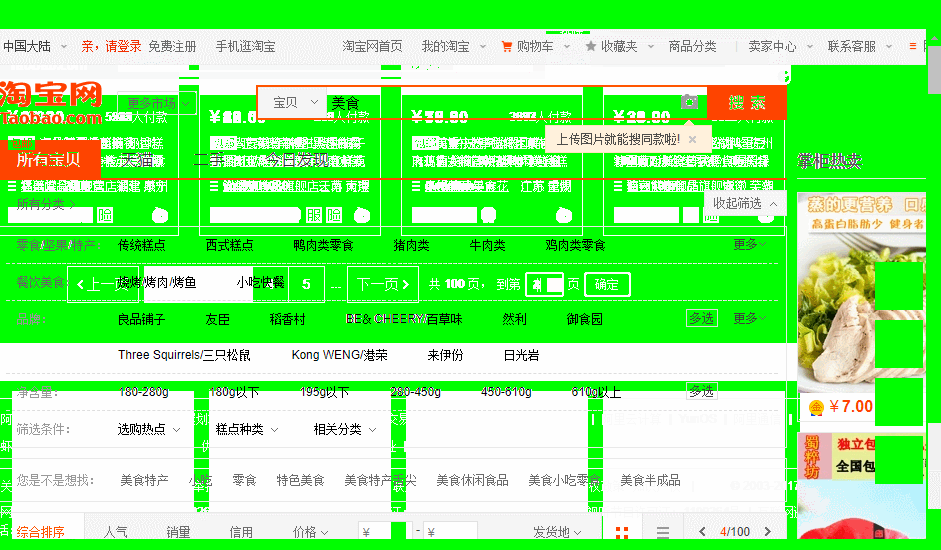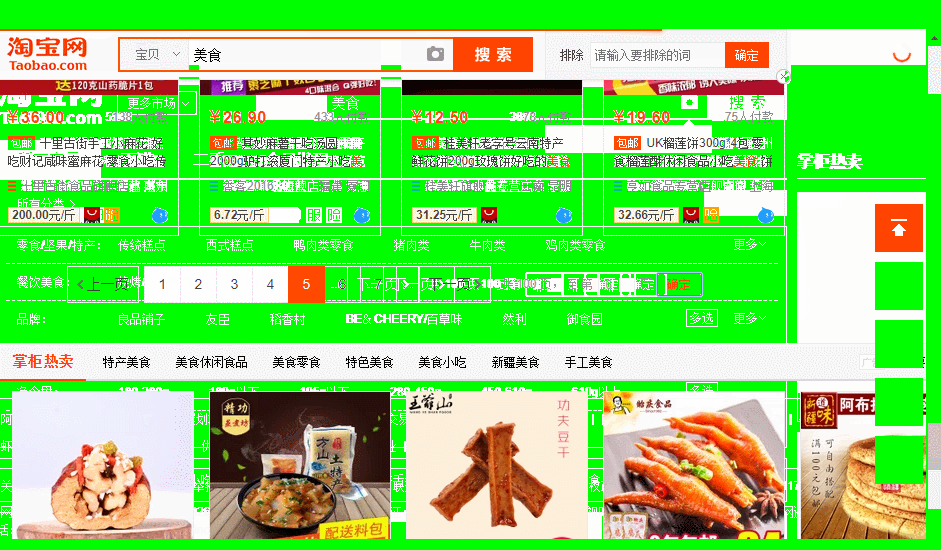
现在,你的程序已经可以自动翻页了
提取信息
接下来,你可以用之前学过的正则表达式,BeautifulSoup等工具提取每个页面的商品信息,对现在的你而言,应该是小菜一碟,这里就不再说明了。

输出提取的信息
存储信息
上面我们只是输出了提取到的商品信息,为了方便以后分析使用,我们可以把它们存储到数据库中。
比如MongoDB,当然还可以是任何你想要使用的其他数据库。
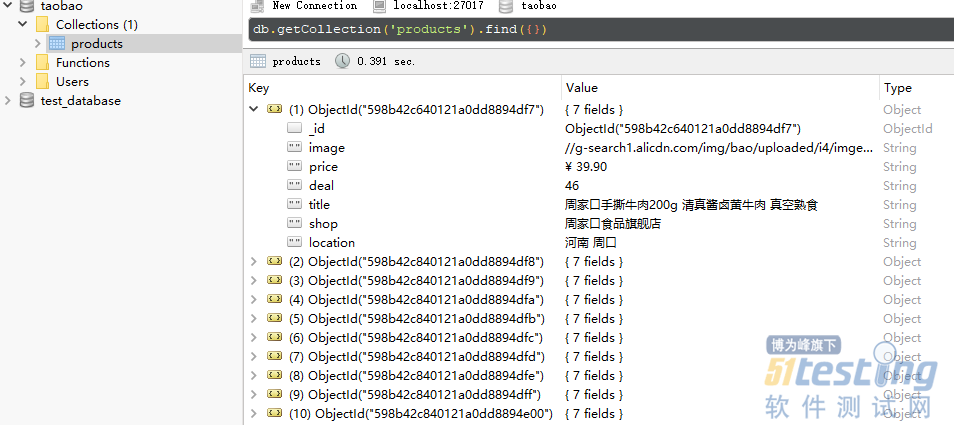
以上。












