发送任务时指定参数
我们在发送任务到队列的时候,使用的是 delay 方法,里面直接传递函数所需的参数即可,那么除了函数需要的参数之外,还有没有其它参数呢?
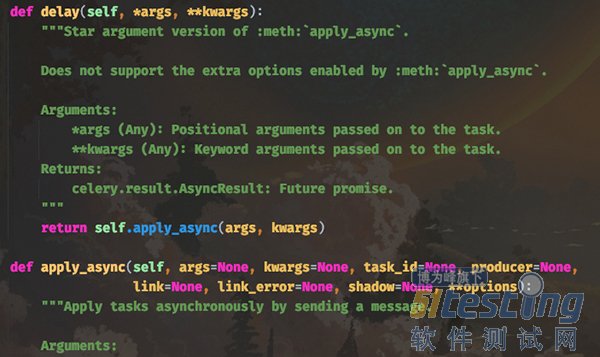
首先 delay 方法实际上是调用的 apply_async 方法,并且 delay 方法里面只接收函数的参数,但是 apply_async 接收的参数就很多了,我们先来看看它们的函数原型:
delay 方法的 *args 和 **kwargs 就是函数的参数,它会传递给 apply_async 的 args 和 kwargs。而其它的参数就是发送任务时所设置的一些参数,我们这里重点介绍一下 apply_async 的其它参数。
·countdown:倒计时,表示任务延迟多少秒之后再执行,参数为整型;
· eta:任务的开始时间,datetime 类型,如果指定了 countdown,那么这个参数就不应该再指定;
· expires:datetime 或者整型,如果到规定时间、或者未来的多少秒之内,任务还没有发送到队列被 worker 执行,那么该任务将被丢弃;
· shadow:重新指定任务的名称,覆盖 app.py 创建任务时日志上所指定的名字;
· retry:任务失败之后是否重试,bool 类型;
· retry_policy:重试所采用的策略,如果指定这个参数,那么 retry 必须要为 True。参数类型是一个字典,里面参数如下:
· max_retries : 最大重试次数,默认为 3 次;
· interval_start : 重试等待的时间间隔秒数,默认为 0,表示直接重试不等待;
· interval_step : 每次重试让重试间隔增加的秒数,可以是数字或浮点数,默认为 0.2;
· interval_max : 重试间隔最大的秒数,即通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数;
· routing_key:自定义路由键,针对 RabbitMQ;
· queue:指定发送到哪个队列,针对 RabbitMQ;
· exchange:指定发送到哪个交换机,针对 RabbitMQ;
· priority:任务队列的优先级,0-9 之间,对于 RabbitMQ 而言,0是最高级;
· serializer:任务序列化方法,通常不设置;
· compression:压缩方案,通常有zlib、bzip2;
· headers:为任务添加额外的消息头;
· link:任务成功执行后的回调方法,是一个signature对象,可以用作关联任务;
· link_error: 任务失败后的回调方法,是一个signature对象;
我们随便挑几个举例说明:
>>> from app import add
# 使用 apply_async,要注意参数的传递
# 位置参数使用元组或者列表,关键字参数使用字典
# 因为是args和kwargs, 不是 *args和 **kwargs
>>> add.apply_async([3], {"y": 4},
... task_id="恋恋",
... countdown=5).get()
7
>>>
查看一下 worker 的输出:
注意左边的时间,16:25:16 收到的消息,但 5 秒后才执行完毕,因为我们将 countdown 参数设置为 5。并且任务的 id 也被我们修改了。
另外还需要注意一下那些接收时间的参数,比如 eta。如果我们手动指定了eta,那么一定要注意时区的问题,要保证 celery 所使用的时区和你传递的 datetime 的时区是统一的。
其它的参数可以自己手动
测试一下,这里不细说了,根据自身的业务选择合适的参数即可。
创建任务工厂的另一种方式
之前在创建任务工厂的时候,是将函数导入到 app.py 中,然后通过 add = app.task(add) 的方式手动装饰,因为有哪些任务工厂必须要让 worker 知道,所以一定要在 app.py 里面出现。但是这显然不够优雅,那么可不可以这么做呢?
# celery_demo/tasks/task1.py
from app import app
# celery_demo 所在路径位于 sys.path 中
# 因此这里可以直接 from app import app
@app.task
def add(x, y):
return x + y
@app.task
def sub(x, y):
return x - y
# celery_demo/app.py
from tasks.task1 import add, sub
按照上面这种做法,理想上可以,但现实不行,因为会发生循环导入。
所以 celery 提供了一个办法,我们依旧在 task1.py 中 import app,但在 app.py 中不再使用 import,而是通过 include 加载的方式,我们看一下:
# celery_demo/tasks/task1.py
from app import app
@app.task
def add(x, y):
return x + y
@app.task
def sub(x, y):
return x - y
# celery_demo/app.py
from celery import Celery
import config
# 通过 include 指定存放任务的 py 文件
# 注意它和 worker 启动路径之间的关系
# 我们是在 celery_demo 目录下启动的 worker
# 所以应该写成 "tasks.task1"
# 如果是在 celery_demo 的上一级目录启动 worker
# 那么这里就要指定为 "celery_demo.tasks.task1"
# 当然启动时的 -A app 也要换成 -A celery_demo.app
app = Celery(__name__, include=["tasks.task1"])
# 如果还有其它文件,比如 task2.py, task3.py
# 那么就把 "tasks.task2", "tasks.task3" 加进去
app.config_from_object(config)
在 celery_demo 目录下重新启动 worker。
为了方便,我们只保留了两个任务工厂。可以看到此时就成功启动了,并且也更加方便和优雅一些。之前是在 task1.py 中定义函数,然后再把 task1.py 中的函数导入到 app.py 里面,然后手动进行装饰。虽然这么做是没问题的,但很明显这种做法不适合管理。
所以还是要将 app.py 中的 app 导入到 task1.py 中直接创建任务工厂,但如果再将 task1.py 中的任务工厂导入到 app.py 中就会发生循环导入。于是 celery 提供了一个 include 参数,可以在创建 app 的时候自动将里面所有的任务工厂加载进来,然后启动并告诉 worker。
我们来测试一下:
# 通过 tasks.task1 导入任务工厂
# 然后创建任务,发送至队列
>>> from tasks.task1 import add, sub
>>> add.delay(11, 22).get()
33
>>> sub.delay(11, 22).get()
-11
>>>
查看一下 worker 的输出:
结果一切正常。
Task 对象
我们之前通过对一个函数使用 @app.task 即可将其变成一个任务工厂,而这个任务工厂就是一个 Task 实例对象。而我们在使用 @app.task 的时候,其实是可以加上很多的参数的,常用参数如下:
name:默认的任务名是一个uuid,我们可以通过 name 参数指定任务名,当然这个 name 就是 apply_async 的参数 name。如果在 apply_async 中指定了,那么以 apply_async 指定的为准;
·bind:一个 bool 值,表示是否和任务工厂进行绑定。如果绑定,任务工厂会作为参数传递到方法中;
· base:定义任务的基类,用于定义回调函数,当任务到达某个状态时触发不同的回调函数,默认是 Task,所以我们一般会自己写一个类然后继承 Task;
· default_retry_delay:设置该任务重试的延迟机制,当任务执行失败后,会自动重试,单位是秒,默认是3分钟;
· serializer:指定序列化的方法;
当然 app.task 还有很多不常用的参数,这里就不说了,有兴趣可以去查看官网或源码,我们演示一下几个常用的参数:
# celery_demo/tasks/task1.py
from app import app
@app.task(name="你好")
def add(x, y):
return x + y
@app.task(name="我不好", bind=True)
def sub(self, x, y):
"""
如果 bind=True,则需要多指定一个 self
这个 self 就是对应的任务工厂
"""
# self.request 是一个 celery.task.Context 对象
# 获取它的属性字典,即可拿到该任务的所有属性
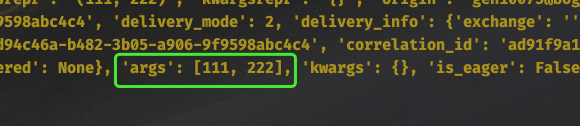
print(self.request.__dict__)
return x - y
其它代码不变,我们重新启动 worker:
然后创建任务发送至队列,再由 worker 取出执行:
>>> from tasks.task1 import add, sub
>>> add.delay(111, 222).get()
333
>>> sub.delay(111, 222).get()
-111
>>>
执行没有问题,然后看看 worker 的输出:
创建任务工厂时,如果指定了 bind=True,那么执行任务时会将任务工厂本身作为第一个参数传过去。任务工厂本质上就是 Task 实例对象,调用它的 delay 方法即可创建任务。
所以如果我们在 sub 内部继续调用 self.delay(11, 22),会有什么后果呢?没错,worker 会进入无限递归。因为执行任务的时候,在任务的内部又创建了任务,所以会死循环下去。
当然 self 还有很多其它属性和方法,具体有哪些可以通过 Task 这个类来查看。这里面比较重要的是 self.request,它包含了某个具体任务的相关信息,而且信息非常多。
比如当前传递的参数是什么,就可以通过 self.request 拿到。当然啦,self.request 是一个 Context 对象,因为不同任务获取 self.request 的结果肯定是不同的,但 self(任务工厂)却只有一个,所以要基于 Context 进行隔离。
我们可以通过 __dict__ 拿到 Context 对象的属性字典,然后再进行操作。
最后再来说一说 @app.task 里面的 base 参数。
# celery_demo/tasks/task1.py
from celery import app
from app import Task
class MyTask(Task):
"""
自定义一个类,继承自celery.Task
exc: 失败时的错误的类型;
task_id: 任务的id;
args: 任务函数的位置参数;
kwargs: 任务函数的关键字参数;
einfo: 失败时的异常详细信息;
retval: 任务成功执行的返回值;
"""
def on_failure(self, exc, task_id, args, kwargs, einfo):
"""任务失败时执行"""
def on_success(self, retval, task_id, args, kwargs):
"""任务成功时执行"""
print("任务执行成功")
def on_retry(self, exc, task_id, args, kwargs, einfo):
"""任务重试时执行"""
# 使用 @app.task 的时候,指定 base 即可
# 然后任务在执行的时候,会触发 MyTask 里面的回调函数
@app.task(name="地灵殿", base=MyTask)
def add(x, y):
print("加法计算")
return x + y
重新启动 worker,然后创建任务。
指定了 base,任务在执行的时候会根据执行状态的不同,触发 MyTask 里面的不同方法。