想用 Excel 进行自动化冒烟测试?用这个就对了
上一篇 /
下一篇 2021-10-25 11:11:25
/ 个人分类:测试
tablib 是 requests 库作者常年维护的一个 python 第三方库,可以操作 Excel 等多种文件格式变成一种通用数据集。
tablib 支持的主要数据格式有:
- xls, 老版 office 的 Excel 文件格式;
- xlsx 系列,新版 office 文件格式;
- JSON
- YAML
- HTML
- CSV
- df,(pandas 的 DataFrame, 需要安装 pandas)
tablib 操作
测试用例的基础使用非常简单,你只需要记住以下 2 点:
1、使用 import_set 导入 Excel 文件
with open('demo.xls', 'rb') as f:
# 接受 2 个参数,读出来的数据和读取的文件格式
data = tablib.import_set(f.read(), 'xls')
print(data)
2、使用 DataSet 创建 Excel 表格
data = tablib.Dataset(*data_list, headers=headers,title='测试用例')
现在来进行更精确的操作:
行列数据操作
先通过加载 Excel 文件获取到数据
a = tablib.import_set(f.read(), 'xls')
a 得到的是一个列表,每个元素是每一行数据。
1、获取行
# 获取第一行第一列
print(a[0][0])
# 获取第一行的 url 列
print(a.dict[0]['url'])
# 获取前 2 行
print(a[:2])
2、获取列
3、插入行
with open('demo_book.xls', 'rb+') as f:
a = tablib.import_set(f.read(), 'xls')
print(a)
# 添加行
a.append(['zhiwang', 'put', '成功'])
# 在指定行插入
a.insert(2,['zhiwang', 'put', '成功'])
with open('demo_book.xls', 'wb') as f:
f.write(a.xls)
print(a)
4、插入列
# 在最后添加
a.append_col(['成功','失败', '失败'], header='actual_result')
# 在指定位置添加列
a.insert_col(3,['成功','失败', '失败'], header='actual_result')
5、修改
# 修改某一行数据
a[0] = ('baidu', 'put', 'shibai', 'shibai')
# 修改某个具体的数据
a._data[0][0] = 'wobuzhidao'
注意:不要在代码里直接操作 a._data, 可以封装成方法。
冒烟用例执行
在测试过程中,我们经常需要执行冒烟用例。或者给测试用例打标签,比如登录功能,成功用例,异常用例等等。tablib 通过 tags 关键字方便删选指定的测试用例来执行。
1、添加 tags
# 添加标签
a.append(['buzhi', 'put', 'c','c'], tags=['成功'])
# 获取所有‘成功’的测试用例
success = a.filter(tag='成功')
2、修改 tags
# 将测试用例的标签修改成‘失败’
a._data[0].tags = ['失败']
# 获取所有‘失败’ 的测试用例
failed = a.filter(tag='失败')
print(failed)
3、去除重复元素
灵活的格式切换
测试数据最常用的功能是需要切换格式,比如把 Excel 格式的数据切换成 YAML , 这个在接口
自动化测试框架 httprunner 中经常用到。还是用 a 来表示 DataSet 数据:
1、存储为 YAML 文件:
with open('demo.yml', 'w', encoding='utf-8') as f:
f.write(a.yaml)
2、导入 YAML 文件:
with open('demo.yml', 'r') as f:
a = tablib.Dataset().load(f.read(), format='yaml')
print(a.html)
效果:
651 x 193
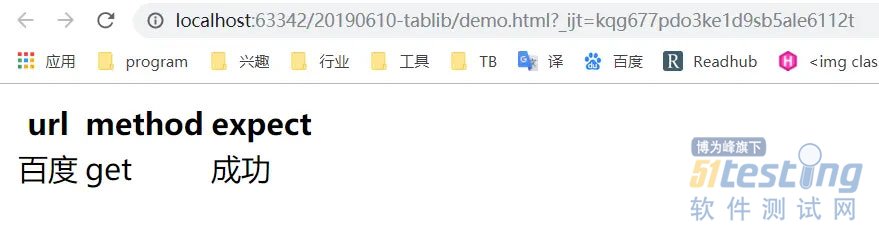
3、导出为 HTML :
with open('demo.html', 'w', encoding='utf-8') as f:
f.write(data.html)
效果:
728 x 188 879 x 227
4、导出为 json:
with open('demo.json', 'w', encoding='utf-8') as f:
f.write(data.json)
效果:
[
{
"url": "baidu",
"method": "get",
"expect": "failed"
},
{
"url": "lemon",
"method": "post",
"expect": "success"
}
]
其他常用方法
- lpop(),lpush(row, tags=[]),lpush_col(col, header=None) 是对列的相关操作
- pop(),rpop(),rpush(row, tags=[]),rpush_col(col, header=None) 是对行的相关操作
- remove_duplicates() 去除重复的记录
- sort(col, reverse=False) 根据列进行排序
- subset(rows=None, cols=None) 返回子 Dataset
- wipe() 清空 Dataset,包括表头和内容
总结
tablib 这个库非常灵活,用法非常好记,完全符合我们对 Excel 的理解。非常适用于 python 自动化测试的用例数据管理。只有一个缺点:中文资料太少。后面我会翻译一些优秀的英文文档,让更多人把这个优秀的库用起来。
收藏
举报
TAG: