在这篇
文章中,我们将比较Pandas 和data.table,这两个库是
Python和R最长用的数据分析包。我们不会说那个一个更好,我们这里的重点是演示这两个库如何为数据处理提供高效和灵活的方法。
我们将介绍的示例是常见的数据分析和操作操作。因此,您可能会经常使用它们。
我们将使用Kaggle上提供的墨尔本住房数据集作为示例。我将使用谷歌Colab(Pandas )和RStudio(data.table)作为开环境。让我们首先导入库并读取数据集。
# pandas import pandas as pd melb = pd.read_csv("/content/melb_data.csv") # data.table library(data.table) melb <- fread("datasets/melb_data.csv") |
示例1
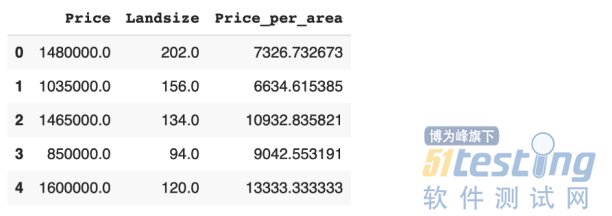
第一个示例是关于基于数据集中的现有列创建新列。这是特征工程过程中常见的操作。这两个库都提供了完成此任务的简单方法。
# pandas melb["Price_per_area"] = melb["Price"] / melb["Landsize"] # data.table melb[, Price_per_area := Price / Landsize] |
示例2
对于第二个示例,我们通过应用几个过滤器创建原始数据集的子集。这个子集包括价值超过100万美元,类型为h的房子。
# pandas subset = melb[(melb.Price > 1000000) & (melb.Type == "h")] # data.table subset <- melb[Price > 1000000 & Type == "h"] |
对于pandas,我们提供dataframe的名称来选择用于过滤的列。另一方面,data.table仅使用列名就足够了。
示例3
在数据分析中使用的一个非常常见的函数是groupby函数。它允许基于一些数值度量比较分类变量中的不同值。
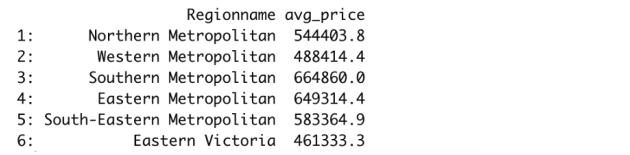
例如,我们可以计算出不同地区的平均房价。为了使示例更复杂一些,我们还对房子类型应用一个过滤器。
# pandas melb[melb.Type == "u"].groupby("Regionname").agg( avg_price = ("Price", "mean") ) # data.table melb[Type == "u", .(avg_price = mean(Price)), by="Regionname"] |
pandas使用groupby函数执行这些操作。对于data.table,此操作相对简单一些,因为我们只需要使用by参数即可。
示例4
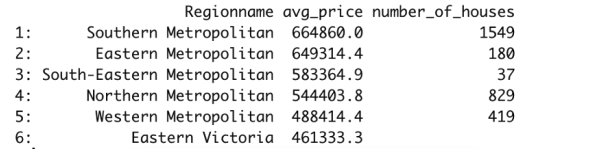
让我们进一步讨论前面的例子。我们求出了房屋的平均价格,但不知道每个地区的房屋数量。
这两个库都允许在一个操作中应用多个聚合。我们还可以按升序或降序对结果进行排序。
# pandas melb[melb.Type == "u"].groupby("Regionname").agg( avg_price = ("Price", "mean"), number_of_houses = ("Price", "count") ).sort_values(by="avg_price", ascending=False) # data.table > melb[ Type == "u", .(avg_price = mean(Price), number_of_houses=.N), by="Regionname" ][order(-avg_price)] |
我们使用计数函数来获得每组房屋的数量。”。N”可作为data.table中的count函数。
默认情况下,这两个库都按升序对结果排序。排序规则在pandas中的ascending参数控制。 data.table中使用减号获得降序结果。
示例5
在最后一个示例中,我们将看到如何更改列名。例如,我们可以更改类型和距离列的名称。
类型:HouseType
距离:DistanceCBD
数据集中的distance列表示到中央商务区(CBD)的距离,因此最好在列名中提供该信息。
# pandas melb.rename(columns={"Type": "HouseType", "Distance": "DistanceCBD"}, inplace=True) # data.table setnames(melb, c("Type", "Distance"), c("HouseType", "DistanceCBD")) |
对于熊猫,我们传递了一个字典,该字典将更改映射到rename函数。 inplace参数用于将结果保存在原始数据帧中。
对于data.table,我们使用setnames函数。 它使用三个参数,分别是表名,要更改的列名和新列名。
总结
我们比较了pandas和data.table在数据分析操作过程中常见的5个示例。这两个库都提供了简单有效的方法来完成这些任务。
在我看来,data.table比pandas简单一点。
需要指出的是,我们在本文中所做的示例只代表了这些库功能的很小一部分。它们提供了许多函数和方法来执行更复杂的操作。