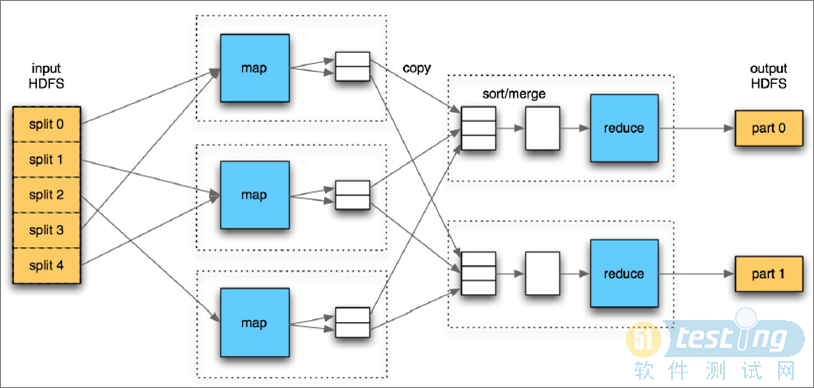
РДЬдБІжЎЧАОЭжЊЕРhadoopЃЌЕНЬдБІКѓЕквЛИіжмФЉОЭжЊЕРСЫmapreduceЃЌжБЕНЧАМИЬьЮвЖдmapreduceЕФРэНтШдЭЃСєдквЛеХЭМЦЌЩЯЃЌФЧеХЭМЦЌЕФФкШнОЭЪЧЖдЪфШыНјааЗжЦЌЃЌвВОЭЪЧmapЕФЙ§ГЬЃЌОЙ§ДІРэМЦЫуКѓдйИљОнЯргІЕФКЏЪ§ЙцдђЭГМЦНсЙћОЭЪЧreduceЃЌОЙ§reduceКѓЪфГіНсЙћЁЃЙУЧвВЛТлетжжРэНте§ШЗгыЗёЃЌжСЩйmapКЭreduceЮвЖМУЛХЊЧхГўЃЌдѕУДИіmapЃЌдѕУДИіreduceЃЌШчНёТ§Т§ЕРРДЁЃ
ЪзЯШmapreduceВЂВЛжЛmapКЭreduceСНИіНзЖЮЃЌвЛАуШчЯТЃЈвд[a,b,c,a,b,b,c,a]ЃЉЃК
1.inputНзЖЮЃКИљОнЪфШыЮФМўКЭmapЪ§ОнЯЕЭГВњЩњЯргІЕФЮФМўПщЁЃвЛАуЫЕРДгаЖрЩйИіЪфШыОЭгаЖрЩйИіmapЃЌЮФМўПщblockЕФДѓаЁЮЊ64MЛђеп128MЁЃЃЈДѓЕФЮФМўдкЧаИюЪБПЩФмФГвЛИіblockУЛга64MЃЌЕЋЪЧВЛФмГЌЙ§64MЃЌ
ШежОЮФМўПЩвдИљОнЛЛааЗћХаЖЯЁЃЕБШЛвВВЛЛсГіЯжПчЮФМўЧаИюЃЉ
[a,b,c,a,b,b,c,a]->[a,b,c,a],[b,b,c,a]
2.MapНзЖЮЃКУПИіMapИљОнгУЛЇЕФЪфШыЕФkey-valueЖдзЊЛЏГЩаТЕФkey-valueЖдЁЃ
M1:[a,1],[b,1],[c,1],[a,1]
M2:[b,1],[b,1],[c,1],[a,1]
3.shuffle&sortНзЖЮЃКЯЕЭГЖдMapЪфГіНјааХХађВЂЗЂЫЭЕНЯргІЕФreduceЩЯЁЃећРэКЯВЂХХађЖМдкБОЛњЩЯНјааЁЃ
M1:[a,2],[b,1],[c,1]
M2:[b,2],[a,1],[c,1]ЃЈcombinerЃКОЙ§КЯВЂКѓПЩвдМѕЩйshuffleЪ§СПЃЉ
R1:[a,2],[a,1]
R2:[b,2],[b,1],[c,1],[c,1](partitioner:ЖдmapperНсЙћЗжХфЕНВЛЭЌreducerЃЌвЛАуЪЧИљОнreducerЪ§ФПзіhash)
4.reduceНзЖЮЃКАбЫљгаЯрЭЌЕФkeyЕФМЧТМКЯГЩвЛИіkey-valueЖдЁЃ
O1:[a,3]
O2:[b,2],[c,2]
5.outputНзЖЮЃКАбЪфГіНсЙћаДЕНdfs
КУРВЃЌФПЧАЮвжЊЕРСЫОЭетУДаЉСЫЃЌЫфШЛБШдРДЕФРэНтвЊЧхЮњСЫЃЌЕЋЪЧmapreduceШдгаИќЩюШыЕФжЊЪЖЕШД§ШЅСЫНтЃЌТЗТўТўЦфаодЖйтЃЌЮсНЋЩЯЯТЖјЧѓЫїЃЁ