
1、优化改良无处不在
如果要回顾即将远去的2010年,公众最关注的话题有哪些,相信“转基因水稻”必定榜上有名。对于这些通过基因工程,被人为创造出来的新物种,科学 家虽然能保证高产与抗虫害能力,但是不能证明食用后对人体没有损害,这多少有些令人尴尬;而农业部在前景不明朗情况下批准商业化种植,则把公众推向了高风 险境地。不过,抛开转基因技术所带来的食品安全风险,它与杂交、辐射变异在本质上是类似的,都是通过尝试着的改变生物的基因,来选拔良种。由于人们对于基 因如何表达为生物性状的机理不是完全了解,加之基因在杂交过程中本身存在随机因素。这使得寻找良种的过程中需要不断尝试。因此,不论是孟山都公司通过基因 工程来改造水稻种子,还是袁隆平老师通过不同水稻品种的杂交来培育优质水稻,其实在方法论上都是一致的:挑选一些样本,然后施加各种各样的变化因素,通过 观察,找到最佳的样本。

图1. 袁隆平的杂交水稻实验,可以看作是一种BTS实践(图片来自网络)
2、搜索产品的优化
在互联网领域尤其是搜索领域,我们同样也面临着与选育良种类似的问题,即如何对一个搜索产品施加各种变化,从而发现效果最好的版本。说的再具体一点,为了寻找到效果最好的搜索产品,我们应该尝试着去改变搜索产品的哪些方面,以及在每个方面施加哪些可能的变化。
这问题不像看上去的那样简单。首先,这个效果的定义,含义可就丰富了。淘宝搜索首先要考虑搜索结果与用户query之间的相关性;除了相关性要求之 外,对于淘宝搜索而言,是不是能有效的促进成交,也是要重点考虑的效果之一;此外,如果在搜索结果中,大量存在假冒伪劣产品,那这个效果也是要打折扣的; 另外,如果大部分的搜索结果里,都是那些大卖家在抛头露面,中小卖家没有展现机会,对于淘宝生态圈的长期发展也是不利的。因此,淘宝搜索所考虑的效果问题 要比一般意义上的搜索引擎更加复杂。其次,搜索产品的哪些方面可以做改动,如果要一一列举就太多了。事实上,搜索产品的任何一个地方的不完善,都有可能降 低搜索产品的整体效果。笔者试着将淘宝搜索产品的可变化因素整理成一个图,希望各位看官能有一个感性的认知。

图2. 淘宝搜索产品的可变化因素
3、分桶测试 (Bucket Testing, BTS)
诸位看官可能已经意识到了,如何优化一个搜索产品,实际情况应该比我上面说的更加复杂,这真是一个坏消息;不过我们也有一个好消息,因为对于这个问题的答案,业界已经有答案了,这就是分桶测试(bucket testing),简称BTS。
所谓的分桶测试,是让不同的用户在访问特定的互联网产品的时候,由系统来决定用户的分组号(我们称为bucket id),然后根据分组号,令用户看到的是不同的产品版本,用户在不同版本产品下的行为将被记录下来,这些行为数据通过数据分析形成一系列指标,而通过这些 指标的比较,最后就形成了各版本之间孰优孰劣的结论。
3.1 A/B测试 (A/B Testing)
分桶测试的最简单形式,称为A/B
testing。即设定一个基准桶,再设定一个或以上的测试桶。然后考察测试桶与基准桶之间在各项指标上的差异,最后确定测试桶的效果。这种方法论,很容
易在现实生活中找到影子。其实,改革初期建立的深圳特区,就是一场伟大的A/B
testing,基准桶就是中国内地,测试桶就是深圳,当时各自的用户量是9亿 vs 30万(以当时的人口计算)。对于A/B
testing而言,测试桶的用户量、流量都不会太大,这是为了确保BTS万一失败,对于整体系统的影响尽量小。当然,测试桶的用户量、流量也不能太少,
否则测试效果容易受到未知因素的干扰,而变得不稳定。对于A/B
testing而言,判断测试组与基准组孰优孰劣非常简单,只要将二者的指标进行对比即可。但是,如果版本中包含多个因素,那么确定每个因素的贡献,就不
好评估了。这就好比,我们不能仅仅根据内地与深圳的GDP差异,就能断定是因为当时良好的投资环境,还是地理因素,或其它什么因素,是导致了深圳当时成功
的主要因素。所以,利用A/B测试,我们往往只能知道how,而不能知道why。

图3. 建立经济特区,本质就是 A/B 测试(图片来自网络)
如果经济特区的例子还是不够直接的话,我们来看下奥巴马同学的例子吧。奥巴马的竞选团队如何在总统竞选中将互联网手段发挥到极致的,我们就不费口水 介绍了,单说一下他们是如何改善竞选网站的吧。看下图,在奥巴马竞选网站上有一个赠送竞选T恤的页面,用户只要捐款达到一定数额就会赠送一件T恤。显然, 如果T恤广告图片(下图红框处)足够抓眼球的话,那捐款率可就ceng ceng的往上涨啊。所以奥巴马团队在广告图片的设计上可是花了不少心血,方法嘛自然是A/B测试咯,他们一共为测试组设计了4种变化(A~D),然后借 助于 Google Website Optimizer 对用户点击行为的分析,选出最佳的形式。
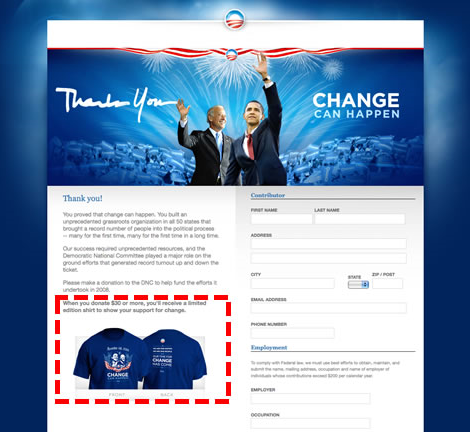

图4. 奥巴马竞选团队利用A/B测试来改进竞选宣传的效果(图片来自网络)
3.2 多变量测试 (Multivariate Testing)
分桶测试的高级形式,是多变量测试。在多变量测试中,每个可以改变的地方称为因素,而每种因素的可能具有的状态称为水平。比如,你想同时改变某个搜索产品
的按钮颜色、排序算法、索引数据这3个地方,那你需要一个3因素的多变量测试。如果,按钮的颜色为3种,那“按钮颜色”这个因素是3水平的。多变量测试允
许你在同一时间测试多个要素处于不同水平时对于搜索产品的影响。通过多变量测试,你能十分清楚的看到不同的变化组合,对最终效果的影响。
举例而言,如果对某个搜索产品进行BTS测试的范围为:3种按钮颜色、2种排序算法和2种索引数据,那么该如何确定效果最佳的搭配呢?一般,我们会 进行排列组合,产生不同的版本,使得每个版本对应一种水平的组合,这样我们就要构造3*2*2=12种版本参加BTS测试。接下来我们只要确定好每个版本 的流量分配即可,即哪些桶对应哪个版本。
最后,也是最有难度的地方在于,如何通过各版本的指标分析,来确定哪个版本最好、每个因素贡献程度以及结论的可靠性。这将比A/B测试要复杂的多,建议各位看官在有兴趣尝试之前,回顾一下统计学的假设检验、实验设计方面的知识。限于篇幅,这里我们就不展开。
最后说明下,多变量测试的威力在于同一时间内可以进行多个因素的测试,可以为我们节省时间,但在使用这个工具的时候,切忌贪心,不要同时进行太多因 素的测试。这是因为,在一定时间内,网络流量是有限的,而同时进行太多的测试,就要创建大量的版本,这将摊薄每个版本能够得到的流量。而流量不足时,会导 致统计指标的可靠性变差。
从“非诚勿扰”看淘宝算法效果测试, http://www.searchtb.com/2010/12/an-introduction-to-taobao-bts.html
从“非诚勿扰”看淘宝算法效果测试
大 家应该都了解最近被讨论的热火朝天甚至有些过气的相亲节目“非诚勿扰”。这个节目让我们看到人性的差别,增加了我们茶余饭后的话题,也让我们了解到现在找 对象是多么困难的一件事:24名佳丽争抢一位男嘉宾。经过一段时间的观看,我们甚至可以从技术的角度去分析这个节目成功的原因。
在“非诚勿扰”中,策划们为这个节目做了很多设计,首先定义了若干角色“24名女佳丽,一名男嘉宾,一名主持,还有两个评委”。还设计了一个完整的 流程,男嘉宾一开始对印象最好的女生投票,接着通过三段视频资料与女嘉宾们交流,女嘉宾通过按钮进行投票。场下的两位评委用他们专业的知识,影响整个投票 的过程。整个节目策划,设计流程及逻辑无可挑剔。其背后的设计思想,竟然和淘宝算法的测试系统(我们称之为BTS系统)有异曲同工之妙。
现在让我们看看淘宝的BTS系统,淘宝的任何一次算法调整都不是拍脑袋决定的,我们把这个决定权交给用户。淘宝的工程师们为此设计了一套算法评估系 统帮助用户对我们的算法进行投票,投票的结果帮助我们了解那种算法最有利于改善用户体验。在设计上,通常是取得用户在cookie中的ID,或相关能代表 用户唯一标识的数据,进行求余处理,把他们平均分为N份,一般这个值的取值范围需要考虑到流量的需要,保证每份流量的大小足够有统计的意义。每个用户因此 被贴上了处理后的标签。不同标签的用户会被分配到不同的算法。用户在算法中产生的不同行为将会被数据平台记录下来,产生用于分析的报表。算法工程师会根据 报表的不同表现进一步调整算法。整个体系结构如下图:

上面的系统结构图相当的技术化和枯燥,我们是怎么看出它们的相似之处呢?BTS系统中不同的算法相当于非诚勿扰的24个不同佳丽,用户的选择就像是 我们的男嘉宾。而评委呢?他们就是我们的算法工程师,在必要的时候会做出一些调整影响互相之间的表现。流程基本相同,就是不同的男嘉宾(用户)对场上的 24个女嘉宾(算法)进行沟通,体验不同女嘉宾之间的差别,经过不同男嘉宾的沟通,让我们了解到场上的女嘉宾那位是最符合目前主流的价值观(也就是我们认 为对用户最好的算法)。当然,结果上还是稍微有不同,被认可并带走的每一位女嘉宾,都是凭着心里的感觉。而淘宝算法的每一次改变,背后都需要大量用户数据 的支持和对比分析。
实际上,“非诚勿扰”并非完全没有数学分析。这个节目就出现过一位“数据帝”,统计分析了节目开播以来所有出现的内容,以指导他上场择偶的成功率。
例如下面两个统计图,统计数据表明该节目的牵手成功率比想象的高64%的成功率,但两情相悦的比例比较低,只有9%。看,数据的分析真的是无处不在,甚至
关系到每个人的终身幸福。
由此可见,BTS系统其实和“非常勿扰”的相亲流程是这么的一致。不过BTS能做到的可不只这些。在非诚勿扰中,每个佳丽都有自己的性格,外表和兴 趣爱好。这意味着很难找到完全满意天作之合的情侣,这个概率在节目里面只有2%。BTS系统却能完美的解决这些问题,我们可以让算法自由组合,找出一个用 户最满意的算法模型。
桶测试的原理看似非常简单,说白了就是目前非常流行的A/B TEST的扩展。然而这个系统要做的好,细节远不止这些。有大量的工作值得我们去研究和完善。
我们需要考虑这个系统的配置效率。每一天淘宝都有大量的算法在线上做测试,配置系统的效率变得非常关键。淘宝的搜索是非常庞大的一套系统,各种形式
的算法分散在不同的系统当中。假设每一次的算法测试都需要对不同的系统进行修改,将会导致效率底下,而且极易出错。因此,我们需要对配置进行集中的管理,
其目的是为了所有的配置在一个地方修改就能改变整个系统的测试。
需要一个多纬度的数据分析支撑系统。每个算法都有可能基于不同目的进行测试,因此数据的分析和统计的能力就变得异常重要。算法的测试往往在几天内就必须完成,对于数据分析系统的要求必须能快速配置而不需要对数据的分析进行二次开发。
流量的大小及流量的稳定性。我们必须保证用户被平均分配到每个桶,每个用户群的行为没有太大的差异性。整个系统需要保证每个桶的流量足够大,数据的丰富程度具备统计意义。桶与桶之间的数据表现稳定。
对于算法人员需要有足够的数据挖掘经验,能在数据的微小差别中找到算法调整的线索。
淘宝在BTS系统上注入了大量的时间和精力去完善,然而A/B
Testing的精髓并不在于如何构建一套测试系统,而是如何去获取用户的行为数据,以及对大量的数据进行分析。我们的算法工程师是怎样通过数据的细节找
到那个算法更适合用户的需要呢?更吸引人的细节,请听下回分解。
