问题描述:对于测试来说最怕遇到的就是不可重现的严重级bug,在执行的不经意间出现了一个crash的bug,然后无论如何尝试都无法重现,当遇到这种问题时作为一个测试应该如何处理?
精彩答案:
会员 Christina_LL :
在软件测试中经常会出现很多偶尔出现的缺陷,也就是说不是100%的能复现,对于这样的缺陷,该怎么处理呢?
先看看能复现的缺陷的处理流程是什么样的,能复现的缺陷处理流程是:
(1)考虑到各方面的因素来判断缺陷的优先级别和严重级别:
(2)根据缺陷的优先级别决定什么时候fix这个缺陷-〉
(3)集成fix的代码-〉
(4)验证fix是否成功,并试图验证这个fix是否有负面影响。-〉
(5)Fix是成功的,没有负面影响或者负面影响在可接受范围内,那这个缺陷就可以close了;如果fix不成功,或者有严重的负面影响,需要考虑是否 rollback。
其实能复现的缺陷处理流程同样适用于处理偶尔出现的缺陷,只是具体的操作有些区别而已。
(1) 考虑到各方面的因素来判断缺陷的优先级别和严重级别:
首先判断严重级别:严重级别比较容易判断,和其他能复现的缺陷一样处理。
然后判断优先级别,就需要看对用户的影响。对于能复现的缺陷,我们能很容易的知道用户碰到这个缺陷的概率,也就能很容易的判断这个缺陷对用户的影响,那对于偶尔出现的缺陷,同样需要判断这个缺陷对用户的影响。判断优先级别除了考虑缺陷的严重级别,还需要知道这个缺陷能被复现的概率,这就需要去复现这个缺陷。一个偶尔出现的缺陷在有限的试图复现次数里,比如试图复现10次,可能无法成功复现,但是如果试图复现10000次,可能能成功复现20次。这就需要搜集大量的数据 ,来发现这个缺陷的复现概率。怎么搜集复现概率呢,有很多种方法,可以暂缓处理这个缺陷,看后来这个缺陷是否能出现,如果从项目初期到项目结束,这个缺陷就出现一次,那完全可以忽略这个缺陷;可以刻意的安排测试员复现这个缺陷,不断重复的去复现这个缺陷,这个时候如果有开发人员来分析哪些操作容易导致这个缺陷出现,测试人员通常更容易成功复现,测试人员最好把软件连着trace来试图复现缺陷,这样如果成功复现了,就拿到有效的信息来给开发人员分析;也可以在终端用户测试的时候,让终端用户测试人员注意有没有碰到这样的缺陷,终端用户测试能最真实的模仿实际用户的行为,如果几个月的终端用户测试都没有发现这个缺陷,那大可以放心的忽略这个缺陷;相反,如果终端用户测试里频繁碰到这个缺陷,那这个缺陷对用户的影响就很大,就需要被重视。
(2)根据缺陷的优先级别决定什么时候fix这个缺陷
这一步和常规的缺陷处理流程一样,就是开发人员去分析得到的有效信息,然后找相应的解决方案。不过需要提醒的是,通常偶尔出现的缺陷不是一个一个分析处理的,而是一批同类型的缺陷一块处理。通常会等到不可重现的缺陷积累到一定的量的时候再成批的处理。只所以这样处理,是因为如果不可重现的缺陷没有积累到一定的量,很难找出根本原因,因为每个偶尔出现的缺陷只能提供很少的一部分信息,信息量没有累计到一定的程度,就找不出根本的原因。
(3)集成fix的代码
这一步和常规的缺陷处理流程是一样的,但是管理者需要注意,很多时候同一段fix代码解决的可能是一批偶尔出现的缺陷,这些fix代码改动通常比较大,或者改变的是底层的数据,或者是内存管理的优化等,反正都是些疑难杂症,所以不适合在重要的软件,比如,Sales candidate,上集成这些fix。
(4)验证fix是否成功,并试图验证这个fix是否有负面影响。Fix是成功的,没有负面影响或者负面影响在可接受范围内,那这个缺陷就可以close 了;如果fix不成功,或者有严重的负面影响,需要考虑是否rollback。
对于能复现的缺陷,验证fix是否成功是件很容易的事情,但是对于偶尔出现的缺陷,验证fix是否成功是件相当难的事情,因为本身缺陷就是偶尔出现的,不能复现了也不能说明fix是成功的。这依然需要长期观察、安排测试人员集中测试、或者让终端用户测试人员多注意。有时候不可复现的缺陷并不能完全fix,可能一个fix只能降低复现的概率,将到能接受的范围也是可以的,比如对于一个通话过程中经常掉话的缺陷,把复现率从百分之一将到万分之一,也是可以接受的。
通常偶尔出现的缺陷不是一个一个处理的,一般是一批一批处理的,偶然的现象联系起来,让开发人员分析,通常能发现根本原因是什么,这样对于试图复现偶尔出现的缺陷、对于开发人员分析这些缺陷、对于测试人员验证这样的缺陷的效率提高,是有很大帮助的。处理这样的问题很重要的一点是,不能因为这个问题出现的概率低,就随意的的忽略这样的问题。
会员 shwonder :
说这个话题之前,先假设有对缺陷评审的相对完善的机制,缺陷能够被准确的评估。再来说缺陷对处理问题。决定一个缺陷被如何处理,我想主要有两个方面的考虑,一是这个缺陷带来的系统风险的大小,另一个是对这个缺陷的修复成本的高低。在同一坐标轴上,这二者构成了四个象限区,如下图:
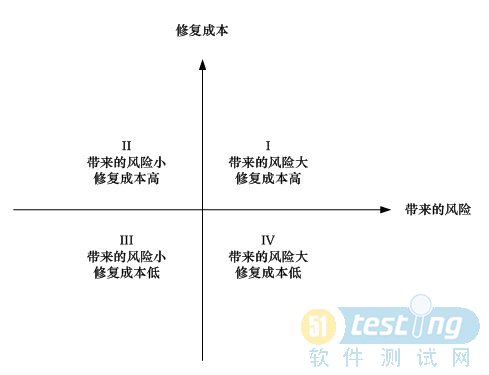
在第四象限,带来的风险越大并且修复成本越低的缺陷最能够引起重视,通常会被最及时处理;相反,在第二象限,带来的风险越小但修复成本越高的缺陷,一般很难被快速处理,我们的情况是这类问题放在最低优先级处理。第三象限的缺陷则较第二象限优先处理。最棘手的是第一象限的问题,对于这类问题我们会通过投入人力或时间来解决。
最后来说偶尔出现缺陷的问题。一般来说,缺陷若出现过一次,则总够通过某些步骤或构造特定测试环境使其再重现出来。因此测试人员要尽可能的保证所提交的缺陷能够被重现出来。为了避免缺陷“偶尔”出现,测试人员在测试过程需要保持清晰的思路,测试执行的过程要可重现(按照测试用例的描述执行),测试环境也要能够重新构造(包括服务器端环境和客户端环境,对系统运行的环境要有记录)。对于不是根据测试用例发现的缺陷,提交缺陷时还需一并描述该缺陷出现的环境及上下文条件。在这样的情况下,若仍发现了偶尔出现的缺陷,则可以按照前面提到的方法对缺陷进行分析,评估该缺陷所属象限,并据此判断是否需要对该缺陷进行持续跟踪。
另外,遇到这类缺陷的时候也有必要与开发人员做充分的沟通,与开发人员一起分析缺陷可能产生的条件或原因。
当然了,一定不能有侥幸心理,无论是对于开发人员还是测试人员,都是这样。偶尔出现的缺陷也一定要记录下来。我曾经遇到过测试人员偷懒或者是幸存侥幸心理不提交偶尔出现的缺陷的情况(因为重现困难,怕在开发人员面前出丑或是怕麻烦)。

