

本文主要分享 Datacake 在大数据治理中,AI 算法的应用经验。本次分享分为五大部分:第一部分阐明大数据与 AI 的关系,大数据不仅可以服务于 AI,也可以使用 AI 来优化自身服务,两者是互相支撑、依赖的关系;第二部分介绍利用 AI 模型综合评估大数据任务健康度的应用实践,为后续开展数据治理提供量化依据;第三部分介绍利用 AI 模型智能推荐 Spark 任务运行参数配置的应用实践,实现了提高云资源利用率的目标;第四部分介绍在 SQL 查询场景中,由模型智能推荐任务执行引擎的实践;第五部分展望了在大数据整个生命周期中,AI 的应用场景。
一、大数据与 AI
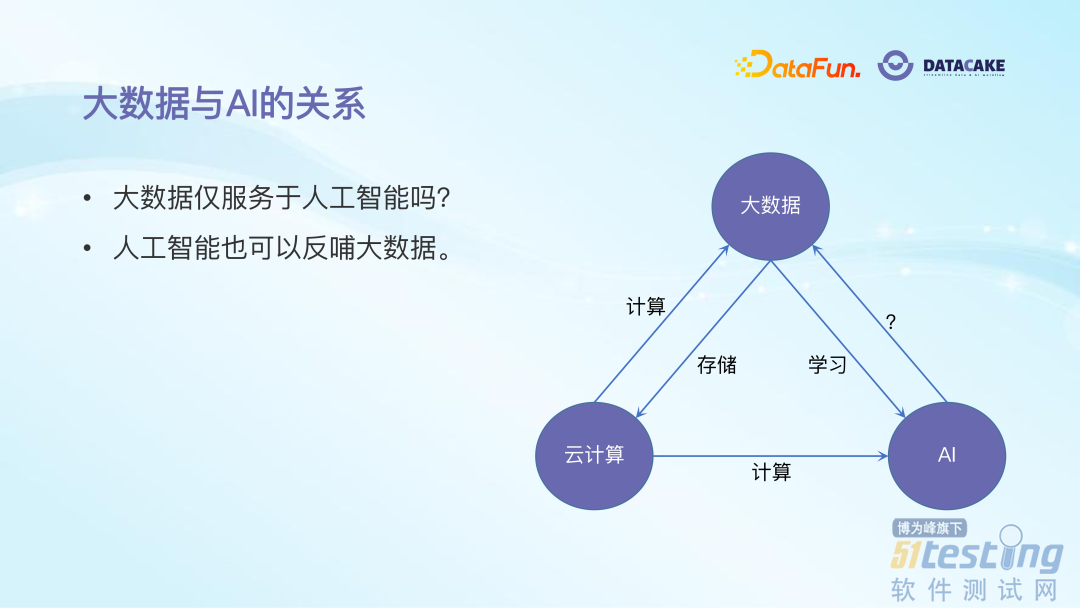
普遍观念认为,云计算收集存储海量数据,从而形成大数据;再经过对大数据的挖掘学习,进一步形成 AI 模型。这种观念默认了大数据服务于 AI,但忽视了其实 AI 算法也可以反哺于大数据,它们之间是一个双向、互相支撑、依赖的关系。

大数据的全生命周期可以分成六个阶段,每个阶段都面临一些问题,恰当地使用 AI 算法有助于这些问题的解决。
数据采集:这个阶段会比较关注数据采集的质量、频率、以及安全性,例如采集到的数据是否完整,采集数据的速度是否过快或者过慢,采集的数据是否经过脱敏或者加密等。这时候 AI 可以发挥一些作用,比如基于同类应用来评估日志采集的合理性、使用异常检测算法来发现数据量暴增或骤减等情况。
数据传输:这个阶段比较关注数据的可用性、完整性和安全性,可以使用 AI 算法来做一些故障的诊断和入侵检测。
数据存储:这个阶段比较关注数据的存储结构是否合理、资源占用是否足够低、是否足够安全等,同样可以用 AI 算法来做一些评估以及优化。
数据处理:这个阶段是影响及优化收益最明显的一个阶段,其核心问题就是提高数据的处理效率且降低资源的消耗,AI 可以从多个着手点进行优化。
数据交换:企业之间的合作越来越多,这就会涉及到数据的安全性问题。算法在这方面也可以得到应用,比如时下热门的联邦学习就可以帮助更好更安全地进行数据的共享。
数据销毁:数据不可能只存不删,这就需要考虑什么时候可以去删数据、是否有风险。在业务规则的基础上,AI 算法可以辅助判断删除数据的时机及关联影响。
整体来看,数据生命周期管理有三大目标:高效、低成本,以及安全。以往的做法是依靠专家经验来制定一些规则策略,其弊端非常明显,成本高、效率低。恰当地采用 AI 算法可以避免这些弊端,反哺于大数据基础服务的建设。
二、大数据任务健康度评估
在茄子科技,已经落地的几个应用场景,首先是大数据任务健康度的评估。

在大数据平台上,每天运行着成千上万的任务。但是很多任务仅停留在能正确产数阶段,对于任务的运行耗时、资源消耗等并未给予关注,导致很多任务存在效率低下、资源浪费的情况。
即使有数据开发者开始关注任务健康度,也很难准确的评估任务究竟健康与否。因为任务相关的指标非常多,失败率、耗时、资源消耗等,况且不同任务的复杂度及处理数据的体量存在天然差别,因此简单选择某项指标的绝对值作为评估标准显然是不合理的。
没有量化的任务健康度,就很难确定哪些任务不健康、需要治理,更不知道问题在哪里、从哪着手治理,即使治理完也不知道效果如何,甚至出现某项指标提升但别的指标恶化的情况。
需求:面对上述难题,我们急需一种量化指标来准确反映任务的综合健康状况。人工制定规则的方式效率低且不全面,因此考虑借助机器学习模型的力量。目标是模型能给出任务的量化评分及其在全局分布中的位置,并且给出任务的主要问题及解决方案。
对此需求,我们的功能模块方案是,在管理界面显示 owner 名下所有任务的关键信息,如评分、任务成本、CPU 利用率、内存利用率等。这样任务的健康度一目了然,方便后续由任务 owner 去做任务的治理。

其次,评分功能的模型方案,我们是把它作为一个分类问题来处理。直观来看,任务评分显然是一个回归问题,给出的应该是 0 到 100 之间的任意实数。但这样的话就要求有足够多的带评分的样本,人工标注成本高且不可靠。
因此我们考虑将问题转化为分类问题,分类模型给出的类别概率可以进一步映射为实数分值。我们将任务分为好任务 1 和坏任务 0 两类,由大数据工程师标注。所谓好任务,通常是指同等任务量与复杂度的情况下,耗时短、资源消耗少的任务。

模型训练过程为:
首先是样本准备,我们的样本来自于历史运行的任务数据,样本特征包括运行时间、使用的资源、是否执行失败等等,样本标签是由大数据工程师根据规则或经验标注成好、坏两类。然后就可以训练模型了,我们先后尝试过 LR、GBDT、XGboost 等模型,理论及实践均证明 XGboost 具有更好的分类效果。模型最终会输出任务为“好任务”的概率,该概率越大,最终映射出的任务评分就越高。

经过训练之后,从最初将近 50 个原始特征里面筛选出 19 个特征,这 19 个特征基本上能够决定一个任务是否是一个好的任务。比如失败次数多的任务、资源利用率低的任务,大部分得分不会太高,与人工的主观感受基本一致。
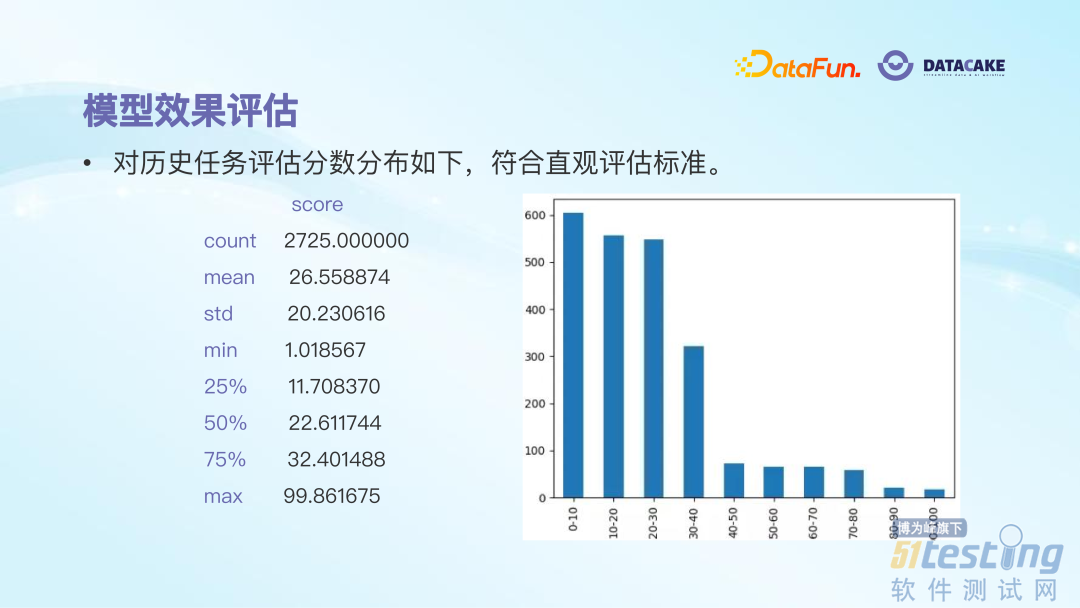
使用模型对任务打分后可以看到,在 0 到 30 分以下属于不太健康的、急需要治理的任务;30 到 60 之间的是健康度尚可的任务;60 分以上的是健康度比较好的,需要保持现状的任务。这样有了量化指标,就可以引导任务 owner 去积极地做一些任务的治理,从而实现降本增效的目标。
模型应用之后给我们带来了如下收益:
① 首先,任务 owner 对其名下任务的健康度可以做到心中有数,通过分数、排名就能够知道任务是否需要治理;
② 量化的指标为后续开展任务治理提供了依据;
③ 任务治理完成之后取得了多大的收益,有多少提升,同样可以通过分数得到量化的展示。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












