

目标页面
study.163.com/course/intr…
一开始用常规方法请求下来,发现源码中根本找不到任何课时信息,说明该网页用 JavaScript 来动态加载内容。
使用开发者工具分析一下,发现浏览器请求了如下的地址获取课时详情信息:
study.163.com/dwr/call/pl…
在预览界面可以看到各课时信息的 Unicode 编码。
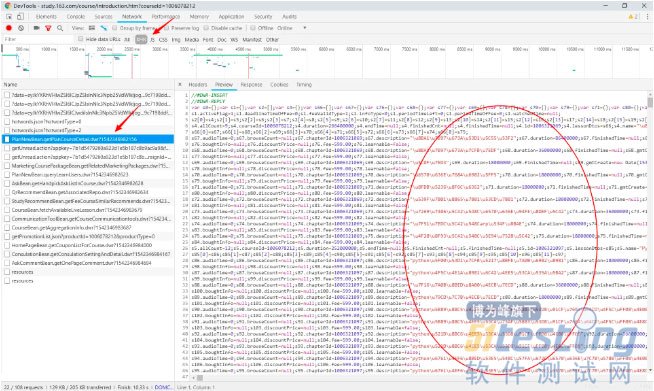
尝试直接请求上述地址,显然会报错,不想去研究请求头具体应该传哪些参数了,直接上 Selenium,反正就爬一个页面,对性能没什么要求。
代码
说明
·study163seleniumff.py 是主运行文件
· helper.py 是辅助模块,与主运行文件同目录
· geckodriver.exe 需要放在 ../drivers/ 这个相对路径下
study163seleniumff.py
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from lxml import etree
import csv
from helper import Chapter, Lesson
# 请求数据
url = 'https://study.163.com/course/introduction.htm?courseId=1006078212#/courseDetail?tab=1'
options = Options()
options.add_argument('-headless') # 无头参数
driver = Firefox(
executable_path='../drivers/geckodriver',
firefox_options=options)
driver.get(url)
text = driver.page_source
driver.quit()
# 解析数据
html = etree.HTML(text)
chapters = html.xpath('//div[@class="chapter"]')
TABLEHEAD = ['章节号', '章节名', '课时号', '课时名', '课时长']
rows = []
for each in chapters:
chapter = Chapter(each)
lessons = chapter.get_lessons()
for each in lessons:
lesson = Lesson(each)
chapter_info = chapter.chapter_info
lesson_info = lesson.lesson_info
values = (*chapter_info, *lesson_info)
row = dict(zip(TABLEHEAD, values))
rows.append(row)
# 存储数据
with open('courseinfo.csv', 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.DictWriter(f, TABLEHEAD)
writer.writeheader()
writer.writerows(rows)
helper.py
class Chapter:
def __init__(self, chapter):
self.chapter = chapter
self._chapter_info = None
def parse_all(self):
# 章节号
chapter_num = self.chapter.xpath(
'.//span[contains(@class, "chaptertitle")]/text()')[0]
# 去掉章节号最后的冒号
chapter_num = chapter_num[:-1]
# 章节名
chapter_name = self.chapter.xpath(
'.//span[contains(@class, "chaptername")]/text()')[0]
return chapter_num, chapter_name
@property
def chapter_info(self):
self._chapter_info = self.parse_all()
return self._chapter_info
def get_lessons(self):
return self.chapter.xpath(
'.//div[@data-lesson]')
class Lesson:
def __init__(self, lesson):
self.lesson = lesson
self._lesson_info = None
@property
def lesson_info(self):
# 课时号
lesson_num = self.lesson.xpath(
'.//span[contains(@class, "ks")]/text()')[0]
# 课时名
lesson_name = self.lesson.xpath(
'.//span[@title]/@title')[0]
# 课时长
lesson_len = self.lesson.xpath(
'.//span[contains(@class, "kstime")]/text()')[0]
self._lesson_info = lesson_num, lesson_name, lesson_len
return self._lesson_info
最终结果
最终结果保存为 courseinfo.csv,与主运行文件同路径。

本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












