

在路上发现好多人都喜欢用耳机听小说,同事居然可以一整天的带着一只耳机听小说。小编表示非常的震惊。今天就用 Python 下载听小说 tingchina.com的音频。
书名和章节列表
随机点开一本书,这个页面可以使用 BeautifulSoup 获取书名和所有单个章节音频的列表。复制浏览器的地址,如:https://www.tingchina.com/yousheng/disp_31086.htm。
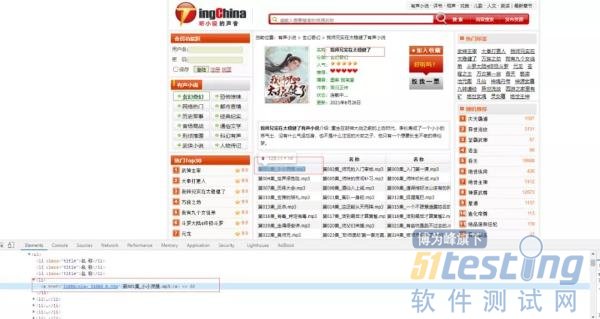
from bs4 import BeautifulSoup
import requests
import re
import random
import os
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36'
}
def get_detail_urls(url):
url_list = []
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'lxml')
name = soup.select('.red12')[0].strong.text
if not os.path.exists(name):
os.makedirs(name)
div_list = soup.select('div.list a')
for item in div_list:
url_list.append({'name': item.string, 'url': 'https://www.tingchina.com/yousheng/{}'.format(item['href'])})
return name, url_list
音频地址
打开单个章节的链接,在 Elements 面板用章节名称作为搜索词,在底部发现了一个 script,这一部分就是声源的地址。

在 Network 面板可以看到,声源的 url 域名和章节列表的域名是不一样的。在获取下载链接的时候需要注意这一点。
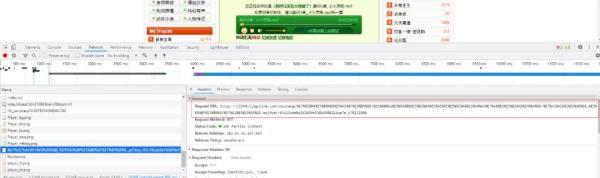
def get_mp3_path(url):
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
soup = BeautifulSoup(response.text, 'lxml')
script_text = soup.select('script')[-1].string
fileUrl_search = re.search('fileUrl= "(.*?)";', script_text, re.S)
if fileUrl_search:
return 'https://t3344.tingchina.com' + fileUrl_search.group(1)
下载
惊喜总是突如其来,把这个 https://t3344.tingchina.com/xxxx.mp3 放入浏览器中运行居然是 404。
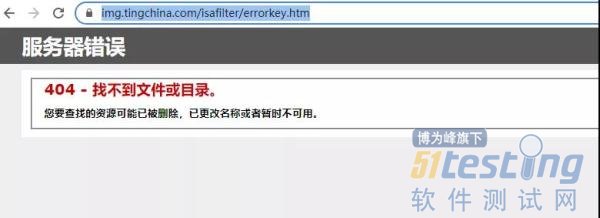
肯定是少了关键性的参数,回到上面 Network 仔细观察 mp3 的 url,发现在 url 后面带了一个 key 的关键字。如下图,这个 key 是来自于 https://img.tingchina.com/play/h5_jsonp.asp?0.5078556568562795 的返回值,可以使用正则表达式将 key 取出来。

def get_key(url):
url = 'https://img.tingchina.com/play/h5_jsonp.asp?{}'.format(str(random.random()))
headers['referer'] = url
response = requests.get(url, headers=headers)
matched = re.search('(key=.*?)";', response.text, re.S)
if matched:
temp = matched.group(1)
return temp[len(temp)-42:]
最后的最后在 __main__ 中将以上的代码串联起来。
if __name__ == "__main__":
url = input("请输入浏览器书页的地址:")
dir,url_list = get_detail_urls()
for item in url_list:
audio_url = get_mp3_path(item['url'])
key = get_key(item['url'])
audio_url = audio_url + '?key=' + key
headers['referer'] = item['url']
r = requests.get(audio_url, headers=headers,stream=True)
with open(os.path.join(dir, item['name']),'ab') as f:
f.write(r.content)
f.flush()
总结
这个 Python 爬虫比较简单,小编的每个月 30 元的流量都不够用,又了这个小程序在地铁上就可以不用流量听小说了。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












