

很快,三个月又过去了,口罩已经成了生活的必需品,“后疫情时代”已经把我们变得已经对于每天疫情情况麻木了,我们也许真的不得不习惯与“新冠肺炎”长期共处。时间总是像奔腾不息的江水一样,汹涌地奔腾向前,真的不管外界的环境是怎样,我们真的需要时常问自己:被这些奔腾的江水裹挟着的我们,在这些汹涌的江水里能沉淀些什么?女巫这三个月把如何使用docker swarm的stack进行分布式发布,以及如何利用redis cache db来提高代码的性能搞定,也是浓墨重彩的一笔,好吧,闲话不多说,我们进入此次的学习吧~
此次学习的方向是有关模组的学习:即企业数据可视化解决方案Plotly。上一期我们已经学习了统计学的"描述统计学"又叫"叙述统计",以及数据清理,数据整理。我们已经具备了大数据分析的最基础的知识,这一期我们将继续学习用形象化的方法即画图的方式来分析大数据。
Plotly介绍
也可以选择使用pyechats, matplotlib都可以画图;选择一个module进行study即可~
目标
Bring data science out of the lab and into the business
Open Source
plotly本身是基于javascript开发的,但是提供了大量与其他主流数据分析语言的API,可以参考https://plot.ly/api/
来自官网的解释:Plotly's team maintains the fastest growing open-source visualization libraries for R, Python, and JavaScript.如下图
注意dash open source is the front-end to your analytical Python backend,它只有大概40行的代码,提供了一个用于键入UI控件的界面,包含滑块,下拉列表和带代码的图形等等;因为我们已经有angular所以它对我们意义不是很大。
但是很受大家欢迎,从star就可以看出来。
应用广泛
Our software is embedded in mission critical applications across the Fortune 500.如下图

Plotly_Python
Poltly Fundamentals
如下图
我们这次介绍的主要是plotly.graph_objects 以及Plotly Express
https://plot.ly/python/creating-and-updating-figures/#constructor
Create Figures
Figures as graph objects:
使用renderers framework 显示figures,即导入的graph_objects这个module,调用其中的函数Figure,并返回实例,并将实例show出来
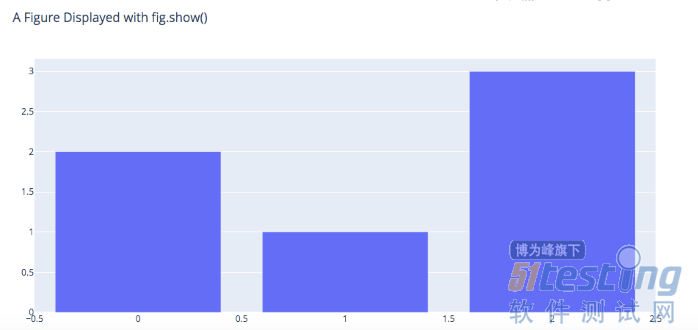
import plotly.graph_objects as go fig = go.Figure( data=[go.Bar(y=[2, 1, 3])], layout_title_text="A Figure Displayed with fig.show()" ) fig.show() |
fig #这种方式与fig.show()作用一样,都是将figure显示出来
产生的结果如下图
调整title为居中的参数
import plotly.graph_objects as go fig = go.Figure( data = [go.Bar(x =[1,2,3],y = [1,2,3])], layout = go.Layout( title = go.layout.Title(text="我是柱状图",x = 0.5) # x=0.5指的是title需要居中显示 ) ) fig.show() |
JSON data structure的方式描述figure的属性
fig ={ "data":[ { "type" : "bar", "x":[1,2,3], "y":[1,2,3] } ], "layout":{"title":{"text":"我是柱状图"}} } # To display the figure defined by this dict, use the low-level plotly.io.show function import plotly.io as pio pio.show(fig) |
当然也可以用 graph object的方式实现JSON data structure
import plotly.graph_objects as go fig = go.Figure({ "data": [{"type": "bar", "x": [1, 2, 3], "y": [1, 3, 2]}], "layout": {"title": {"text": "A Bar Chart"}} }) fig.show() |
Update Layout
update_layout是一种更新图形布局(可以自动以group chart),也可以更新图形标题的文本和字体大小
更新图形布局
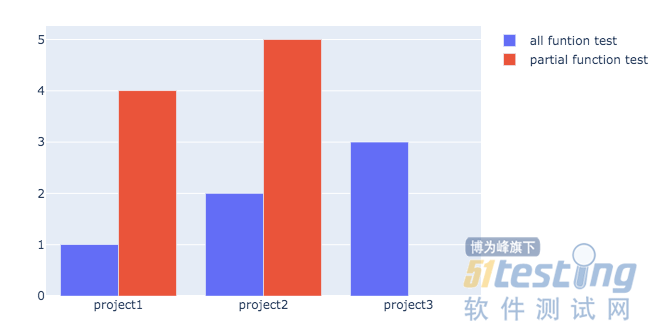
import plotly.graph_objects as go fig = go.Figure(data =[ go.Bar(name ='all funtion test',x = ['project1','project2','project3'],y = [1,2,3]), go.Bar(name = 'partial function test',x =['project1','project2'],y = [4,5,6])]) fig.update_layout(barmode='group') fig.show() |
运行结果如下图
各个图形的细节的属性
例如图形的悬浮文字,颜色等可以根据图形的样式查看Basic Chart,例如你如果使用的是bar chart就点击bar chart其中就可以找到你想要的细节属性设置
如下图6

Plotly Express
它是一个简洁的包装器,它之前是一个独立的软件包,安装它需要pip plotly-experss,现在都打包到plotly这个整体包之中,它已经融入plotly其中;相对于plotly.graphobjects而言它是一个比较高级的包装器,plotly.graphobjects主要是用来快速数据探索和图形生成。
它其中还包含一些科学数据,供你画图使用
我们查看有关花的一些集成到plotly_express的科学数据包
import plotly.express as px # 这个express中,包含了很多让你实验的数据 iris = px.data.iris() print(px.data.iris.__doc__) px.data.iris().head() |
运行结果如下
使用iris.doc查看这个数据的说明文档,我们也要养成写''' ''' 包裹的某个class function设置package的说明文档的习惯。同时将这组数据的head也打印出来,大概了解这组数据是pandas的dataframe,它由150行,6列,注意会自动生成index:即0-4,因为对于pandas的Dataframe,如果没有指定现有的列为index,它会自动生成一列index。
Each row represents a flower. https://en.wikipedia.org/wiki/Iris_flower_data_set Returns: A `pandas.DataFrame` with 150 rows and the following columns: `['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species', 'species_id']`. sepal_lengthsepal_widthpetal_lengthpetal_widthspecies species_id 05.1 3.5 1.4 0.2 setosa1 14.9 3.0 1.4 0.2 setosa1 24.7 3.2 1.3 0.2 setosa1 34.6 3.1 1.5 0.2 setosa1 45.0 3.6 1.4 0.2 setosa1 |
import plotly.express as px # 这个express中,包含了很多让你实验的数据 iris = px.data.iris() fig = px.scatter(iris,x='petal_length',y='petal_width') fig.show() |
运行结果如下图7
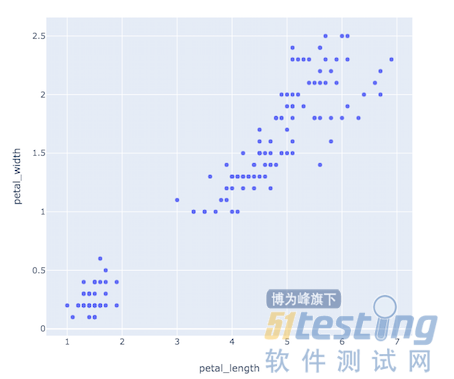
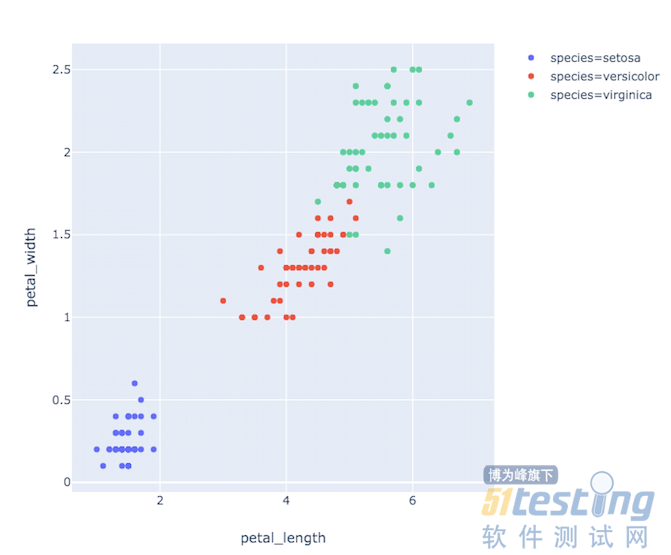
如果使用三列,即将species加上去,按照颜色进行分类,可以这样呈现
import plotly.express as px # 这个express中,包含了很多让你实验的数据 iris = px.data.iris() fig = px.scatter(iris,x='petal_length',y='petal_width',color="species") fig.show() |
运行结果如下图8
各个图形的细节属性
https://plot.ly/python/plotly-express/#plotly-express
Mixed Subplots in Python
作用
在一张图中混合显示不同形式的图
https://plot.ly/python/mixed-subplots/#mixed-subplot
范例
使用make_subplots开确定图形显示几行几列,如下是1行2列
使用add_trace来将各个图形的参数定义清楚
#创建子图 #看源代码的方法:在jupyter中:shift+tab from plotly.subplots import make_subplots fig = make_subplots(rows=1,cols=2) fig.add_trace(go.Scatter(y=[5,2,1],mode = 'lines'),row=1,col=1) fig.add_trace(go.Bar(y=[1,2,3]),row =1,col =2) fig.show() |
运行结果如下图9
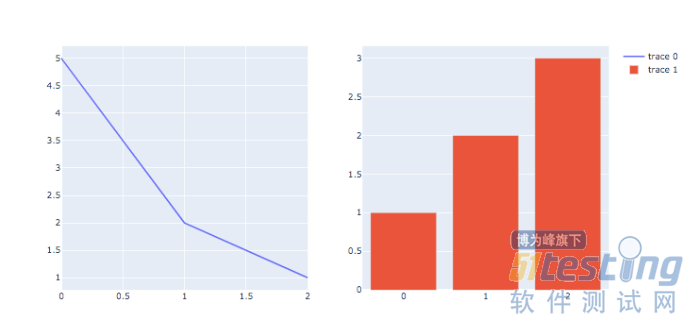
#饼图 import plotly.graph_objects as go import plotly.express as px fig = go.Figure(data=[ go.Pie(labels=['a','b','c'],values=[20,30,50]) ]) fig.show() ‘’‘ |
运行结果如下图

#环图 import plotly.graph_objects as go import plotly.express as px fig = go.Figure(data=[ go.Pie(labels=['a','b','c'],values=[20,30,50],hole = 0.6) ]) fig.show() |
运行结果如下图

数据分布直方图
即画出描述数据分布的直方图,从直方图就可以看出数据分布,虽然不是很完美但是基本上就是正态分布;大家一定要记住一个概念,看数据的分布以及进行数据的分析,不能只看某一个分析的结果,一定要结合数据的各种chart一起确认,一定要从不同的角度去论证,以保证你的结果的正确性。
import numpy as np import pandas as pd from scipy import stats import plotly.graph_objs as go excel_data = pd.read_csv('11adtoolsingle.csv') excel_data_txpower = excel_data['Value'] trace=go.Histogram( x=excel_data_txpower, histnorm = 'probability' ) fig = go.Figure(data = [trace]) fig.show() |
运行结果如下:

这一期我们学习了plotly这个第三方模组,重点学习了plotly.graph_objects 以及Plotly Express中的柱形图,分布图,圆饼图,环形图等的画法;其实希望大家能领悟的是如何学习利用open source的这个第三方模组画出我们需要的图,下一期我们将根据这三期学到的基础知识,对于我们工作中遇到的问题,进行实战分析;这个实战分析结束后,将继续进入大数据分析的“深水区”即利用现有的大数据如何“预测未来”,并将其应用到我们的工作中,怎么样?是不是很期待?加油!让我们在这个多事之秋,快速提高自己的coding以及分析问题的能力,为新的局面提前做好准备!加油!
版权声明:本文出自《51测试天地》第五十八期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












