

1.前言
闲鱼质量团队一直致力于交付高质量的app给用户,当前随着AI技术不断发展,TensorFlow大热,也给测试手段带来了更多种可能。
2.模型选型
不需要理解业务就能发现的bug主要有整体页面空白、部分控件显示异常和文本异常这几类。对于整体空白图片,发现它们的共同特征是比较明显:大面积空白或者中心区域报错,所以选择使用TensorFlow搭建的简单CNN模型来识别正常图片和异常图片。对于文本异常这类包含乱码的图片,则是用OCR+LSTM建立了一个简单的汉字识别模型来识别图片中的文本内容后判断是否存在乱码。
训练以上模型的样本则来源于bug历史截图和mock的正向数据样本。
3.模型重训练——提高模型识别准确率
初始模型在训练时样本有限,但随着app不停更新迭代,图片检测样本数量的逐渐增多,会出现某些新页面被错误分类,要解决这类误报问题,亟需加入模型重训练。
显然靠人肉启动模型重训练并替换旧模型成本太高,所以在前端实现了个勾选图片去重训练的入口,通过Jenkins定时任务,读取所有重训练图片并执行重训练脚本,并把旧模型替换成新生成的即可。经过几轮自动迭代后模型识别准确率有大幅提升。
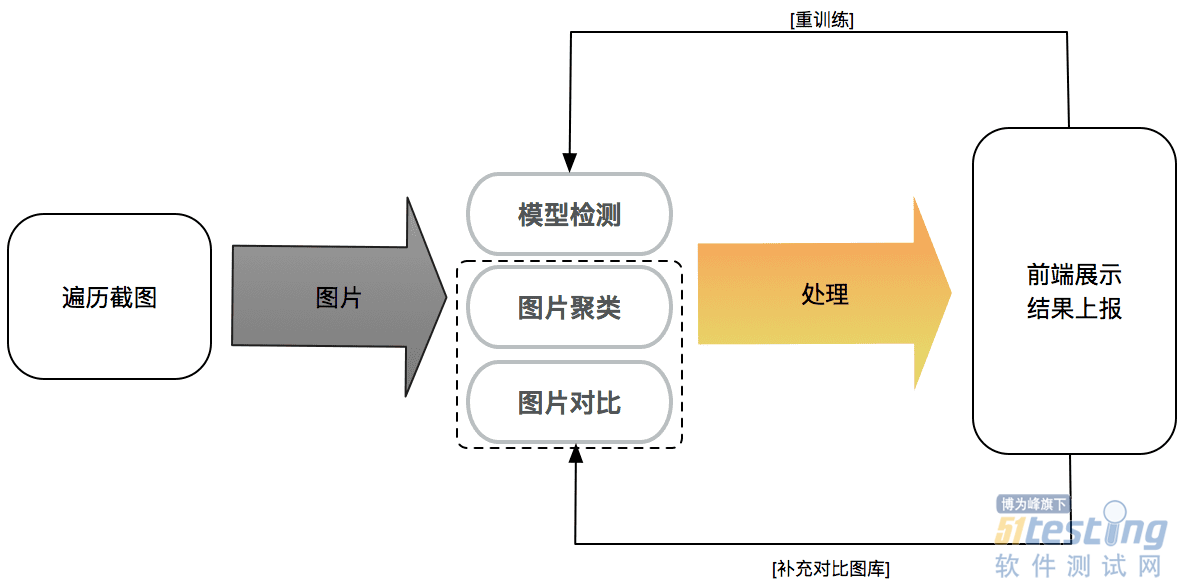
4.图片处理——提升结果的人工甄别效率
4.1特殊截图
有些截图可能是存在大面积空白,但从业务角度上来说这类图片是正确的,比如搜索中间页。此类若不处理,每次都会被识别为异常图片上报,浪费大家check的时间,若放入模型进行重训练又有导致模型不收敛的风险。为了解决这类图片,维护了一个图库,对模型识别为异常的图片,会与图库中的图片进行对比,如果与图库中任意一张相似度超过设定阈值,即认为该图片可被忽略不用上报。

4.2 图片去重
目前遍历截图任务为了保证页面上所有元素都取到,单次遍历任务会至少访问同一个页面两次;同时遍历时,为了方便页面上下文分析,会对点击元素用红框标记。这带来了一个问题:待识别图片集中,同一个页面会有多张重复截图、且同一页面上可能会在不同的地方有红框标记。人工检验大量重复图片识别结果难免视觉疲劳,所以展示去重后的结果可以大大提升人工甄别效率,减少成本。
4.2.1解决办法
图片数量大,且不确定这次遍历截图了多少不同页面时,可以使用层次聚类算法解决这个问题。本文采用的是自底向上的聚类方法,即先将每一张截图分别看成一个簇,然后找出距离最小的两个簇进行合并,不断重复到预期簇或者满足其他终止条件。
4.2.2实现[2]
1)计算图片之间的距离
先将图片转换成w*h*3维向量,把向量间的欧式距离作为图片之间的距离,图片越相似,距离越小。
def get_pic_array(url,w,h): file = cStringIO.StringIO(urllib2.urlopen(url).read()) img = Image.open(file) # PIL打开图片 img=img.resize((w, h)) try: r, g, b, k = img.split() # rgb通道分离,兼容4通道情况 except ValueError: r, g, b = img.split() # 获得长度为(w*h)的一维数组 r_arr = np.array(r).reshape(w * h) g_arr = np.array(g).reshape(w * h) b_arr = np.array(b).reshape(w * h) #将RGB三个一维数组(w*h)拼接成一个一维数组(w*h*3) image_arr = np.concatenate((r_arr, g_arr, b_arr)) return image_arr |
一次app遍历得到的n张图片要完成聚类,先单张图片按照上述处理后,再整体拼接成 n*(w*h*3)的矩阵,做为样本集。
2)计算簇之间距离的方法
single:两个簇中距离最近的两个样本的距离作为这簇间的距离
complete:两个簇中距离最远的两个样本的距离作为这簇间的距离
average:两个簇间样本两两距离的平均值决定,解决个别异常样本对结果对影响,但计算量比较大
ward:离差平方和,计算公式较复杂,要想了解具体计算公式和其他计算方法见计算簇之间距离的方法。
通过尝试后发现ward效果比较好,所以最终选用ward作为计算簇之间距离的方法。
Z = linkage(X, 'ward')
执行上述语句后,聚类完成。
3)临界距离选择
该值直接影响聚类的效果,临界距离过小,会导致某些相似图片不能聚集到一类,临界距离过大,又会导致不是同一个页面的图片聚在一起,所以如何选一个合适的距离非常重要。
实验发现,如果图片被页面异常模型识别为异常图片时,往往这类图片之间的相似性越高,为了不错误聚类不同的异常页面,分别对识别为异常和正常的图片进行聚类,并且异常类的临界距离会设置更小一点。
5.总结与展望
目前该工具对整体页面异常的识别效果较好,文本异常的识别准确率也在丰富样本的过程中不断提升。
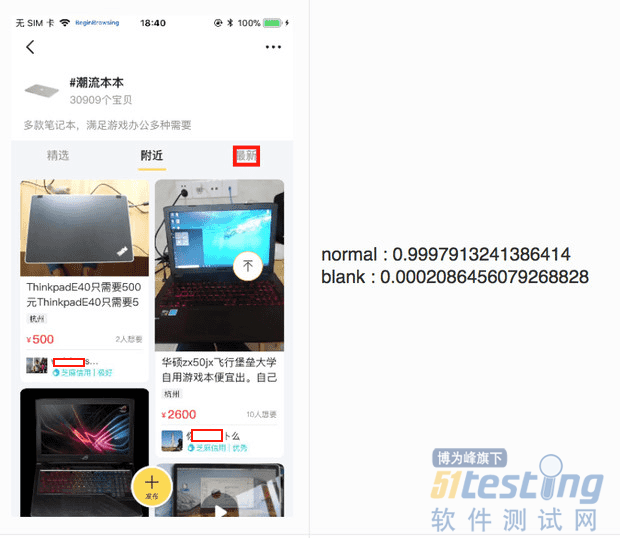
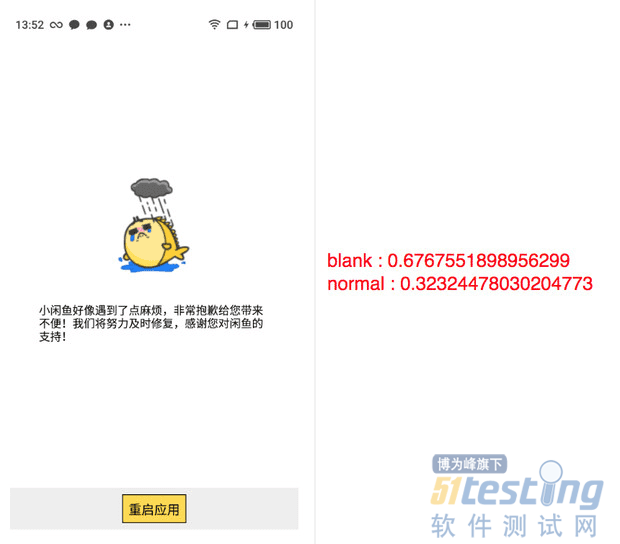
接下来我们会集成LabelImg工具,用TensorFlow搭建SSD模型来识别控件异常的图片,此外元素/文字布局错乱等问题页面识别、页面操作预期结果识别也在不断尝试中。使用图片处理和错误识别技术,作为质量保证的一种方法,我们会持续探索下去。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












