

摘要:
测试数据在项目开发、测试过程中占据着重要的作用,随着我行信息系统建设速度的加快,软件更新速度的不断提升,对数据交付时间和数据格式的要求也越来越高。对于数据库大表来说,无论是脱敏还是导出的速度,往往不能满足实际需要,Kettle作为业内最著名的开源ETL(数据抽取)工具,可直接对数据库表进行操作并以多种格式进行导出,格式规范,效率较高,能很好的满足使用过程中的需要。本文对kettle在实际中具体的使用与实践进行重点介绍。
1 常用ETL工具现状简介
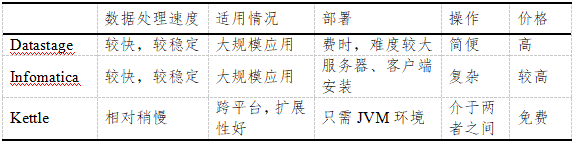
ETL是Extract-Transform-Load的简写,用来描述将数据从源端经过抽取(extract)、转换(transform)、加载(load)到目的端得过程。当数据来自不同的主机,若单独使用SQL语句进行处理的话,效率就会比较低,当处理海量数据的时候还会占用较多的数据库资源,影响数据库的性能,另外还需要整理成统一的格式,也比较麻烦。这些问题就可以用ETL工具进行解决,具有支持异构连接、图形界面操作方便、处理速度快等优点。目前业内口碑较好的ETL工具有Datastage、Infomatica、Kettle。Datastage由IBM公司开发,目前是业内最专业的商用ETL工具,Infomatica也是专业的ETL商业工具软件,Kettle由纯Java编写,是最著名的开源ETL工具产品,下图是三种工具的比较。
2 开源数据抽取工具kettle介绍
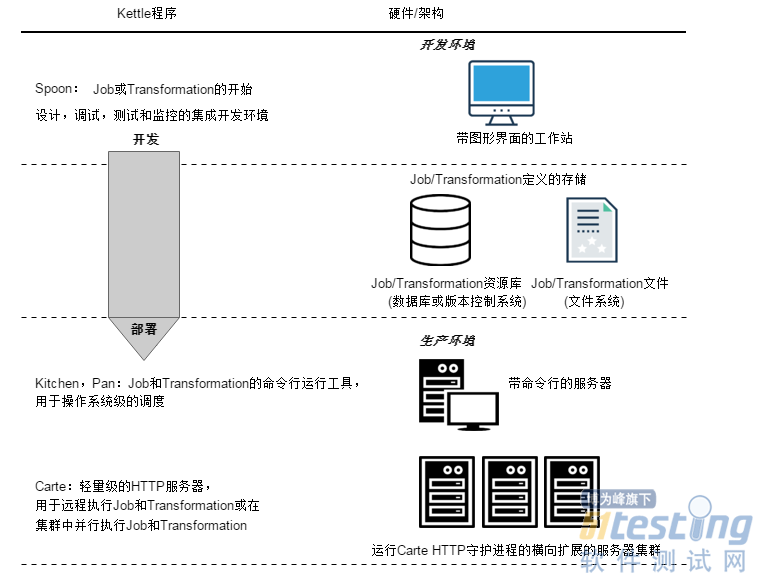
2.1 Kettle架构
Kettle是一个由Java编写组件化的集成系统,是一个开源的ETL工具,可以跨平台运行,包括如下几个主要部分:
(1)Spoon:图形化界面工具(GUI方式),Spoon允许你通过图形界面来设计Job和Transformation,可以保存为文件或者保存在数据库中。也可以直接在Spoon图形化界面中运行Job和Transformation,
(2)Pan:Transformation执行器(命令行方式),Pan用于在终端执行Transformation,没有图形界面。
(3)Kitchen:Job执行器(命令行方式),Kitchen用于在终端执行Job,没有图形界面。
(4)Carte:嵌入式Web服务,用于远程执行Job或Transformation,Kettle通过Carte建立集群。
(5)Encr:Kettle用于字符串加密的命令行工具,如:对在Job或Transformation中定义的数据库连接参数进行加密。
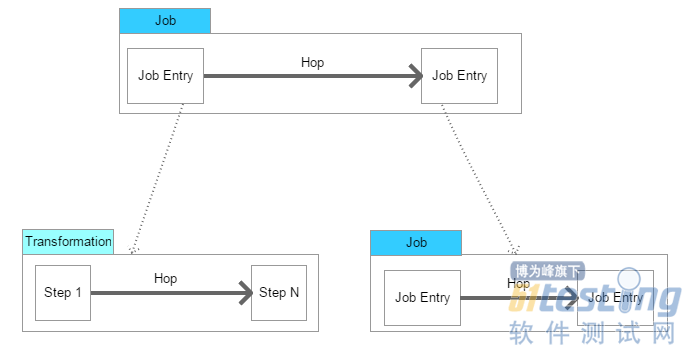
2.2 基本概念
(1)Transformation:定义对数据操作的容器,数据操作就是数据从输入到输出的一个过程,可以理解为比Job粒度更小一级的容器,我们将任务分解成Job,然后需要将Job分解成一个或多个Transformation,每个Transformation只完成一部分工作。
(2)Step:是Transformation内部的最小单元,每一个Step完成一个特定的功能。
(3)Job:负责将Transformation组织在一起进而完成某一工作,通常我们需要把一个大的任务分解成几个逻辑上隔离的Job,当这几个Job都完成了,也就说明这项任务完成了。
(4)Job Entry:Job Entry是Job内部的执行单元,每一个Job Entry用于实现特定的功能,如:验证表是否存在,发送邮件等。可以通过Job来执行另一个Job或者Transformation,也就是说Transformation和Job都可以作为Job Entry。
(5)Hop:用于在Transformation中连接Step,或者在Job中连接Job Entry,是一个数据流的图形化表示。
3 部署环境搭建
本文采用Windows2012作为Kettle部署环境,SUSE12作为数据库环境,采用Oracle作为连接数据库。
3.1 kettle安装
Kettle由Java语言编写,首先要配置?Java?语言的软件开发工具包JDK,ORACLE官网下载JDK安装包,并配置环境变量,本文不再赘述。
从kettle官https://community.hitachivantara.com/docs/DOC-1009855下载kettle工具包,本文采用8.2.0.0-342版本。配置环境变量,找到kettle存放路径,在环境变量里新建系统变量添加kettle的安装路径。完成后将下载好的kettle工具包解压到安装路径中,找到spoon.bat文件,kettle是免安装的,所以直接双击运行即可。
3.2 配置连接数据库
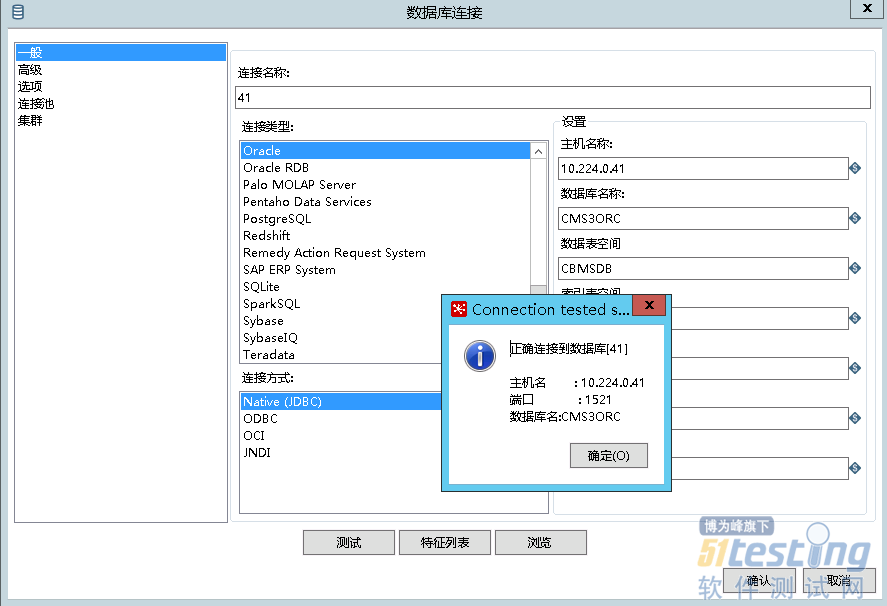
使用jdbc连接oracle数据库,将数据库的监听打开,并复制oracle安装目录下对应的jar包放在Spoon目录下即可(本文为D:\pdi-ce-8.2.0.0-342\data-integration\lib)。重新启动Spoon,点击数据库连接,进行配置,可以看到连接成功了,如图所示。
4 Kettle使用实践与应用
Kettle主要分为作业和转换两个主要的功能,进行了试用如下。
4.1 转换
转换就是针对数据的各种处理,一个转换里可以包含多个步骤。
(1)数据的抽取

左侧newfile选择新建一个转换,核心对象栏,输入选择表输入直接向右拖拽即可,输出选择文本文件输出,如图所示。
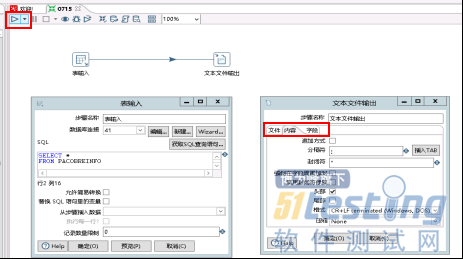
表输入栏编辑数据库连接,前面已经介绍过,获取SQL查询语句也就是需要抽取的表;文本文件输出栏可以对输出文本文件的文件位置、文件名称、字段分隔符、以及字段进行编辑。完成后直接点击左上右三角运行,可以通过下面的执行结果导航栏查看执行日志,可以看到数据抽取速度每秒可达到2万5千行左右,如图所示。可以简单估算使用kettle进行数据表到文件的抽取,一小时能抽取约1一亿条数据左右,这相对从数据库直接抽取来说是比较快的。
当然在输入栏中还可以选择Excel输入、文本文件输入、生成随机数、生成随机的信用卡号、获取系统信息等;同样在输出栏中也可以根据前面所选择的输入选择输出,包括Excel输出、SQL文件输出、表输出、插入/更新等。例如:连接数据库将表输出为其他数据库的另一张表(前提要把新表建好)
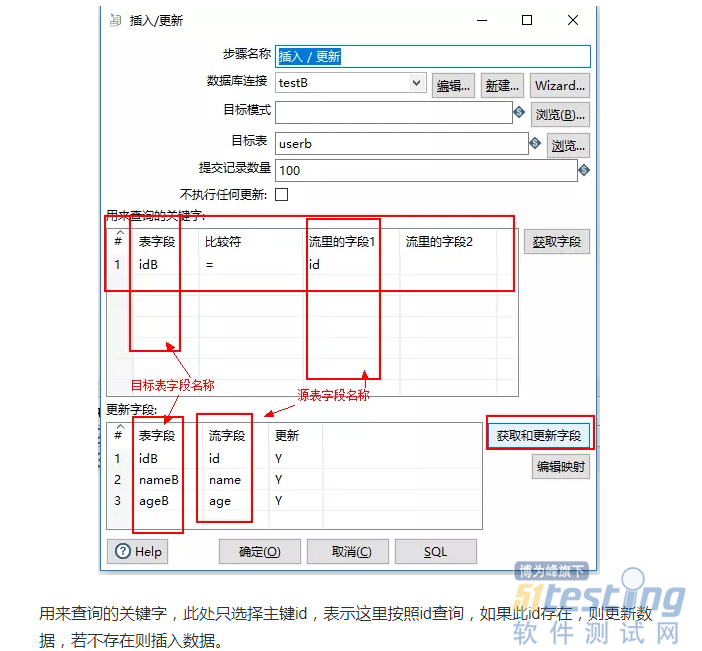
将表内容抽出来插入到表中(按id识别,id存在则更新数据,不存在则插入数据)。

也可以生成信用卡号或随机数以表输出(同样要建好数据表相应的字段)
(2)数据转换
如何进行输入输出前面已经介绍过,也可以对数据进行转换操作后再输出,根据需要选择左侧导航栏转换中的功能,如图流程2和3所示,可以对输入的表进行字符串的替换和将字段值设置为常量的操作。
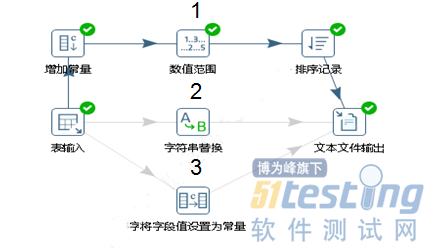
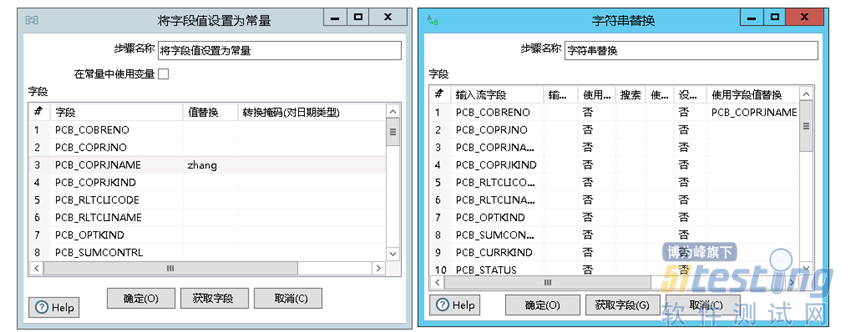
流程2和3中操作步骤基本一样,点击获取字段得到输入表的所有字段信息,值替换栏中输入想要替换的值以及在字符串替换中直接选择使用替换的字段值,完成后选择对应的输出,这里选择文本文件输出,点击节点连接使之生效,之后运行这个转换即可。
除了单一转换外,kettle也支持多步骤的进行操作,如图流程1所示,表输入之后可以先增加一常量列,可以自定义常量列的字段类型与数值,然后可以编辑字段列的数值范围,根据字段的取值进行自定义,接着可以按字段进行排序,最后自定义进行文本文件输出,如图所示。
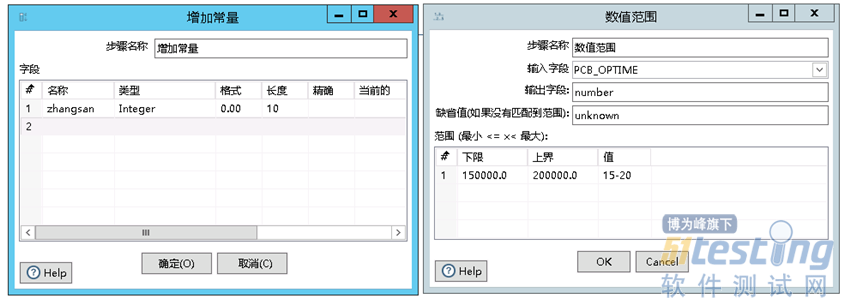
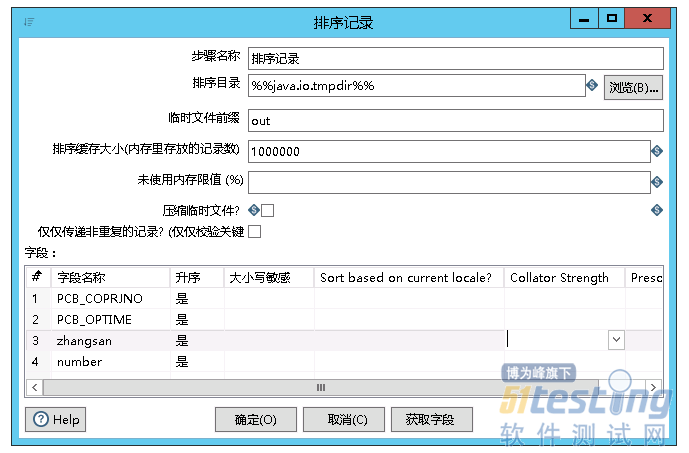
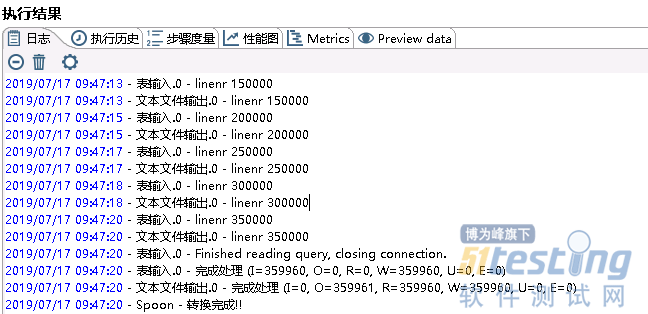
最后运行这个转换,每个功能右上角出现绿标,表示执行成功且没有错误,可以在对应目录下查看执行出的文本文件,如图所示。

(3)流程、统计与应用
前面介绍了单一功能的使用,根据实际情况的需要,kettle也可以对多功能进行组合操作,如图所示。
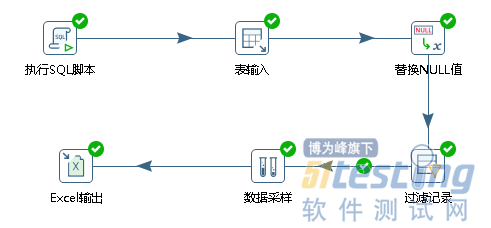
转换由脚本(执行SQL脚本)—输入(表输入)—应用(替换NULL值)—流程(过滤记录)—统计(数据采用)—输出(Excel输出)组成。
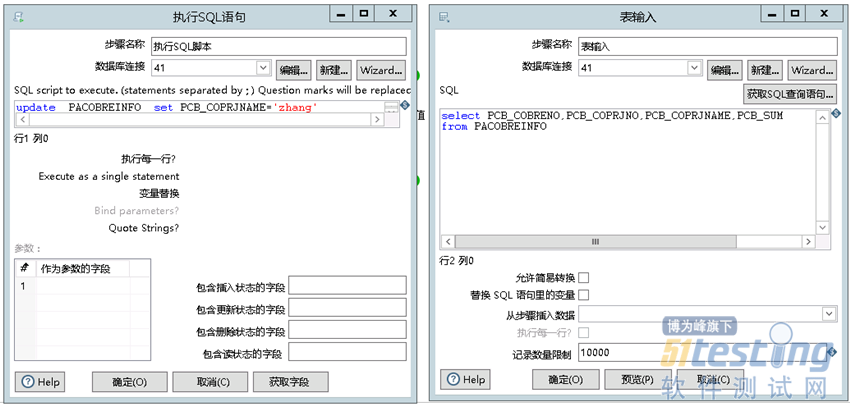
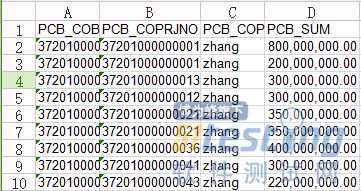
以PACOBREINFO 表为例,首先对表进行更新操作后按需要抽取表中数据,记录数量限制里选择抽取1万条,如果数据中包含NULL值可以替换掉NULL值为固定值。
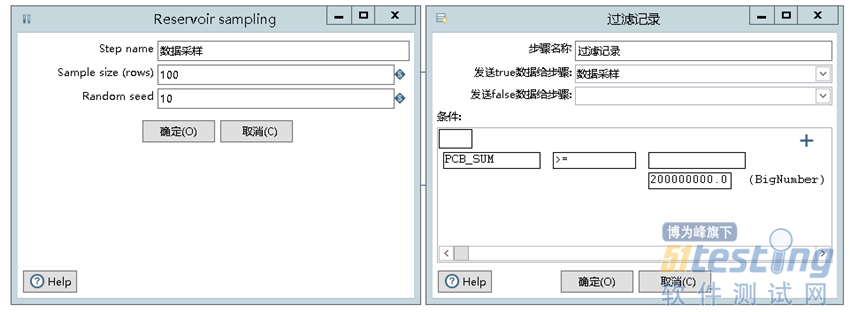
接着可以根据需要过滤记录,这里选择PCB_SUM大于200000000.0的值发送到下一步,接着进行数据的随机采样,从100条数据中随机抽取10条,最后输出到Excel中,运行这个转换,打开Excel检查输出的结果,可以看到是符合转换的后预期结果的,如图所示。
在转换中还有很多其他的功能,既可以单一功能进行使用也可以多功能多步骤进行组合在一起使用,以满足实际使用的需要,这里不再一一列举。
4.2 作业
和转换相比,作业是更加高级的操作。包含多个作业项,一个作业项代表一项工作,转换也是一个作业项(脚本、文件管理、邮件等),如图所示。

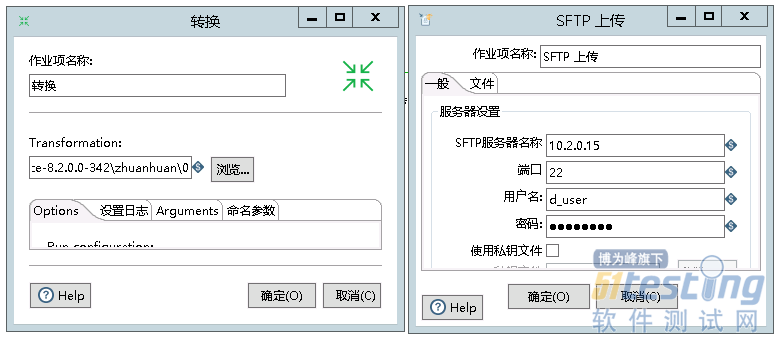
新建转换然后添加作业项,选择Start为开始,以成功为结束并发送邮件。

添加使用过的“流程、统计与应用”的转换,转换后将生成的Excel以SFTP上传,输入对应的ip、用户名、密码和文件目录,最后执行作业,成功后会以邮件告知。
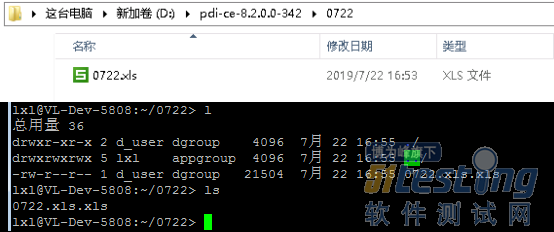
可以看到在每个作业项右上角出现绿色的对勾,表明执行成功没有报错,转换完成后将会D盘0722目录下生成Excel文件并会将文件上传到指定的机器上。
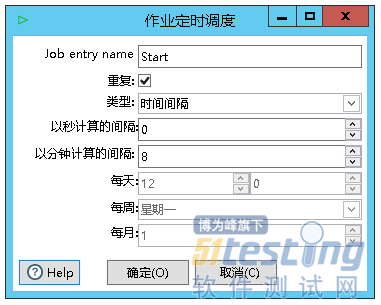
同时也可以对作业进行定时执行操作,点击Start作业项,选择重复按钮,这里选择以8分钟为时间间隔,也就是8分钟重复执行一次作业。
可以通过执行结果栏中的作业度量选项查看详细的执行历史,如图所示:

4.3 实际对比应用
通过以上的实践可以看出Kettle可以配置连接多种数据库并进行操作最后实现数据的导出,在日常的数据脱敏工作中可以将数据库中脱敏后的表数据以文本形式导出,而且格式规范,方便后续项目组使用,以实际Oracle数据库中CMEVALURELACOLL表为例,表中数据量约为4500万行,以下是实际使用中的效率对比情况。
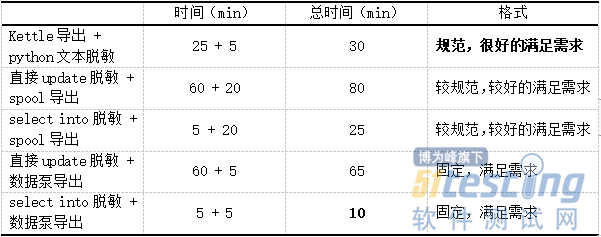
可以看出若在实际项目中,对数据输出格式没有要求,可以采用select into脱敏+数据泵导出这种方式进行脱敏导出交付,效率最高;若使用方必须要使用可识别的文本格式数据,虽然select into脱敏+spool导出时间效率上较Kettle导出+python文本脱敏快一些,但使用Kettle导出后的文本格式较spool更为规范,能很好的满足使用过程中的需求,所以使用Kettle导出+python文本脱敏这种方式最优。
5 总结
本文对当前主流ETL工具进行了分析和比较,并对开源工具Kettle的整体架构、基本概念进行介绍,搭建了连接Oracle数据库的使用环境,对使用功能进行了实践。通过Kettle连接Oracle数据库,可以对数据库表进行DML操作并且可以进行抽取、转换以多种格式输出,同时将多个工作项组成一个作业,可以重复运行,提升了复用效率。同时利用Kettle在实际应用中进行了对比,在实际场景中利用Kettle导出+python文本脱敏的方式,速度较快,格式规范,效率较高,节省时间,能很好的满足使用过程中的需求。为测试数据的导出交付提供了参考,具有一定的借鉴意义。
版权声明:本文出自51Testing会员投稿,51Testing软件测试网及相关内容提供者拥有内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












