

摘要:
随着大数据的应用普及,HBASE作为一种非常适应海量数据存储和查询的数据库也逐步流行起来。本文针对于实际测试中,存在的数据库查询需求进行说明。即使是使用HBASE的大数据应用,测试过程中也需要对数据进行查询来完成结果验证。HBASE的命令行可以解决手工测试的问题,对于自动化测试中的数据验证,需要一种程序化的方法完成数据对比。关系型数据库的理念深入人心,所以如果能像查询MySQL一样查询HBASE,能带来极大的便利。所以本文介绍一种使用Java API构造查询HBASE的实现思路,旨在通过程序设计统一HBASE和MySQL的处理。
本文首先简单介绍了HBASE和关系型数据库的差异,之后说明了HBASE查询命令的使用,详细给出了查询过滤器的API,最后重点介绍了通过Java API实现的HBASE如同MySQL一样查询的程序实现,并对其中重要的查询给出流程说明。
1、HBASE简介
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。简单理解HBASE就是一种数据库,和MySQL、Oracle等一样是用来存储数据的。但与这些关系型数据库有本质区别的是,HBASE是一种NOSQL数据库,适合于非结构化数据存储的数据库。典型的NOSQL数据库包括MangoDB、Redis、Memcache等,在其中的HBASE是基于列数据库。
对于与关系型数据库,基于列的存储理解不是特别直接。传统的关系型数据库基于行存储,如下表table1,具有3行数据r1、r2和r3,表结构为6列,分别为cf1_c1、cf1_c2、cf2_c1、cf2_c2、cf3_c1、cf3_c2,如下图。

将上述数据转换到HBASE中存储,查询数据如下。

通过下方的“3 row(s)”我们可以看出,虽然列出了18条数据,但事实也是属于3行的,所以就对应了关系型数据库中的3行记录。以r1为例,对应关系如下图所示。

这是一种方便理解的对应方式。HBASE的优势在于不是每列都需要有值,这样就非常适合稀疏数据的存储。同时,列名可以根据需要随时增加,方便存储非结构化数据。
HBASE目前是Apache的Hadoop项目的子项目,是一个分布式的、面向列的开源数据库。该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。
2、HBASE查询命令和Java API详解
2.1 HBASE查询命令
HBASE的查询命令提供两种方式:
按指定rowkey获取唯一一条记录:get方法。
按指定条件获取一批记录:scan方法。
二者都可以对HBASE进行过滤查询,以get为例,最常见的用法是如下命令:get ‘table1’,’r1’,结果如下。

如果指定了列族和列名,可以获取指定的单元格信息,命令为:get ‘table1’,’r1’,’cf1:c1’,结果如下。

但get只能获取一行的数据,如果想通过get直接获取一个表中的全部数据是做不到的,这种情况就要用到scan。
2.2 Scan基本使用
通过HBASE shell中的帮助,我们可以知道,scan作用是扫描一个表。具体来说,scan命令需要指定表名,以及可选的字典查询器。查询器中指定一个或多个如下条件:时间范围,过滤器,返回的行数,开始的行,结束的行,行前缀过滤器, 时间戳,最大长度或返回的列,缓存还是原始数据,版本,全部指标或部分指标。
如果在命令中不指定列,会返回全部的列。当需要返回所有列的时候,在列族后面不指定列限定名。
有两种方式指定过滤器:
(1)使用过滤字符串:关于这点的更多信息可以查看有关该过滤器语言的文档,在HBASE的JIRA(一个需求管理系统)中查看第4176号需求。下图是该需求的说明。

(2)使用过滤器的全包名。
如果需要查看scan结果的全部指标,配置参数ALL_METRICS需要设置为true。或者,我们只需要补发指标,那么可以通过指定关心的指标即可。
示例:
查看表的全部内容:
| hbase> scan 'hbase:meta' |

查看表的部分列:COLUMNS中指定需要查看的列,多列时通过逗号隔开。
| hbase> scan 'hbase:meta', {COLUMNS => 'info:regioninfo'} |

限定行个数和开始行查看部分列:LIMIT指定返回的行数,STARTROW指定开始行。
hbase> scan 'ns1:t1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'} hbase> scan 't1', {COLUMNS => ['c1', 'c2'], LIMIT => 10, STARTROW => 'xyz'} |

设定时间戳查看部分列:TIMERANGE指定开始和结束的时间戳
| hbase> scan 't1', {COLUMNS => 'c1', TIMERANGE => [1303668804, 1303668904]} |

倒序查看:
| hbase> scan 't1', {REVERSED => true} |

查看HBase的全部指标:
| hbase> scan 't1', {ALL_METRICS => true} |

查看部分指标:
| hbase> scan 't1', {METRICS => ['RPC_RETRIES', 'ROWS_FILTERED']} |
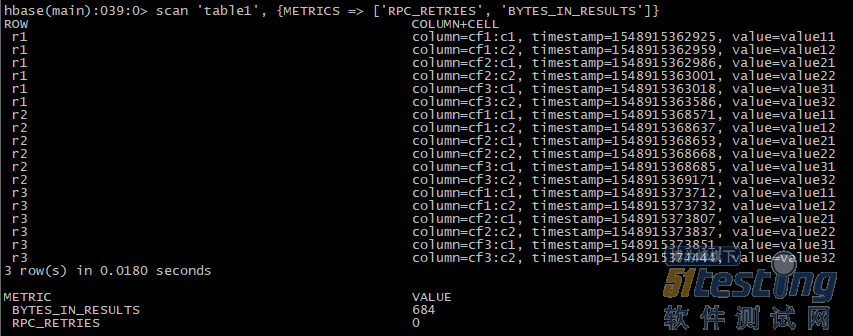
指定过滤器和过滤内容进行查看:scan支持非常多、非常丰富的过滤器,通过ROWPREFIXFILTER指定符合条件的rowkey,QualifierFilter指定列限定名,TimestampsFilter指定时间戳的起止。
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => " (QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"} |

指定分页过滤器,查看符合条件的页:参数为返回的页数和开始的页数。
hbase> scan 't1', {FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)} |

按时间轴一致性读取:HBase默认按强一致性读取(Consistency.STRONG),设定为TIMELINE可以按时间轴一致性读取
| hbase> scan 't1', {CONSISTENCY => 'TIMELINE'} |

2.3 Scan过滤器相关的Java API
从上面的介绍可以看到,命令行下的Scan参数非常丰富,能够实现我们非常复杂的查询请求。我们知道,MySQL的JDBC API中是可以直接执行SQL语句的,查询结果会以ResultSet对象返回。而HBASE不同,原生态的HBASE的Java API是以过滤器的方式提供的查询功能,无法执行原始的命令。通过环境配置,Apache Phoenix可以将HBASE转换为关系型数据存储,但需要对集群服务器进行配置修改。所以还是需要使用HBASE的Java API满足查询的需求。
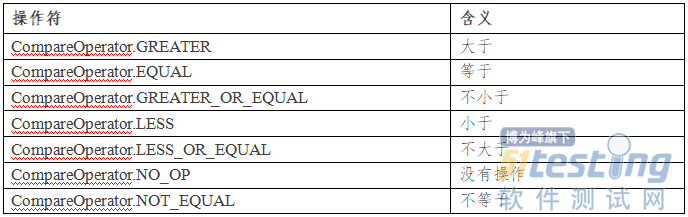
HBASE的Scan过滤器相关的Java API分为三类,分别是操作符、比较器和过滤器,决定了一个查询的操作关系(是大于还是小于),以什么方式比较(字符还是正则表达式),以及过滤的内容(是rowkey还是列)。具体介绍如下。
操作符:HBASE提供了枚举类型的变量来表示这些抽象的操作符。
比较器:比较器作为过滤器的核心组成之一,用于处理具体的比较逻辑,例如字节级的比较,字符串级的比较等。这些类都是Comparable接口的实现类。

过滤器:过滤器是Scan过滤的核心,通过操作符和比较器构造。HBASE支持的过滤器非常多,下表中加粗的为常用的过滤器。过滤器都是FilterBase的直接过间接子类。


2.4 HBASE其他命令
创建表
| create 'table1', {NAME => 'cf1', VERSIONS => 1}, {NAME => 'cf2', VERSIONS => 1}, {NAME => 'cf3', VERSIONS => 1} |
上述命令创建了一个名为“table1”的,具有三个列族的表。
删除表
disable 'table1' drop 'table1' |
删除表要进行两步,首先disable,再drop。
插入数据
| put 'table1', 'r1', 'f1', 'v1' |
不指定列名插入数据。
put 'table1', 'r2','cf1:c1','value11' put 'table1', 'r2','cf1:c2','value12' put 'table1', 'r2','cf2:c1','value21' put 'table1', 'r2','cf2:c2','value22' |
指定列名插入数据。
删除数据
| delete 'table1','r1','cf1:' |
删除表r1行的cf1下的没有列名的数据,注意不是删除cf1下的全部列。
delete 'table1','r2','cf1:c1' delete 'table1','r2','cf1:c2' delete 'table1','r2','cf2:c1' delete 'table1','r2','cf2:c2' |
删除指定行、指定列的数据。
3、像MySQL一样查询HBASE
3.1 Scan的Java API使用
通过Java API进行HBASE的查询是很方便的,下面的例子是使用RowFilter的例子。

首先连接HBASE,填入IP和端口,之后设置查询条件进行查询并打印内容,最后断开连接。在设置查询条件时,首先获取需要查询的表,之后创建过滤器Scan。通过addColumn指定查询后显示的列。然后创建行RowFilter,操作符为等于,比较器为二进制,即查询rowkey等于“r1”的内容。setFilter后通过getScanner执行查询,最后通过ResultScanner的遍历打印查询结果。结果如下。

类比于MySQL,上述代码相当于执行如下SQL语句。
| SELECT cf1:c1,cf2:c2 FROM table1 WHERE rowkey=’r1’; |
3.2查询HBASE的Java程序设计
通过上述示例可以看到,通过Java API可以完成类似MySQL的查询。而实际的测试中,在接口结果验证时,我们需要通过外部参数如同传递SQL语句一样,传递对HBASE的查询需求,所以需要设计类似的机制。
事实上,在测试中对数据的验证,需求相对是比较固定的,如查询某个key的值是否存在,满足某个条件的行数,满足某个条件的列的结果等等。所以本设计就针对实际使用设定固定的查询需求,对不同的查询需求调用适当的Scan过滤器。
3.2.1总体程序设计
HbaseDbOperator
该类为提供查询服务的类,接受查询的参数,分析查询需求,调用特定的查询函数返回查询结果。

HbaseDbOperator继承DataBaseOperator,这样可以使得多种数据库的接口一致。HbaseDbOperator实例化时接受数据库的url和配置文件,其中url确定查询的数据IP和端口,配置文件是为了获取Hadoop的host名称。实际查询时调用runSql函数,变量为查询的语句,查询语句为JSON格式,类似如下。
{type:"select_rowkey", table:"table1", select:{rowkey:row_key}, condition:{"cf1:c1":"r1"}} |
HbaseQueryParser完成JSON格式的解析,获取查询的类型,在后续的HBASE操作中也提供JSON格式中内容的输出。之后根据特定的查询类型调用HbaseDbUtil的特定函数完成查询。
3.2.2 HbaseDbUtil
该类提供对HBASE的连接、查询等操作,是完成功能的核心类。

HbaseDbUtil是一个工具类,完成HBASE数据库的连接、断开,并根据需要进行相应查询,具体查询的时间在后面详细介绍。
HbaseDbConnetPara和HbaseQueryParser
HbaseDbConnetPara和HbaseQueryParser是两个辅助类。HbaseQueryParser如前面所说,完成对查询语句的JSON解析,将查询类型、查询提交等进行解析,供其他类调用。
HbaseDbConnetPara是HbaseDbOperator构造函数中实例化的,通过数据库的url、hosts文件内容完成数据参数的初始化,在HbaseDbUtil的数据库连接中直接使用。
3.2.3 Select_RowKey_001的实现
各类的查询实现由相似之处,以Select_RowKey_001的实现进行说明。这类查询面对的需求是查询特定内容的rowkey值,查询条件的JSON类似如下。
{type:"select_rowkey", table:"table1", select:{rowkey:row_key}, condition:{"cf1:c1":"value111"}} |
类比的SQL语句是SELECT rowkey AS row_key FROM table1 WHERE cf1:c1 LIKE ‘value111’;
在HbaseDbUtil中实现如下。

首先根据参数获取需要查询的表,之后建立过滤器,设定过滤器之后通过getScanner发起查询,最后将满足条件的内容以JSON格式返回。
测试代码如下。

查询结果:{row_key:r1}。
3.2.4其他查询类型
Select_Timestamp_002
查询满足条件内容的最新的时间戳,查询语句的JSON类似如下:
{type:"select_timestamp", table:"table1", select:{"timestamp":"time1"}, condition:{"rowkey":"r1","cf1:c1":"value111"}} |
相当于查询如下SQL:
SELECT timestamp AS time1 FROM table1 WHERE cf1:c1 LIKE ‘value111’; Select_Count_003 |
查询满足条件内容的条数,查询语句的JSON类似如下:
{ type:"select_count", table:"table1", select:{"count":"cnt"}, condition:{"rowkey":"r1","cf1:c1":"value111"}} |
相当于查询如下SQL:
SELECT count(*) as cnt FROM table1 WHERE rowkey=’r1’ and cf1:c1 LIKE ‘value111’; Select_Count_Equal_006 |
查询满足条件内容的条数(与2的区别是like和等于),查询语句的JSON类似如下:
{ "type":"select_count_equal", "table":"table1", "select":{"count":"cnt"}, "condition":{"rowkey":"r1","cf1:c1":"value111"}} |
相当于查询如下SQL:
| SELECT count(*) as cnt FROM table1 WHERE rowkey=’r1’ and cf1:c1=’value111’; |
4、总结
HBASE在大数据系统中被普遍应用,是非常优秀的NOSQL数据库,但对于测试工程师而言,需要颠覆关系型数据库的理念进行测试。无形中增加了测试难度,本文主要介绍了一种使用Java API实现的查询HBASE的程序设计,可以像查询MySQL一样查询HBASE。文中给出的基本的程序实现,通过这种思路可以在接口测试、功能自动化测试中使用,并且可以界面完成一个易用的测试工具。
......
查看更多精彩内容,请点击下载:
版权声明:本文出自《51测试天地》第五十三期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












