

随着Internet的普及与迅速发展,企业业务量的迅速加大, IT系统承载的负荷越来越重,系统性能的好坏严重影响了企业对外提供的服务质量。应用性能诊断分析是性能测试实施过程的重要环节。
目录
●通用的性能测试实施过程
●应用性能诊断分析方法-分层法
●应用性能诊断分析方法-分段法
●总结
一. 通用的性能测试实施过程

1、需求分析
性能测试需求是应用需求的衍生。需要借助于相关的理论知识和相关领域的经验积累,对性能测试需求进行分析整理。需要明确下面相关内容:
测试目标
测试范围
测试策略
测试模型构建
测试环境
进度计划
准入、准出和暂停准则
职责分工
度量指标
2、环境准备
在实施过程中需要监控主机、中间件等资源,我们需要提前准备相关监控工作:
监控工具部署
相关参数配置
监控脚本部署和测试
性能测试工具部署
3、实施压测
脚本录制、编写
测试场景制定
场景压测过程监控
监控数据收集
4、结果分析及优化
利用监控到的数据结果分析系统性能情况,并定位系统的性能瓶颈所在并进行性能优化。评价系统的性能情况可以借助相关指标:
TPS
响应时间
主机资源情况:CPU、内存、IO、磁盘
事务通过率
性能优化通过可以从以下几方面进行优化:
代码层
数据库sql
配置参数调整
网络
硬件资源
这4个环节,每个都有很多细节的内容,在这里就不一一去细讨论了,我们重点看后边两部分关于性能监控、诊断分析方面的内容。
二. 应用性能诊断分析方法-分层法
应用性能诊断分析涉及到多层面的分析,包括操作系统、中间件、数据库、系统日志监控数据等等。我们主要从应用程序、中间件、网络、操作系统、数据库这5个维度来分析。这5个部分贯穿了整个应用从前端到后端的性能测试的整个过程,通过这5个层面的分析能诊断出系统性能问题是什么原因产生的。
对于不同层面用不同的指标去度量,通过度量指标来分析定位性能问题,下面是5个层面典型度量指标:
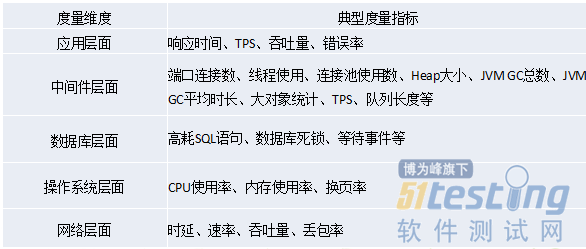
每个层面关注的度量指标
下面我们来看一个简单的案例:
该案例主要从应用、主机资源和中间件三个维度来分析,它是Apache/Tomcat+Linux+Oracle的架构。
Web服务器:Apache
应用服务器:Tomcat
操作系统:Redhat6
数 据 库:Oracle 11
采用主流的性能测试工具Loadrunner进行压测。
监控是诊断分析的基础,收集监控数据就像福尔摩斯探案时查找各种蛛丝马迹!
我们采用分层监控的方法。
例如,Linux监控使用开源的Nmon进行Linux系统性能数据采集。
主要关注:
CPU占用率
内存使用情况
磁盘I/O速度、传输和读写比率
文件系统的使用率
网络I/O速度、传输和读写比率、错误统计率与传输包的大小
消耗资源最多的进程
计算机详细信息和资源
页面空间和页面I/O速度
用户自定义的磁盘组
网络文件系统
启动该程序,使用如下命令:
./ nmon_x86_fedora5 –fT –s 5 –c 100
或在后台运行Nmon,使用如下命令:
nohup ./ nmon_x86_fedora5 –fT –s 5 –c 100
通过sort命令可以将Nmon结果文件转换为CSV文件。
# sort -A test1_090308_1313.nmon > test1_090308_1313.csv
执行sort命令后,即可在当前目录下生成test1_090308_1313.csv文件。
Web服务器Apache监控:
修改/conf/httpd.conf配置文件,把server-status打开。
Apache监控信息:
Total Accessess:总的访问量。
Total kBytes:总的字节数。
CPULoad:当前Apache服务器所消耗的CPU。
ReqPerSec:每秒请求数。
BytesPerSec:每秒传输的字节数。
IdleWorkers:空闲的线程数。
BytesPerReq:每秒请求的字节数。
BusyWorkers:目前服务的线程数。
这些信息可以通过Shell脚本实时写入文件中,通过Nmon工具进行分析;也可以通过LoadRunner获取并生成监控图表。
应用服务器Tomcat监控
方法1:通过Tomcat自带的Manager模块获取包括JVM、连接线程相关的信息。
方法2:通过编写Shell脚本监控。
方法3:用JAVA附带的工具Jconsole,重点监控JVM。
在Excel中编写一个小工具,把监控收集的数据生成图表
还有其它层面的性能监控配置,这里就不再详细描述了。
总结起来,各个层面的监控方法,工具各异,需要关注的性能指标也不同。
有了监控的基础数据,后边我们再看诊断分析的方法。
通常我们是采用从上而下的方法。
业务指标+前端页面性能分析
压测100个用户浏览器无缓存的情况:

图中绿色代表的是vuser的数目,橙色代表的是选择办证日期事务响应时间,蓝色代表的是进入预约申请事务响应时间,灰色代表的是选择办证地点事务响应时间,从此图可以看出,选择办证日期响应时间一直维持在80秒以上,平均的响应时间达到了140秒。进入预约申请页面,当用户数达到100时,平均响应时间直线上升,从开始的16秒上升到67秒,运行了3分10秒后,响应时间达到最高的126秒。选择办证地点是随着100个用户持续运行,响应时间不断增加。
从图1中事务平均响应时间中观察发现共有三个事务的响应很长,分别是:选择办证日期140S、进入预约申请界面57S、选择办证地点28S。通过对进入预约申请界面事务的页面进行分析,发现有JS\JSON消耗资源比较严重,如下图,处理满意度调查的json的响应时间超过了10S,处理基本信息业务逻辑的JS的响应时间超过了15S,这两个业务逻辑的响应时间在单个用户请求时,已经远超过预期。

处理满意度调查的json

处理基本信息业务逻辑的JS
而在进入预约申请的这个事务,页面上加载图片,所消耗的资源也是很多,如图4中首页图片资源消耗情况,其中一张index开头的图片大小差不多1M,首页加载的页面的总和差不多4M左右,这大大降低了客户访问次页面的速度。建议把图片进行压缩传输。
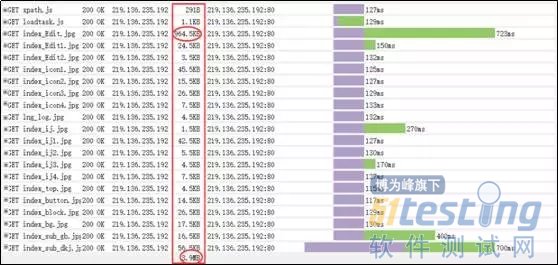
选择办证地点的这个事务的平均响应时间是在27S,而监控该事务的前台页面发现,在此页面上出现了js\json的响应时间过长,最长有达到30多秒,一般情况下,客户端发送服务器请求,响应时间超过30S,就设置为超时,这种响应时间超慢的逻辑,要求修改以满足用户需求,如图5所示。
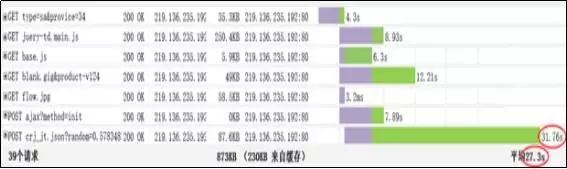
加载办证地点的json资源消耗情况
接下来分析后端
Web服务器层分析
由于Apache和Tomcat装在一台机器上,通过查看的这台机器的日志输出,Apache和Tomcat都没有发现错误日志,tomcat也未出现404错误,监控这台机器的系统资源情况看出,CPU、I/O、内存都在合理的区间内,具体可以参照测试方案资源使用度量指标,具体见以下3张图。

系统资源整体情况

CPU资源总体使用情况
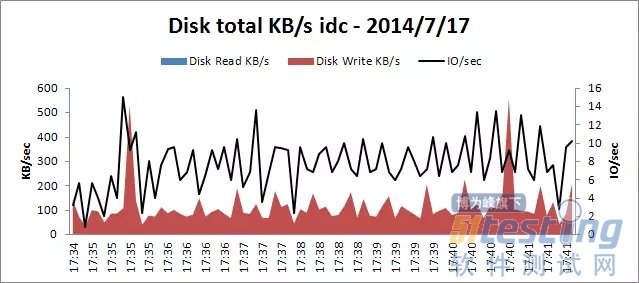
磁盘读写/IO资源使用情况
而在并发200时,Apache的连接数(BusyWorkers)达到226个,总共256个,如果加大并发用户数,Apache的连接数需要增加,如下图所示。

应用服务器层分析
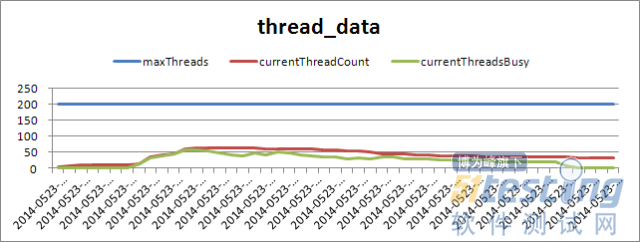
下图中的Tomcat 的线程使用情况可以看出,当前使用的线程(currentThreadCount)和当前忙碌的线程(currentThreadBusy)都在100的范围内,空闲率很高,而此时主机的cpu\内存运行正常,监控后台日志,未发现有明显问题,由此得出Tomcat在压测过程中运行稳定,具体情况请看下面的图片。
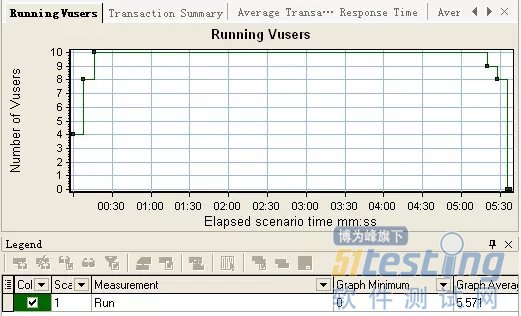
虚拟用户数

Tomcat的线程使用情况
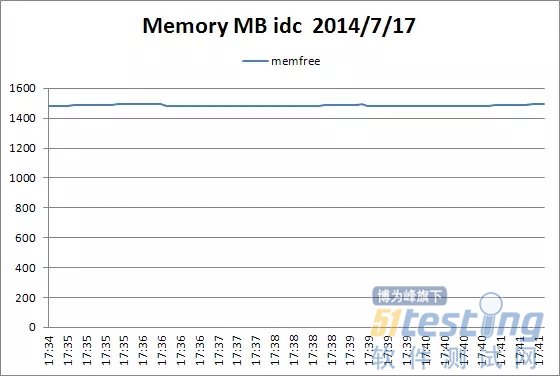
主机空闲内存资源情况
这里没有关注JVM的监控,可能会忽略掉Java内存泄漏的问题!
数据库服务器层分析
下面的四个图中是在压测时数据库主机的各项资源使用情况,从四副图的变化趋势可以看出,内数据库主机在压测时,各项资源使用情况都在合理范围内,因此,数据库表现正常。
具体见下面数据分析图。

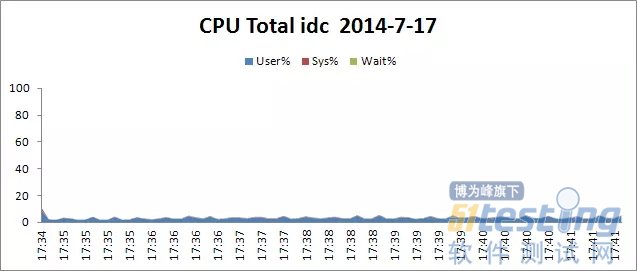
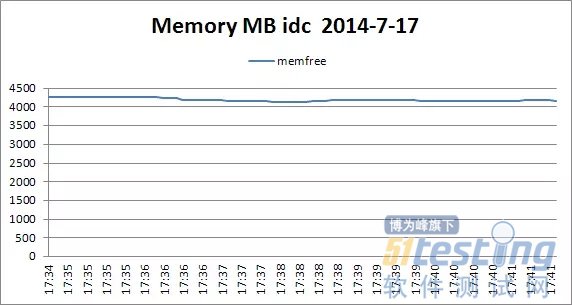
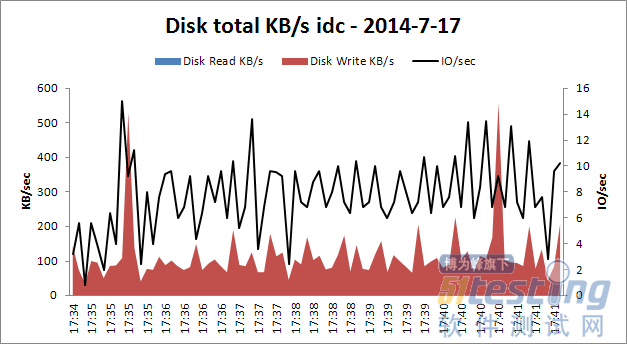
这里没有对数据库本身的性能监控数据进行分析,例如等待时间、慢查询等。
整体结果分析
系统在运行100个用户无浏览器缓存的情况下,应用服务器、数据库服务器的CPU和内存资源空闲。
在LR的报告中,进入预约申请界面事务,平均响应时间约是57S,与要求的响应时间相差甚远。从以上的结果中,逐一分析:
对图片对象、js\json监控的数据进行分析。需要对消耗资源大页面文件采用压缩传输方式。
对加载时间过长的业务逻辑进行精简或者用其它方式实现。
对Apache分析,随着并发数的增加,而Apache的连接数一直处于峰值,建议增加apache的最大连接数。由于Apache和Tomcat共用一台主机,系统上线后随着用户数的增多,性能可能会相互影响,建议分开部署。
以上是对应用、中间件和主机进行性能诊断分析,没有深入到应用的代码层和数据库层。应用性能诊断分析应该围绕应用程序、中间件、网络、操作系统、数据库5个维度,分析应用程序在Web层、中间件层、数据库层的调用情况,组合成完整的调用链,从而形成清晰的业务视图,同时在应用程序方面需要深入定位到代码层,才能准确、高效定位性能问题。
方法总结:
逐层分析监控数据,找出性能隐患。
前面介绍的分层法诊断分析需要对操作系统、中间件、数据库、Web服务器各层分别进行监控,收集数据后进行诊断分析。
优点:
可以在各个层面分析得很透彻,如果团队规模大,力量强的话,可以结合各种角色,例如中间件工程师、DBA来综合分析。
通过关联分析可以在某个层面找到一些尚未发生的性能隐患。
缺点:
每个层面的监控分析所需工具、指标分析能力要求比较深入。
难以形成业务流调用链层面的性能分析,很难直观地看到性能瓶颈所在。
难以深入到代码层进行性能诊断。
三. 应用性能诊断分析方法-分段法
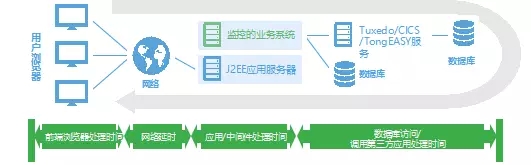
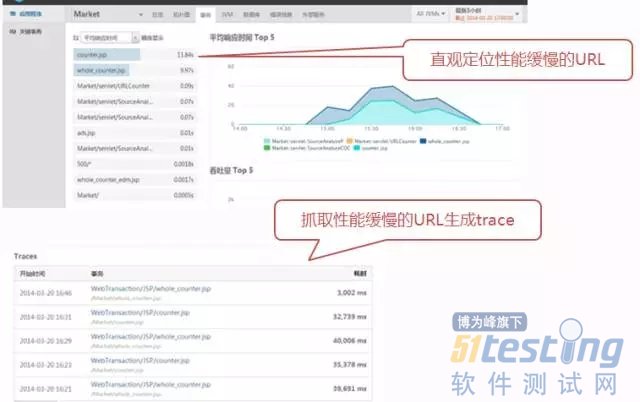
借助APM工具查找性能瓶颈,定位性能问题,及时优化。
APM这类工具通过分段收集业务流性能指标,可以弥补前面的分层法诊断分析的缺点,例如通过对中间件JVM的性能数据收集,可以深入分析代码调用、SQL调用等业务层性能问题;并且从URL到中间件Java代码,再到数据库SQL,各段的性能数据是通过业务流调用链串接起来的,所以可以从业务层面很直观地看到哪些业务流程有性能问题,性能瓶颈在哪段。
由于时间关系,APM在性能测试的应用这次就不作详细介绍了,下次有机会再详细分享。
四. 总结
1、性能测试过程中性能监控和诊断分析是比较关键的环节,它决定了性能测试的最终效果,能否得到很好的优化就看诊断分析的深入程度了。
2、性能诊断分析的方法可以采用分层法和分段法,各有一些优缺点,我们可以考虑综合应用。这次分享主要介绍了分层法在性能诊断分析中的应用,这种方法要求对各个层面(前端页面、网络、Web服务器、中间件、数据库)的监控和指标分析都要能涵盖和深入分析,并且要再把各层的数据关联起来分析,比较依赖人在软件系统性能方面的知识结构和经验。
Q & A
Q1:我们的测试环境在大多数情况下是不能与真实生产环境在硬件上达到1比1的配比。在此种差异下的分层压力测试,如何能客观的分析出系统的实际瓶颈在哪里,如何进行不同硬件环境下业务处理能力的换算?
A1:我们通常的做法是把测试环境的资源分不同的级别,分别压测,做容量预估,再推测生产环境的业务处理能力。
Q2:我们面临的尴尬局面是,对不同的硬件环境,性能测试组被要求做与生产一致的数据量进行压力测试,以此来评估生产环境的新业务处理能力。这是难以实现的,请问有什么办法解决吗?
A2:现在很多企业倾向于在运维环境引入APM这类工具,在线上实施监控,出性能问题了,能直接定位到代码、SQL,给开发及时的反馈。这也就是DevOps的理念了。
Q3:请问每个业务不能直接定义并发数,对吗?
A3:可以直接定义,但是缺乏依据,不好拍,例如从注册用户数的不同角色,使用的频繁度,等方面去拍。loadrunner可以针对每个业务场景定并发用户数的。
Q4:请问关于并发用户,脚本中的thinktime 到底要不要忽略呢?
A4:看是做的什么类型的测试,如果要做负载测试,就加上思考时间,如果是做压力测试就考虑去掉,并且在某些并发点加上集合。
Q5:测试用例的选择,以及脚本中是否有参数化对于测试结果的影响比较大,怎样去做这一部分的设计呢?
A5:测试用例的筛选会有些套路。比如通过评价业务的关键程度,使用频繁度等方面去筛选。是否参数化就要结合系统设计情况了,要评估不同数据类型对性能是否有影响。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












