

我们通过减少查询中的不必要的读取操作从而使得查询的性能得到提升。一个查询在数据库中执行的读操作越多,那么就对磁盘,CPU,内存的压力越大。除非整个数据库的数据全在在内存中,否则每次的读操作都会把数据从磁盘读入到内存中,然后返回。
一个查询在读取一个资源的时候,通过加锁会阻止其他的查询对这个资源进行修改,此时其他要操作这个资源的查询就需要等待,从而导致了延时。
诚然,有些等待是必须的,读取操作也是必须的,但是一些因为我们代码或者设计导致的过度的读取操作和等待,那就会严重影响性能,尤其是当数据库的访问量开始变大的时候。
可以说在SQL Server中,最高效的读取数据方式就是通过索引去获取数据。如果在数据表中存在缺失索引的问题,结果可想而知。
在本篇中,我们将会讨论下面几个议题:
● 如何识别缺失索引性能问题
● 识别没有用的索引
● 如何解决上面的问题
确实本篇讲述的内容涉及到了一些与数据库性能调优的话题,对于调优而言,难点很多时候在于如何正确的找出性能问题。
下面,我们首先来看看缺失索引。
缺失索引
SQL Server可以在表字段上面建立索引,从而使得Where和Join这样的语句执行的更快。当查询优化器在优化一个查询的时候,它会保存一些来暗示哪些列上可能建立索引之后可能性能会更快的信息。我们可以通过动态管理视图sys.dm_db_missing_index_details来查看,运行如下查询

查询的结果如下:
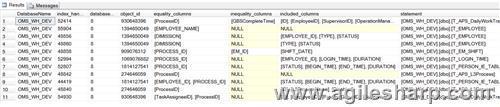
下面,我们就来稍微的解释一下结果中主要字段的含义:
字段名字 | 说明 |
DatabaseName | 告诉我们是哪一个数据库上面存在缺失索引的问题 |
equality_columns | 如果在某个字段上面进行了相等的操作,例如Name=’Agilesharp’,在Name字段上面进行了判等的操作,如果查询优化器认为这个Name上面缺失索引,那么这个Name就会出现在上述查询的结果中。 多个字段,用逗号分割 |
inquality_columns | 在某个字段上进行了不等的操作,例如ID>1等,如果ID上面存在缺失索引,那么ID就会出现在这里 |
Included_columns | 告诉我们那些数据列可以作为索引包含列放在索引中,从而减少书签查找的开销 |
Statement | 告诉哪一个表上面存在缺失索引的问题 |
当然,上面的DMV查询所得到的结果只是推荐结果,至于是否要去在相应的列上面建立索引,还需要进行综合的分析,不能单靠一方面来判断,例如,我们可以在去制定一些计划去运行SQL Profiler去跟踪数据库,然后分析跟踪的数据,并且分析这个列的数据的分布情况,分析数据的密度和差异性,而且还可以进一步的分析列的统计信息,然后决定是否要加索引。
注:我也正在写SQL Server Profiler的文章,还没有发布,请大家耐心等待。另外SQL Server的调优是个非常深的话题,大家可以通过我这里的一些问题在掌握一些所谓的小技巧,起到一个抛砖引玉的作用!












