


机器学习、人工智能各类KNN算法层出不穷,DBSCAN具有强代表性,它是一个基于密度的聚类算法,最大的优点是能够把高密度区域划分为簇,能够在高噪声的条件下实现对目标的精准识别,但该算法当前已远不能满足人们对于高效率、高精准度的算法要求,由此FDBSCAN算法应运而生。
01
FDBSCAN聚类算法在KD-树的加持下,时间复杂度达到了O(nlogn),目标识别效率已指数级别上升。

02
Kd-树:它是一种树形结构,主要应用于多维空间关键数据的搜索。由于他的增加、删除、查询时间复杂度都是O(logn),所以才造就了FDBSCAN算法的高效率。
想必大家对于树形结构也不是特别陌生,但是对于四维及以上的树形结构,就难以体现其具体的结构了。kd-树的三维立体空间如下图所示:

03
FDBSCAN算法的高效就体现在它使用了KD树作为自己遍历数据的工具,通过树形结构,能够最大限度的提高遍历效率。在算法执行之前,首先对待处理数据创建Kd-树,使用KD树自有的空间搜索算法来进行数据划分。可以看到整个数据划分流程图:
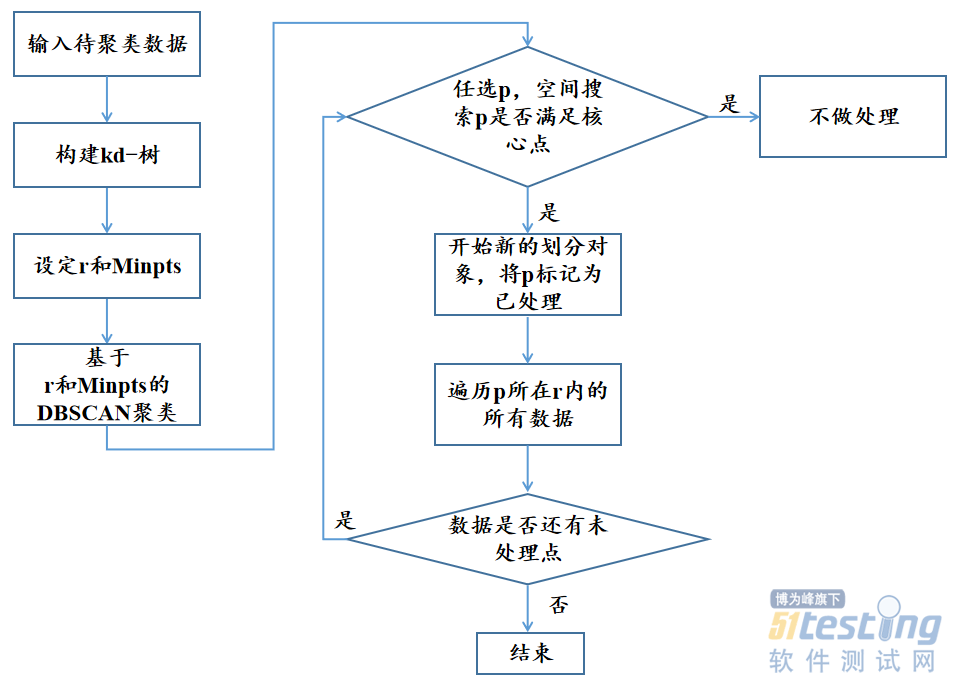
04
下面对FDBSCAN算法伪代码进行展示:
FDBSCAN算法伪代码:
DBSCAN(D, eps, MinPts)
C = 0 //类别标示
for each unvisited point P in dataset D //遍历
mark P as visited //已经访问
NeighborPts = regionQuery(P, eps) //计算这个点的邻域
if sizeof(NeighborPts) < MinPts //不能作为核心点
mark P as NOISE //标记为噪音数据
else //作为核心点,根据该点创建一个类别
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts) //根据该核心店扩展类别
expandCluster(P, NeighborPts, C, eps, MinPts)
add P to cluster C //扩展类别,核心店先加入
for each point P' in NeighborPts //然后针对核心店邻域内的点,如果该点没有被访问
if P' is not visited
mark P' as visited //进行访问
NeighborPts' = regionQuery(P', eps) //如果该点为核心点,则扩充该类别
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
if P' is not yet member of any cluster //如果邻域内点不是核心点,并且无类别,比如噪音数据,则加入此类别
add P' to cluster C
regionQuery(P, eps) //计算邻域
return all points within P's eps-neighborhood
kdtree (list of points pointList, int depth) {
var tree_node node;
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth+1);
node.rightChild := kdtree(points in pointList after median, depth+1);
return node;
}
05
机器学习、深度学习、图像识别、人工智能、大数据、区块链、互联网+等各种新兴技术层出不穷,人们对于算法的效率、精度要求也是越来越严格。各位大佬们,传统DBSCAN聚类算法对于一个高分辨率,数以千百万级的像素点的图像来说,是远远不够的,那就让FDBSCAN算法来助你一臂之力吧!
版权声明:本文出自51Testing会员投稿,51Testing软件测试网及相关内容提供者拥有内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。











