

引言
在开始正式内容之前,先给大家分享一个真实的案例。
某客户在阿里云上使用 K8s 集群部署了许多自己的微服务,但是某一天,其中一台节点的网卡发生了异常,最终导致服务不可用,无法调用下游,业务受损。我们来看一下这个问题链是如何形成的?
1、ECS 故障节点上运行着 K8s 集群的核心基础组件 CoreDNS 的所有 Pod,它没有打散,导致集群 DNS 解析出现问题。
2、该客户的服务发现使用了有缺陷的客户端版本(nacos-client 的 1.4.1 版本),这个版本的缺陷就是跟 DNS 有关——心跳请求在域名解析失败后,会导致进程后续不会再续约心跳,只有重启才能恢复。
3、这个缺陷版本实际上是已知问题,阿里云在 5 月份推送了 nacos-client 1.4.1 存在严重 bug 的公告,但客户研发未收到通知,进而在生产环境中使用了这个版本。
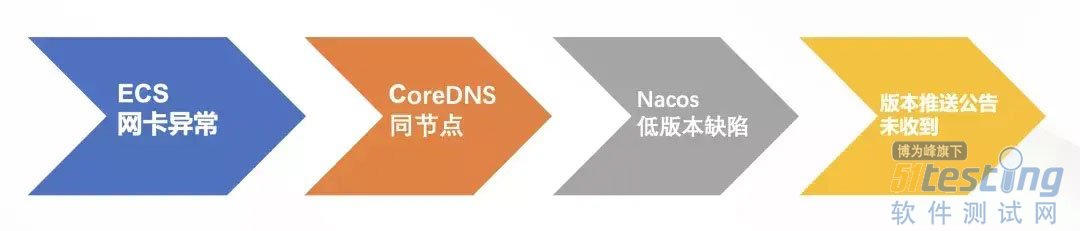
风险环环相扣,缺一不可。
最终导致故障的原因是服务无法调用下游,可用性降低,业务受损。下图示意的是客户端缺陷导致问题的根因:
1、Provider 客户端在心跳续约时发生 DNS 异常;
2、心跳线程正确地处理这个 DNS 异常,导致线程意外退出了;
3、注册中心的正常机制是,心跳不续约,30 秒后自动下线。由于 CoreDNS 影响的是整个 K8s 集群的 DNS 解析,所以 Provider 的所有实例都遇到相同的问题,整个服务所有实例都被下线;
4、在 Consumer 这一侧,收到推送的空列表后,无法找到下游,那么调用它的上游(比如网关)就会发生异常。
回顾整个案例,每一环每个风险看起来发生概率都很小,但是一旦发生就会造成恶劣的影响。
微服务高可用方案
首先,有一个事实不容改变:没有任何系统是百分百没有问题的,所以高可用架构方案就是面对失败(风险)设计的。
风险是无处不在的,尽管有很多发生概率很小很小,却都无法完全避免。
在微服务系统中,都有哪些风险的可能?
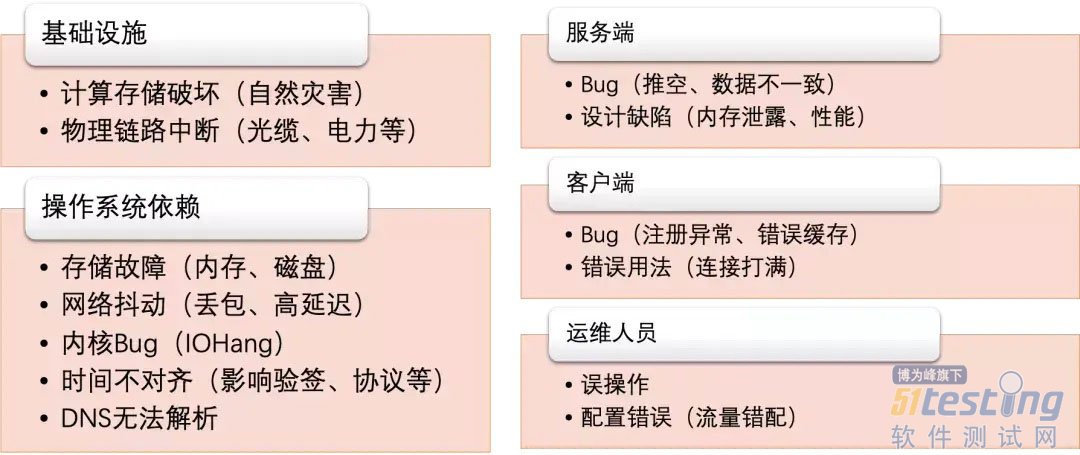
这只是其中一部分,但是在阿里巴巴内部十几年的微服务实践过程中,这些问题全部都遇到过,而且有些还不止一次。虽然看起来坑很多,但我们依然能够很好地保障双十一大促的稳定,背后靠的就是成熟稳健的高可用体系建设。
我们不能完全避免风险的发生,但我们可以控制它(的影响),这就是做高可用的本质。
控制风险有哪些策略?
注册配置中心在微服务体系的核心链路上,牵一发动全身,任何一个抖动都可能会较大范围地影响整个系统的稳定性。
策略一:缩小风险影响范围
集群高可用
多副本:不少于 3 个节点进行实例部署。
多可用区(同城容灾):将集群的不同节点部署在不同可用区(AZ)中。当节点或可用区发生的故障时,影响范围只是集群其中的一部分,如果能够做到迅速切换,并将故障节点自动离群,就能尽可能减少影响。
减少上下游依赖
系统设计上应该尽可能地减少上下游依赖,越多的依赖,可能会在被依赖系统发生问题时,让整体服务不可用(一般是一个功能块的不可用)。如果有必要的依赖,也必须要求是高可用的架构。
变更可灰度
新版本迭代发布,应该从最小范围开始灰度,按用户、按 Region 分级,逐步扩大变更范围。一旦出现问题,也只是在灰度范围内造成影响,缩小问题爆炸半径。
服务可降级、限流、熔断
·注册中心异常负载的情况下,降级心跳续约时间、降级一些非核心功能等。
· 针对异常流量进行限流,将流量限制在容量范围内,保护部分流量是可用的。
· 客户端侧,异常时降级到使用本地缓存(推空保护也是一种降级方案),暂时牺牲列表更新的一致性,以保证可用性。
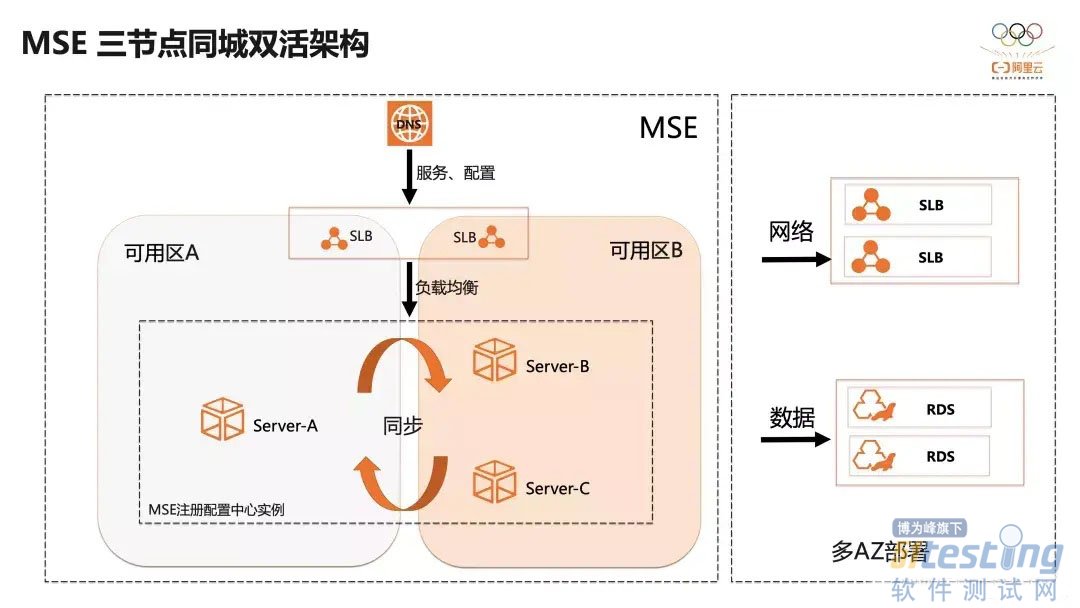
如图,微服务引擎 MSE 的同城双活三节点的架构,经过精简的上下游依赖,每一个都保证高可用架构。多节点的 MSE 实例,通过底层的调度能力,会自动分配到不同的可用区上,组成多副本集群。
策略二:缩短风险发生持续时间
核心思路就是:尽早识别、尽快处理。
识别 —— 可观测
例如,基于 Prometheus 对实例进行监控和报警能力建设。
进一步地,在产品层面上做更强的观测能力:包括大盘、告警收敛/分级(识别问题)、针对大客户的保障、以及服务等级的建设。
MSE注册配置中心目前提供的服务等级是 99.95%,并且正在向 4 个 9(99.99%)迈进。
快速处理 —— 应急响应
应急响应的机制要建立,快速有效地通知到正确的人员范围,快速执行预案的能力(意识到白屏与黑屏的效率差异),常态化地进行故障应急的演练。
预案是指不管熟不熟悉你的系统的人,都可以放心执行,这背后需要一套沉淀好有含金量的技术支撑(技术厚度)。
策略三:减少触碰风险的次数
减少不必要的发布,例如:增加迭代效率,不随意发布;重要事件、大促期间进行封网。
从概率角度来看,无论风险概率有多低,不断尝试,风险发生的联合概率就会无限趋近于 1。
策略四:降低风险发生概率
架构升级,改进设计
1、Nacos2.0,不仅是性能做了提升,也做了架构上的升级:
升级数据存储结构,Service 级粒度提升到到 Instance 级分区容错(绕开了 Service 级数据不一致造成的服务挂的问题);
2、升级连接模型(长连接),减少对线程、连接、DNS 的依赖。
提前发现风险
1、这个「提前」是指在设计、研发、测试阶段尽可能地暴露潜在风险;
2、提前通过容量评估预知容量风险水位是在哪里;
3、通过定期的故障演练提前发现上下游环境风险,验证系统健壮性。
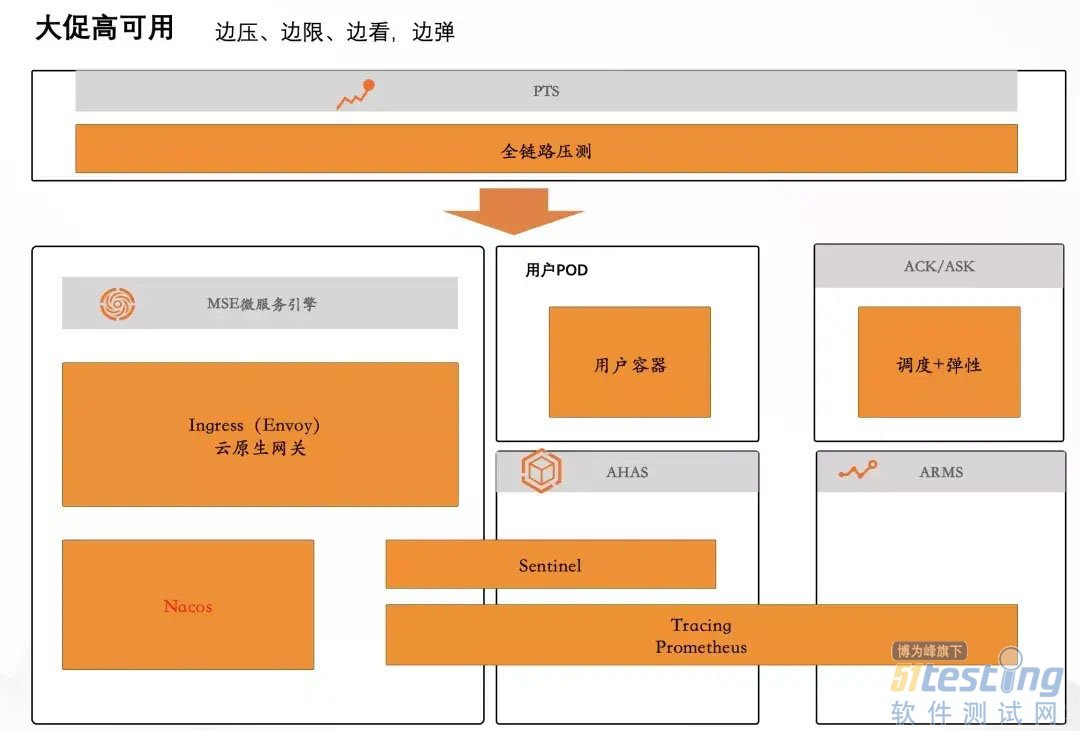
如图,阿里巴巴大促高可用体系,不断做压测演练、验证系统健壮性和弹性、观测追踪系统问题、验证限流、降级等预案的可执行性。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












