

一、如何选择索引
影响优化器的几大因素
一条查询SQL执行需要经过连接器、分析器、优化器、执行器,而选择索引的重任就交给了优化器。
优化器在多个索引中选择目的是为了找出执行代价最低的方案。
影响优化器选择无非就这几个因素,扫描行数、是否使用了临时表、是否使用文件排序。
临时表、文件排序这个两个点会在后期文章给大家慢慢引出,今天只聊扫描行数。
扫描行数越少则访问磁盘数据的次数就越少,消耗的CPU资源越少。
那么这个扫描行数是从哪里取的呢?
扫描行数从何而来?
创建索引一直提倡大家给区分度高的列建立索引,在一个索引上不同值的个数称之为基数(cardinality)。
使用show index from table_name可以查看每个索引的基数是多少。
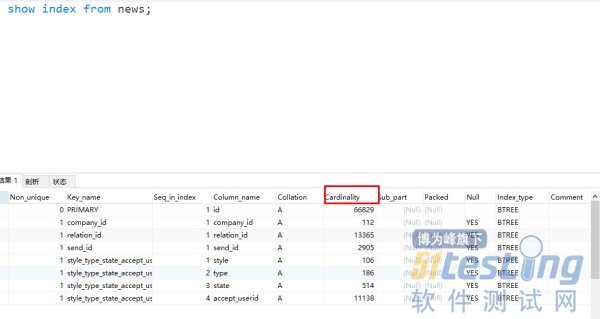
索引基数
索引基数怎么计算
MySQL使用采样统计的方法,会选出N个数据页,每个数据页大小16kb,接着统计选出来的数据页上的不同值就会得到一个平均值,用平均值在乘以索引的页面数得到的结果就是这个索引的基数。
表数据是持续增加或删减的,统计的这个数据也不是时时变化的,当变更的数据超过1/M时会自动触发重新计算。
这个M是根据参数innodb_stats_persistent的值选则的,设置为on值为10,设置为off值为16。
索引基数通过这种方式计算不是精准的但也差不了多少。
为什么优化器选择了扫描行数多的索引?
第一种情况
表增删十分频繁,导致扫描行数不准确。
第二种情况
假设你主键索引扫描行数是10W行,而普通索引需要扫描5W行,这种情况就会遇到优化器选择了扫描行数多的。
在索引那一期文章中知道主键索引是不需要回表的,找到值直接就返回对应的数据了。
而普通索引是需要先拿到主键值,再根据主键值获取对应的数据,这个过程优化器选择索引时需要计算的一个成本。
如何解决这种情况
扫描行数不准确时可以执行analyze table table_name命令,重新统计索引信息,达到预期优化器选择的索引。
二、索引选择异常如何处理
方案一
在MySQL中提供了force index来强制优化器使用这个索引。
使用方法:select * from table_name force index (idx_a) where a = 100;
但别误解force index的使用方法,之前在代码中看到这样一个案例,给查询列使用了函数操作导致使用不上索引,然后这哥们就直接使用force index,肯定不行的哈!
当优化器没有正确选择索引时是可以使用这种方案来解决。
缺点
使用force index的缺点相信大家也知道就是太死板,一旦索引名字改动就会失效。
方案二
删掉误选的索引,简单粗暴,很多索引建立其实也是给优化器的一个误导,直接删掉即可。
方案三
修改SQL语句,主动引导MySQL使用期望的索引,一般情况这种做法使用的很少除非你对系统十分熟悉,否则尽量少操作。
三、总结
优化器选择索引首先会根据扫描行数再由执行成本决定。
当索引统计信息不准确时,使用analyze table 解决。
优化器选择了错误的索引,只用force index来快速矫正,再通过优化SQL语句来引导优化器选择正确的索引,最暴力的手法是直接删除误选的索引。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












