

前言
最近同学要做东西,需要用 B 站的视频对应的弹幕数据做分析,于是请我帮忙爬取 B 站视频的弹幕数据。
对于爬虫而言,我们需要找到对应数据所在的接口,找到接口,就可以找到对应的数据。这个时候我们只需要简单的调用 Python 库进行爬取,输出到文件即可。
目前针对 B 站弹幕爬取有两种方法:
方法一,找到接口数据,编码爬取
方法二,找到 BV号,调用API
这篇博客分别对两种方法进行了整合介绍,并给出了详细的操作流程。
寻找弹幕数据
其实 B 站是提供了弹幕接口的,B站把视频对应的弹幕数据全部放在 xml 文件中,获取的接口是:
1、https://comment.bilibili.com/视频的cid.xml 2、https://api.bilibili.com/x/v1/dm/list.so?oid=视频的cid |
两个接口目前都是可以正常使用的,第一个接口是老版本,第二个接口是新版本。
第一步,到 B站打开对应视频,比如“刺客伍六七”,进入视频播放页面(先不要点击播放)。

第二步,按 F12 键,打开浏览器的控制台,转到 NetWork 部分。

第三步,点击播放,注意观察 NetWork 下面加载的文件,当看到名为 heartbeat 的 xhr 文件时,点击暂停。
heartbeat 的里面记录了该视频的一些特有信息,比如 aid、cid、BVid 等等。一个的视频特有信息都是固定的,比如一个视频只有一个 cid。
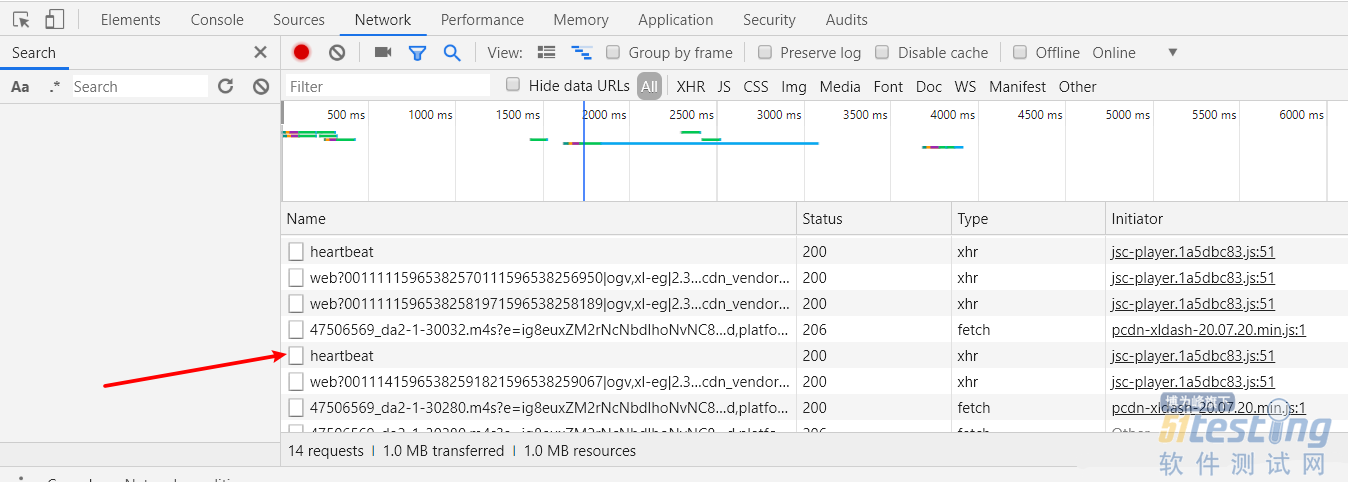
第四步,点击任意一个 heartbeat 文件,在 Headers 标签页中往下翻,就可以找到 cid 了。
可以看到,刺客伍六七第一集的 cid 为 47506569。
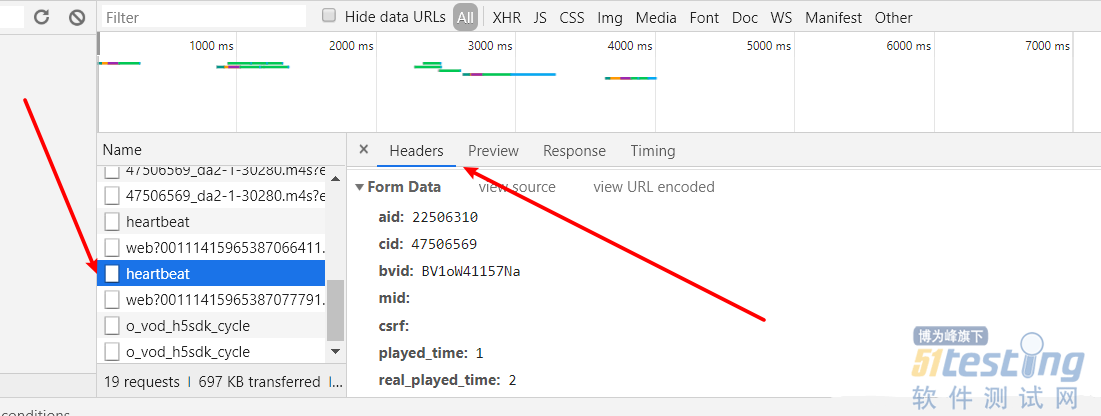
第五步,将 cid 与对应的接口进行拼接,输入在浏览器的地址栏进行查看。
这一步是为了熟悉对应弹幕数据的网页结构,方便之后的编码工作进行数据的提取。如果使用熟练的话则可以跳过此步。

编写爬虫
既然我们已经可以找到了弹幕数据所在的的地方,直接进行爬取即可。大致可以分为以下几步:
·获取整个页面
·提取弹幕数据
·简单的数据预处理
·输出到文件
爬虫编写完成后,每次我们只需要修改文件名和 cid 就可以继续爬取弹幕数据保存到文件中了。
import requests from bs4 import BeautifulSoup import pandas as pd import re # 弹幕保存文件 file_name = '刺客伍六七第一集.csv' # 获取页面 cid = 47506569 url = "https://comment.bilibili.com/" + str(cid) + ".xml" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36' } request = requests.get(url=url, headers=headers) request.encoding = 'utf-8' # 提取弹幕 soup = BeautifulSoup(request.text, 'lxml') results = soup.find_all('d') # 数据处理 data = [data.text for data in results] # 正则去掉多余的空格和换行 for i in data: i = re.sub('\s+', '', i) # 查看数量 print("弹幕数量为:{}".format(len(data))) # 输出到文件 df = pd.DataFrame(data) df.to_csv(file_name, index=False, header=None, encoding="utf_8_sig") print("写入文件成功") |
代码说明:
B站目前还没有针对爬虫设置特别的反爬措施,因此可以直接爬取。
弹幕数据绝大部分都是中文,一定要使用 utf-8 编码。
xml 文件中弹幕数据都在 d 标签内,使用 BeautifulSoup 来提取所有的 d 标签,再获取标签内的数据。
弹幕数据可能会有多余的空格和换行,使用正则表达式进行处理。
使用 Dataframe 将数据输出到 csv 文件中。参数 index=False 不将索引序列保存到文本、header=None 不保存列名。
爬虫写入文件的结果如下图:

B站弹幕数量
这里不得不提一下 B 站的弹幕数量规则:
B站的弹幕池是有上限的,弹幕的具体数量和视频的长度有所联系。一般来讲,一部十分钟内的视频弹幕数量上限为 1000,一部25分钟的视频为 3000,40分钟左右的为 6000,时间更长的话会破万。
如果大家发的弹幕数量太多了,超过弹幕池的数量上限怎么办?
B 站的做法是按照时间顺序用将以前的弹幕剔除掉,然后放入新的弹幕,这样就将该视频的弹幕数量始终维持在一个等级上,而且用户看到的还是最新的弹幕。
比如这里,“刺客伍六七”第一集的时长是16分半,弹幕数量 3000。
新技术介绍
今年,也就是 2020 年,B站某位大佬在 github 上分享了自己的开源项目,也就是 bilibili 的 API 调用库。
GitHub 地址为:https://github.com/Passkou/bilibili_api
通过这个 API 调用模块,可以实现获取视频的评论、弹幕、播放量等信息,还可以实现投币、点赞、发送弹幕等一系列的用户功能。
比起我们上面所介绍的方式,用这个 API 来获取视频的弹幕就更为简单了。我们只需要传入视频的 BVid,调用弹幕 API 即可获取该视频的弹幕。(Bvid 的获取和 cid 同理)。
在使用这个 API 之前,我们需要先用 pip 把这个库安装上。
| pip install bilibili_api |
可以看到,调用 API 简直不要太方便。而且 API 还有人维护和更新,拿来即可用。
from bilibili_api import video import re import pandas as pd # BVid、fileName BVid = "BV1oW41157Na" file_name = '刺客伍六七第一集.csv' # 获取弹幕 my_video = video.VideoInfo(bvid=BVid) danmu = my_video.get_danmaku() # 数据处理 data = [data.text for data in danmu] for i in data: i = re.sub('\s+', '', i) # 查看数量 print("弹幕数量为:{}".format(len(data))) # 输出到文件 df = pd.DataFrame(data) df.to_csv(file_name, index=False, header=None, encoding="utf_8_sig") print("写入文件成功") |
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












