

"测试爆炸"造成的一个显著后果就是回归测试的执行速度越来越慢,从而延长测试反馈周期,降低软件开发和测试效率,最终拖累软件交付进度。
加快测试速度,提升测试效率,是软件测试持续优化的主要内容之一。在实际工作中,我们可以采取许多技术手段实现这一目标,包括但不限于:删除冗余用例,Mock等待函数,选择性测试,动态优先级测试,并行测试等。
其中,并行测试是一种效果较好的手段。所谓并行测试,就是将测试集分割为多个子集,并且让所有子集同时执行的做法。这里,根据分割粒度不同,并行测试形态各异。我们既可以按照测试套件(suite)来分割,也可以按照测试用例(case)来分割。
不管使用哪种分割粒度,核心的分割算法是一致的。分割算法共同目标是最小化测试执行时间。基于这个目标,分割算法需要将测试集分割得尽可能均匀。这里,"均匀"的含义是测试子集各自执行时间相等。
显然,给每个子集分配相同数量suite或case的做法不一定是最优的,因为不同suite或case的执行时间极有可能有差别。那么,有没有更好的做法呢?
从本质上说,并行测试中的测试集分割问题与数学上的分区(Partition)问题是等价的。分区问题研究如何将一组数字划分为多个总和相等的分组。分区问题已经从理论上被证明是NP-hard问题。通俗说,对于这类问题,我们难以(在较短时间内)采用精确算法计算最优解,而只能退而求其次用近似算法计算次优解。
针对分区问题,一种简单有效的近似算法是贪心算法。它的策略十分简单,将待分割的数组从高往低排序,依次将数组中的每个元素分配到当前总和最小的分组中。如果遇到总和相同的多个分组,就随机分配给其中任意一个。
例如,待分配数组是[4, 7, 6, 5, 8],需要分成2个小组。将其从高往低排序,得到[8, 7, 6, 5, 4]。首先分配8,此时两个小组为空(总和都为0),因此将8随机分配,例如给小组1;然后分配7,由于小组2的元素总和0小于小组1的元素总和8,因此将7分配给小组2;接着,采用同样方式依次分配6,5,4。最终分配结果为:小组1为[8, 5],总和13;小组2为[7,6,4],总和17。
贪心算法的Python实现为:
def greedy_partition(data, num_groups): groups = [[] for i in xrange(num_groups)] for n in sorted(data, reverse=True): groups.sort(key=lambda x: sum(x)) groups[0].append(n) return [sum(g) for g in groups] |
回到刚才的例子,贪心算法的结果并不是最优的。例如,将数组[8, 7, 6, 5, 4]分割为两组[8, 6]和[7, 5, 4],各自和是14和16;分割为[8, 7]和[6, 5, 4],各自和是15和15(最优解)。如果数组[8, 7, 6, 5, 4]分别表示5个测试用例的执行时间(单位秒),那么采用贪心算法,并行测试时间为17秒,高于理论最小值15秒。
针对分区问题,除了贪心算法,常见的算法还有KK算法和动态规划算法。对于数组[8, 7, 6, 5, 4]的二分问题,KK算法的分组结果为[8, 6]和[7, 5, 4],动态规划算法的分组结果为[8, 7]和[6, 5, 4]。在这个示例中,其效果都是优于贪心算法的。KK算法和动态规划算法比较复杂,这里就不展开描述了,它们的Python实现为: https://github.com/slxiao/python-advanced/blob/
master/python-partition/partition.py。
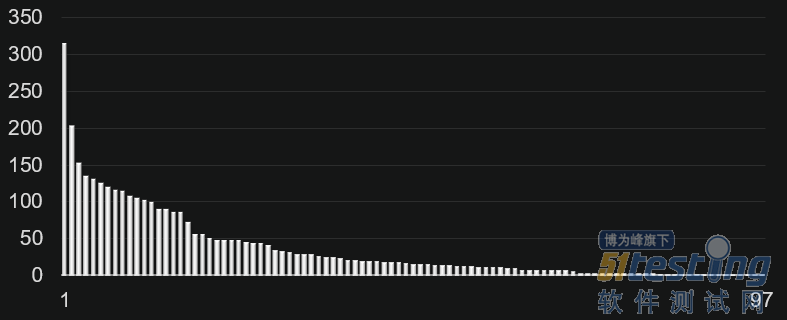
那么,在实际项目中,贪心算法,KK算法和动态规划算法的效果又如何呢?以我经历的一个自动化测试项目为例。这个项目一共有97个suite,总执行时间是3494秒。97个suite的执行时间符合长尾分布,如下图所示。这里,纵轴为执行时间,单位为秒。
三种算法的对比结果如下:
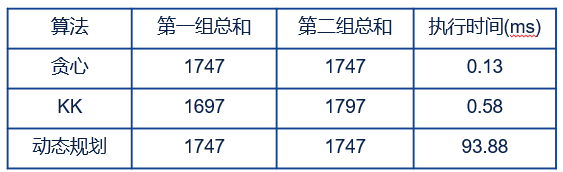
从结果可以看出,贪心算法不仅实际效果好,而且执行速度快。动态规划算法虽然效果也好(实际上,动态规划算法是一种理论上的最优算法),但是它的执行时间很慢,是贪心算法的722倍。KK算法执行速度快,与贪心算法相差不大,但是在我们的项目中,它的效果一般,不如贪心算法。
根据实验结果,在这个自动化测试项目的并行化中,我们最终选择了贪心算法来分割测试集。当然,测试集分割不是并行测试的全部。在算法落地的过程中,还有一些技术问题需要考虑。
一,测试集分割之后,测试suite/case的执行顺序相比分割前,会发生变化。许多时候,测试suite/case之间存在隐性依赖(显性依赖的测试步骤应该被组合在一起,够成一个完整的case或suite)。一旦执行顺序发生改变,可能产生各种莫名其妙的失败。因此,作为前提条件,我们需要先把测试之间的隐性依赖去掉。根据经验,这个过程可能需要花费相当的时间。
二,分割算法依赖于测试suite/case执行时间这一先验知识。这就需要我们采集和存储测试suite/case的历史执行时间。另外,如果某些suite/case的执行时间出现大幅波动,还需要我们调查背后原因,有必要的时候还需要开发预测算法来估计它们的近似执行时间。
三,分割算法需要处理增加和删除suite/case的情况。如果有新的执行时间未知的suite/case加入进来,如何对它们进行分组?当有suite/case被删除时,如何及时调整分组算法?这些问题在实现分组算法时都需要考虑到。
需要说明的是,本文的测试集分割算法既适用于基于共享环境的并行测试,也适用于基于独立环境的并行测试。在基于独立环境的并行测试中,测试子集各自运行于不同的测试环境;在基于共享环境的并行测试中,测试子集运行在同一测试环境。
在实际项目中,如果条件允许,应该尽量采用基于共享环境的并行测试。这种情况下,不仅测试是并发的,而且被测软件的执行也是并发的。这种并行测试,不仅能够节省测试时间,而且能够更好测试被测软件的并发性能。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理












