

1、起因
作为一个关注什么值得买已久的人,作为一个微博都关注了好几个白菜君的人,在各大电商网站上薅羊毛那是再平常不过了。作为一个从来没看过商品的买家,商品评论里的买家秀自然是重点关注。
然而有的商品,只钟意其中一种颜色,或者款式,也许这个款式很特别,买的人很少,即使在评论区选择“带图”评价,可能好几页才有一个买家秀,这无疑是非常耗时又耗力的。
而且,商家有时候为了评价数量更多、更好看,新款的商品会和老款商品放在一起卖,选择款式的时候区分开,但是评价里却还有很多老款的,新款的寥寥无几,不禁想到:如果能一次性只看一种款式的买家秀就好了。
作为一个Python爬虫的实践者,就琢磨着能不能写个自动化工具,告诉程序商品的url地址,然后在本地就会有所有的买家秀图片,并且是按款式区分的,于是,说干就干,总共用时一天,反正坑挺多的。。
2、步骤
首先,访问这些评论,是不需要登录的,所以最开始我搞了挺久的cookies,后来发现根本不需要。。
selenium作为一个强大的自动化工具,几乎可以完全模拟浏览器的所有行为,抓取买家秀自然不在话下,如果你对selenium还不太了解,请看这篇文章:https://www.jianshu.com/p/c8ed978dd0ab
先抓淘宝吧,进入商品页面后,先要跳转到评论部分,点击“累计评论”这个按钮就好了。注意了,先得把窗口最大化哦,
driver.maximize_window()
用xpath语法来选择这个按钮吧,如何快速知道这个元素的xpath路径呢,推荐chrome浏览器安装xpath helper这个插件,打开插件,按住shift,把鼠标移动到元素上,框里自动出来xpath路径了。
driver.find_element_by_xpath(".//*/a[@id='J_ReviewTabTrigger']").click() # 累计评论
driver.find_element_by_xpath(".//*/label/input[@id='reviews-t-val3']").send_keys(Keys.SPACE) # 有图
接下来是得到所有图片,这个比较简单,因为所有买家秀图片都是在li这个标签里面,而且这个li标签的class='photo-item',所以xpath语法这样写就好了,最后会得到一个关于img_ele_list的列表:
img_ele_list = driver.find_elements_by_xpath(".//*/li[@class='photo-item']/img")
得到img_ele,调用img_ele_list[i].get_attribute('src'),即可得到图片的url,但是注意,这个时候图片只有40x40!因为这是小图,那大图怎么办,点开一个买家秀,查看大图,发现它们的url有个规律:
40x40:
400x400:
url那里除了40x40、400x400,其他完全一样,那其他图片是不是这样的呢?经过实践发现,把这里改成500x500,一样可以显示图片,图片大一号而已。通过总结得到,一般人都是用手机拍的照片,一般像素值肯定会大于400x400,于是这里直接替换成400x400即可,阿里已经存储了同一张图片的不同格式(虽然我觉得挺浪费空间的)。
url = img_ele_list[i].get_attribute('src').replace('40x40', '400x400')
好,图片下载完了,如果直接下载到本地,文件名肯定是乱七八糟的,这与我们“想要按款式分开买家秀”的初衷不符了,在存储图片的时候,应该知道这个图片是哪个款式,于是,我们需要找到这个图片元素所在的那个评论用户所买的款式。
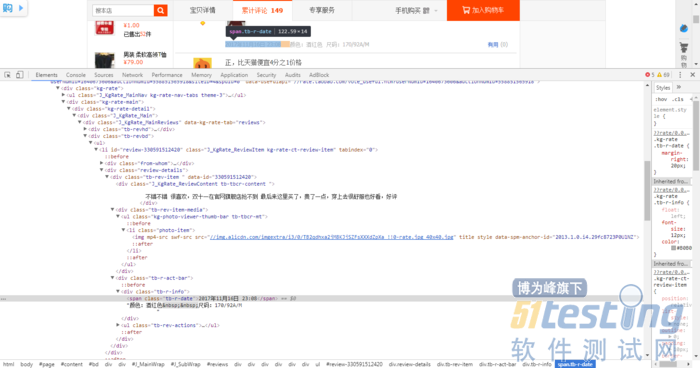
根据xpath语法,我们得到了img_ele,需要往上找3级父节点,再找弟弟,再找class='tb-r-info'的div,
p = img_ele_list[i].find_element_by_xpath("./../../../following-sibling::div[1]/div[@class='tb-r-info']")
但是得到的输出是这样的:
p = '2017年11月27日 10:06颜色分类:红色 参考身高:130cm'
这里用正则表达式,把日期和款式分开:
d = re.findall (r'^20[0-9][0-9].[0-1][0-9].[0-3][0-9].', p.text)[0]
p = re.findall (r'(?<=[0-9][0-9]:[0-9][0-9]).+$', p.text)[0].replace ('/', '-').replace ('\\', '--') # 款式要作为文件名的,所以不要/和\\
从上图可以看到,同时也可以找到买家秀对应的用户评论,这里直接给出xpath语法:
c = img_ele.find_element_by_xpath(".//../../../preceding-sibling::div[1]").text.replace ('/', '-').replace ('\\', '--')
好的,一个完整的图片以及信息找到了,要遍历这一页的所有买家秀,怎么做呢?
前文我们得到了img_ele_list,我们可以对其遍历,对每个img_ele,找到其对应的评论、日期、款式,各自加入到一个新的列表中,最后4个列表长度相等,代码如下:
# 得到把该页的所有买家秀,存入列表中,并且创建另外三个列表,长度一样, # 分别存储每个买家秀的property和对应的用户发表的评论时间及内容 # 我认为带买家秀的评论比较重要,最后在图片文件名中给出 img_ele_list = driver.find_elements_by_xpath(".//*/li[@class='photo-item']/img") property_list = [] datetime_list = [] comment_list = [] p, d, c = '', '', '' for img_ele in img_ele_list: try: p = img_ele.find_element_by_xpath("./../../../following-sibling::div[1]/div[@class='tb-r-info']") # p = '2017年11月27日 10:06颜色分类:红色 参考身高:130cm' d = re.findall (r'^20[0-9][0-9].[0-1][0-9].[0-3][0-9].', p.text) if len(d) > 0: d = d[0] # 得到日期时间 else: d = '' p = re.findall (r'(?<=[0-9][0-9]:[0-9][0-9]).+$', p.text) if len(p) > 0: p = p[0].replace ('/', '-').replace ('\\', '--') # 删掉日期时间,得到款式等信息 else: p = '' c = img_ele.find_element_by_xpath(".//../../../preceding-sibling::div[1]").text.replace ('/', '-').replace ('\\', '--') except Exception as e: print("ERROR happens when getting corresponding property of img :::", e) datetime_list.append (d) property_list.append (p) comment_list.append (c) # 四个列表长度一致,所以可以用同一个指针i来对四个列表同步遍历 for i in range(len(img_ele_list)): url = img_ele_list[i].get_attribute('src').replace('40x40', '400x400') with open (path + '/' + property_list[i] + '-' + datetime_list[i] + '-' + str(time.time()) + '.jpg', 'wb+') as f_img: try: f_img.write (urllib.request.urlopen (url).read ()) except: print("Img url illegal: " + url) else: print ("A new img!!! PROPERTY = %s, DATETIME = %s\n, COMMENT = %s\n, DOWALOADING url = %s" %(property_list[i], datetime_list[i], comment_list[i], url)) |
可以看到,完成了4个列表后,就开始下载这些图片了,图片名字举例如:
颜色:卡其色 尺码:170-92A-M-2017年10月04日-1515648926.131808.jpg
翻页
翻页从来都是一个重难点,但是掌握规律,是有迹可循的。看截图,评论有两页,第一页是这样的:

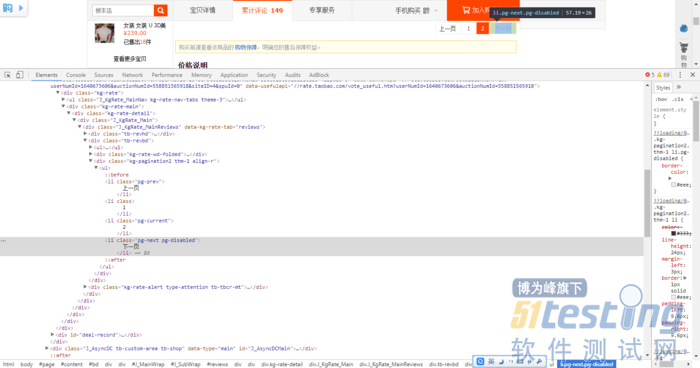
这里给出我的办法:找到pg-current的li,查它的弟弟元素,得到其文本值,如果是数字,则还没有到最后一页,如果不是数字,则到最后一页(即“下一页”),于是在这里用try...except捕捉一下,再所有代码之上套一个while循环,于是,代码如下:
while True:
# 得到把该页的所有买家秀,存入列表中,并且创建另外三个列表,长度一样, # 分别存储每个买家秀的property和对应的用户发表的评论时间及内容 # 我认为带买家秀的评论比较重要,最后在图片文件名中给出 img_ele_list = driver.find_elements_by_xpath(".//*/li[@class='photo-item']/img") property_list = [] datetime_list = [] comment_list = [] p, d, c = '', '', '' for img_ele in img_ele_list: try: p = img_ele.find_element_by_xpath("./../../../following-sibling::div[1]/div[@class='tb-r-info']") # p = '2017年11月27日 10:06颜色分类:红色 参考身高:130cm' d = re.findall (r'^20[0-9][0-9].[0-1][0-9].[0-3][0-9].', p.text) if len(d) > 0: d = d[0] # 得到日期时间 else: d = '' p = re.findall (r'(?<=[0-9][0-9]:[0-9][0-9]).+$', p.text) if len(p) > 0: p = p[0].replace ('/', '-').replace ('\\', '--') # 删掉日期时间,得到款式等信息 else: p = '' c = img_ele.find_element_by_xpath(".//../../../preceding-sibling::div[1]").text.replace ('/', '-').replace ('\\', '--') except Exception as e: print("ERROR happens when getting corresponding property of img :::", e) datetime_list.append (d) property_list.append (p) comment_list.append (c) # 四个列表长度一致,所以可以用同一个指针i来对四个列表同步遍历 for i in range(len(img_ele_list)): url = img_ele_list[i].get_attribute('src').replace('40x40', '400x400') with open (path + '/' + property_list[i] + '-' + datetime_list[i] + '-' + str(time.time()) + '.jpg', 'wb+') as f_img: try: f_img.write (urllib.request.urlopen (url).read ()) except: print("Img url illegal: " + url) else: print ("A new img!!! PROPERTY = %s, DATETIME = %s\n, COMMENT = %s\n, DOWALOADING url = %s" %(property_list[i], datetime_list[i], comment_list[i], url)) # ---------------翻页--------------- driver.execute_script ("window.scrollBy(0,-100)") time.sleep(1) try: next = driver.find_element_by_xpath(".//*/ul/li[@class='pg-current']/./following-sibling::li[1]") # 淘宝的评论页码工具条,每个都是li标签 if next.text.isdigit(): ActionChains(driver).click(next).perform() time.sleep(1) else: exit() except: print('only one page with img') exit() |
3、结果
在项目文件夹下,运行items.py,提示输入url,复制你在浏览器地址栏中的url,粘贴到命令行上(我用的是Pycharm IDE,最后要加个空格,防止IDE自动打开url),按下回车即可,这里找个图片比较多的商品吧。
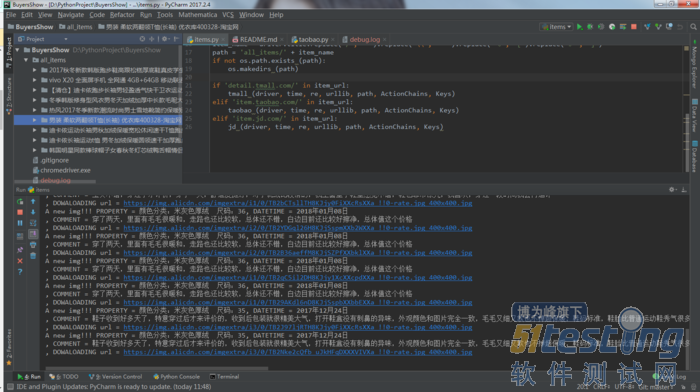
单个输出是这样的:
A new img!!! PROPERTY = 颜色分类:米灰色厚绒 尺码:38, DATETIME = 2017年12月27日
, COMMENT = 包装特别好,大盒子套小盒子,高大上,鞋特别暖和,毛毛特别多特别软,鞋底也厚,走路软软的,哈哈非常喜欢,都说好看,尺码也特准,超级喜欢
, DOWALOADING url = https://img.alicdn.com/imgextra/i2/0/TB2wrG1klTH8KJjy0FiXXcRsXXa_!!0-rate.jpg_400x400.jpg
因为一个买家可能有多个买家秀图片,还记得上文说的4个列表长度一致吗?好几个图片对应的款式、日期、评论,都是一样的,所以看起来命令行中会有重复的,但是url绝对是不一样的(即都是不同的买家秀,除非买家发表评论的时候手抖发了两张一样的)
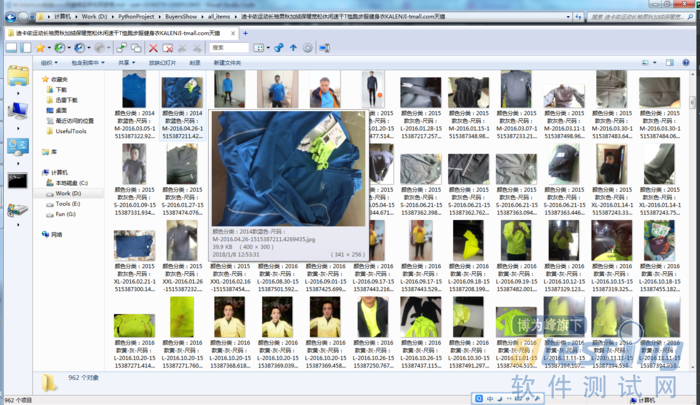
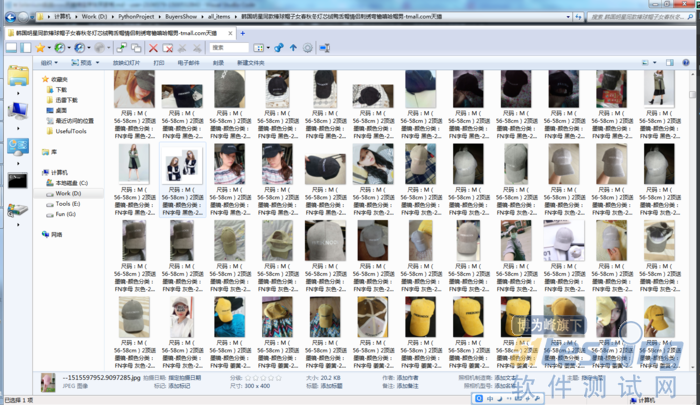
在本地文件夹中可以轻松查看:
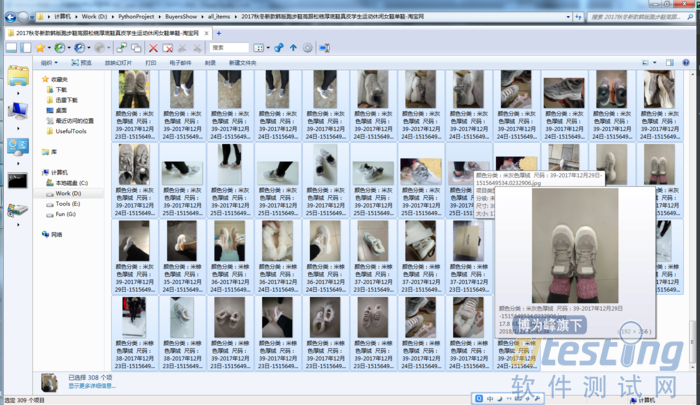
因为图片文件名开头是按款式区分的,所以文件夹中“按名称排序”即可把同款商品放在一起浏览,简单方便。
4、其他电商
天猫
注意天猫和淘宝是两套不同的网页模版,所以还得重新设计xpath语法,主要有这几点需要更改的:
· 各种xpath
· 翻页操作(详情参考github上源码的注释)
京东
京东的带图评价其实挺方便的,但是还是不能按款式浏览。
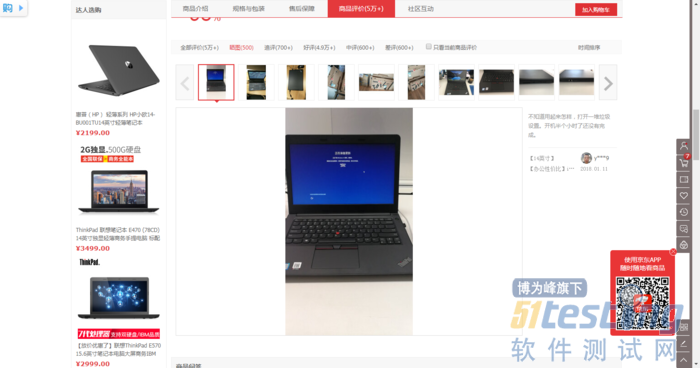
对于jd而言,得到图片后,查询对应评价、日期、款式其实挺简单的,因为像上图一样,一个页面只有一个评论、日期、款式,很好处理,具体看源码即可。
翻页操作,也是直接点下一个,就不详细叙述了。
5、后记
小工具真的特别特别实用,才写了每两天,就用了好几次了(虽然都是些白菜),但是真的特别方便,买家秀才是反映商品的有效途径。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












