

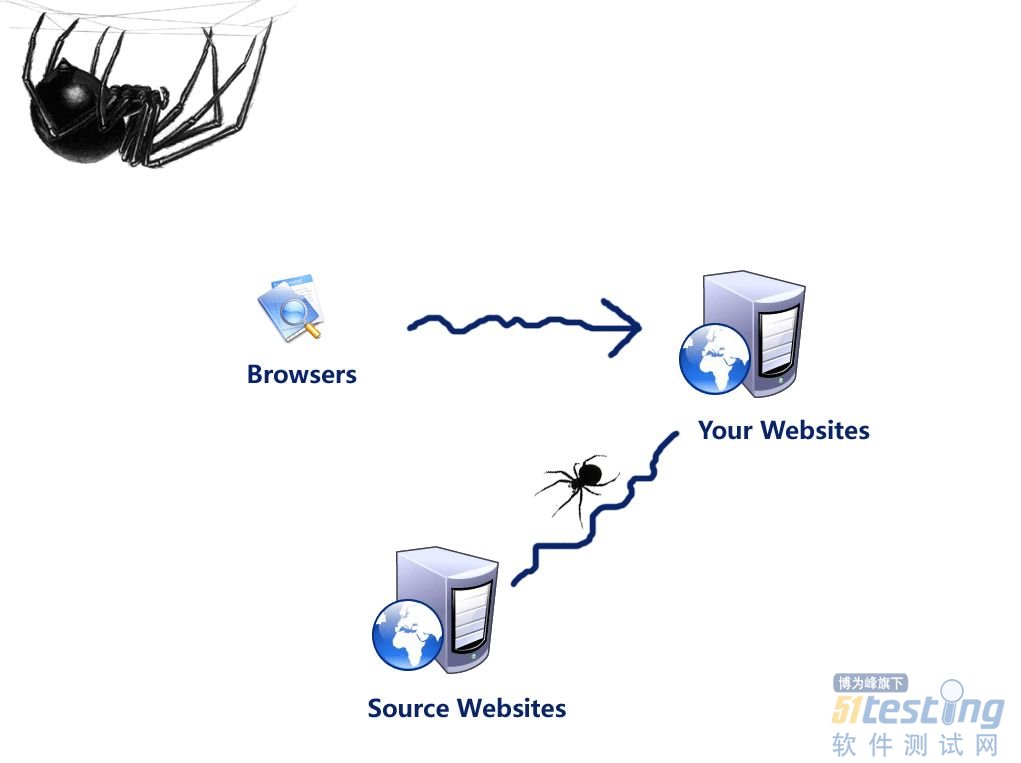
网络爬虫是搜索引擎抓取系统的重要组成部分,爬虫的主要目的是将互联网上网页下载到本地,形成一个或联网内容的镜像备份。
网络爬虫的基本工作流程如下:
1.首先选取一部分种子URL
2.将这些URL放入待抓取URL队列
3.从待抓取URL队列中取出待抓取的URL,解析DNS,得到主机的IP,并将URL对应的网页下载下来,存储到已下载网页库中,此外,将这些URL放入已抓取URL队列。
4.分析已抓取到的网页内容中的其他URL,并将URL放入待抓取URL队列,从而进入下一个循环。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












