

接下来我会跟大家分享一下58大数据平台在最近一年半的时间内技术演进的过程。主要内容分为三方面:58大数据平台目前的整体架构是怎么样的;最近一年半的时间内我们面临的问题、挑战以及技术演进过程;以及未来的规划。
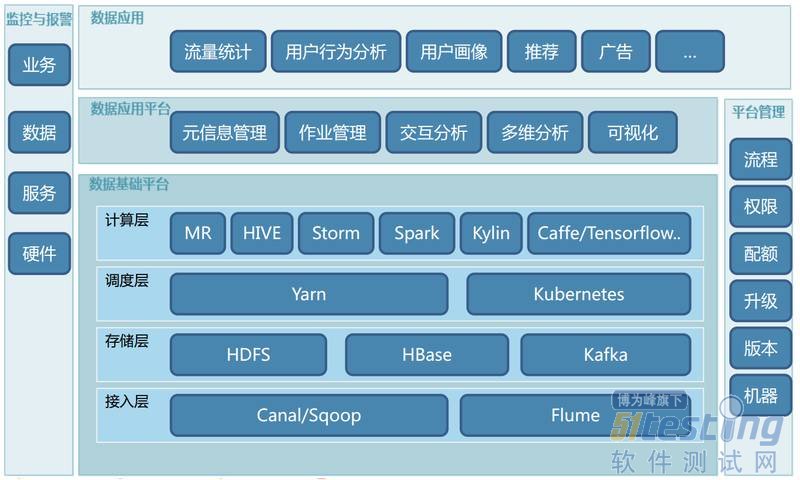
首先看一下58大数据平台架构。大的方面来说分为三层:数据基础平台层、数据应用平台层、数据应用层,还有两列监控与报警和平台管理。
数据基础平台层又分为四个子层:
1.接入层,包括了Canal/Sqoop(主要解决数据库数据接入问题)、还有大量的数据采用Flume解决方案;
2.存储层,典型的系统HDFS(文件存储)、HBase(KV存储)、Kafka(消息缓存);
3.再往上就是调度层,这个层次上我们采用了Yarn的统一调度以及Kubernetes的基于容器的管理和调度的技术;
4.再往上是计算层,包含了典型的所有计算模型的计算引擎,包含了MR、HIVE、Storm、Spark、Kylin以及深度学习平台比如Caffe、Tensorflow等等。
数据应用平台主要包括以下功能:
1.元信息管理,还有针对所有计算引擎、计算引擎job的作业管理,之后就是交互分析、多维分析以及数据可视化的功能。
2.再往上是支撑58集团的数据业务,比如说流量统计、用户行为分析、用户画像、搜索、广告等等。
3.针对业务、数据、服务、硬件要有完备的检测与报警体系。
4.平台管理方面,需要对流程、权限、配额、升级、版本、机器要有很全面的管理平台。
这个就是目前58大数据平台的整体架构图。

这个图展示的是架构图中所包含的系统数据流动的情况。分为两个部分:
首先是实时流,就是黄色箭头标识的这个路径。数据实时采集过来之后首先会进入到Kafka平台,先做缓存。实时计算引擎比如Spark streaming或storm会实时的从Kafka中取出它们想要计算的数据。经过实时的处理之后结果可能会写回到Kafka或者是形成最终的数据存到MySQL或者HBase,提供给业务系统,这是一个实时路径。
对于离线路径,通过接入层的采集和收集,数据最后会落到HDFS上,然后经过Spark、MR批量计算引擎处理甚至是机器学习引擎的处理。其中大部分的数据要进去数据仓库中,在数据仓库这部分是要经过数据抽取、清洗、过滤、映射、合并汇总,最后聚合建模等等几部分的处理,形成数据仓库的数据。然后通过HIVE、Kylin、SparkSQL这种接口将数据提供给各个业务系统或者我们内部的数据产品,有一部分还会流向MySQL。以上是数据在大数据平台上的流动情况。
在数据流之外还有一套管理平台。包括元信息管理(云窗)、作业管理平台(58dp)、权限审批和流程自动化管理平台(NightFury)。

我们的规模可能不算大,跟BAT比起来有些小,但是也过了一千台,目前有1200台的机器。我们的数据规模目前有27PB,每天增量有50TB。作业规模每天大概有80000个job,核心job(产生公司核心指标的job)有20000个,每天80000个job要处理数据量是2.5PB。
技术平台技术演进与实现
接下来我会重点介绍一下在最近一年半时间内我们大数据平台的技术演进过程,共分四个部分:稳定性、平台治理、性能以及异构计算。第一个部分关于稳定性的改进,稳定性是最基础的工作,我们做了比较多的工作。第二个部分是在平台治理方面的内容。第三个方面我们针对性能也做了一些优化。第四个方面,我们针对异构环境,比如说机器的异构、作业的异构,在这种环境下怎么合理地使用资源。
稳定性改进
首先看一下稳定性的改进。这块我会举一些例子进行说明。稳定性包含了几个方面,其中第一个方面就是系统的可用性,大家可以采用社区提供的HDFS HA、Yarn HA,Storm HA来解决。另外一个方面是关于扩展性,例如Flume、HDFS,Yarn,Storm的扩展性。这里主要介绍下Flume和HDFS的扩展性相关的一些考虑。此外,有了可用性和扩展性,系统就稳定了吗?实际上不是这样。因为还有很多的突发问题。即使解决了可用性和扩展性,但突发问题还是可能会造成系统不可用,例如由于一些问题造成两台NameNode全部宕机。
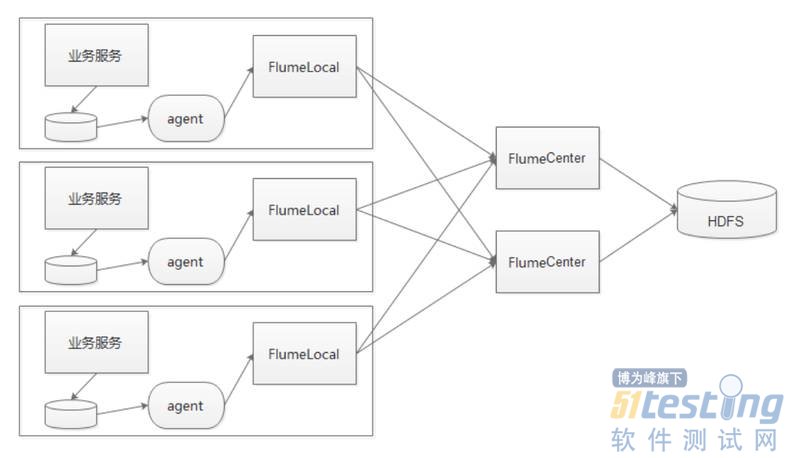
首先看一下Flume的扩展性。我们人为的把它定义了两层。一个是FlumeLocal(主要解决一台机器的日志采集问题,简称Local),一个是FlumeCenter(主要从Local上收集数据,然后把数据写到HDFS上,简称Center),Local和Center之间是有一个HA的考虑的,就是Local需要在配置文件里指定两个Center去写入,一旦一个Center出现问题,数据可以马上从另一个Center流向HDFS。此外,我们还开发了一个高可靠的Agent。业务系统中会把数据产生日志写到磁盘上,Agent保证数据从磁盘上实时可靠的收集给本地的Local,其中我们采用了检查点的技术来解决数据可靠性的问题。
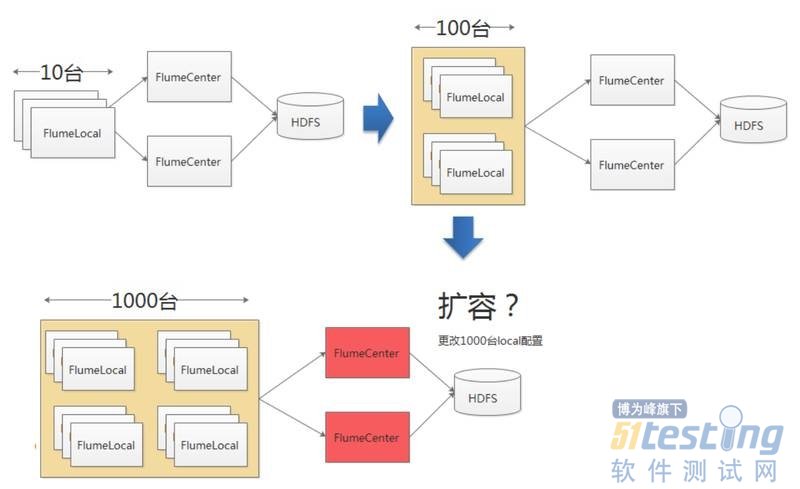
这是Flume的典型架构。Local需要在配置文件里面指定死要连到哪几个Center上。如果说10台,可能还OK,100台也OK,如果一千台呢?如果发现两台Flume Center已经达到机器资源的上限,如何做紧急的扩容呢?所以从这个角度看Flume的扩展性是有问题的。
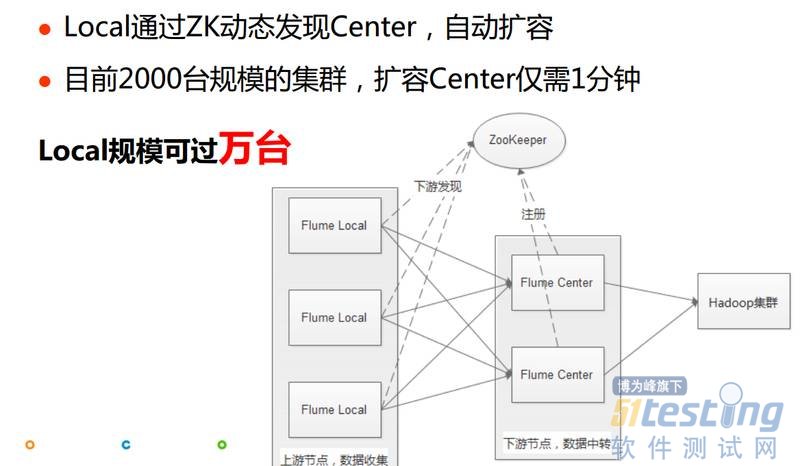
我们的解决方法是在Local和Center中间加了一个ZooKeeper,Local通过ZK动态发现Center,动态的发现下游有什么,就可以达到Center自动扩容的目标了。我们公司Local有两千多台,扩容一台Center仅需一分钟,这种架构实际上可以支持达到万台规模的,这是Flume扩展性的一些改进。
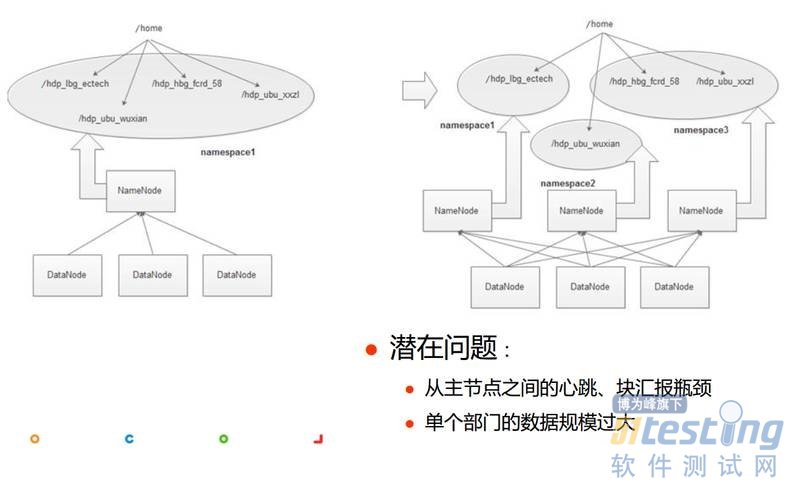
接下来看一下HDFS扩展性的问题。上面这张图展示了hdfs federation的架构,左侧是一个单namespace架构,即整个目录树在一个namespace中,整个集群的文件数规模受限制于单机内存的限制。federation的思想是把目录树拆分,形成不同的namespace,不同namespace由不同namenode管理,这样就打破了单机资源限制,从而达到了可扩展的目标,如右侧图。
但这个方案有一些隐藏的问题,不知道大家有没有注意到,比如这里每个Datanode都会与所有的NameNode去心跳,如果DataNode数量上万台,那么就可能会出现两个问题:第一,从主节点之间的心跳、块汇报成为瓶颈,第二,如果单个部门的数据规模过大那该怎么办?
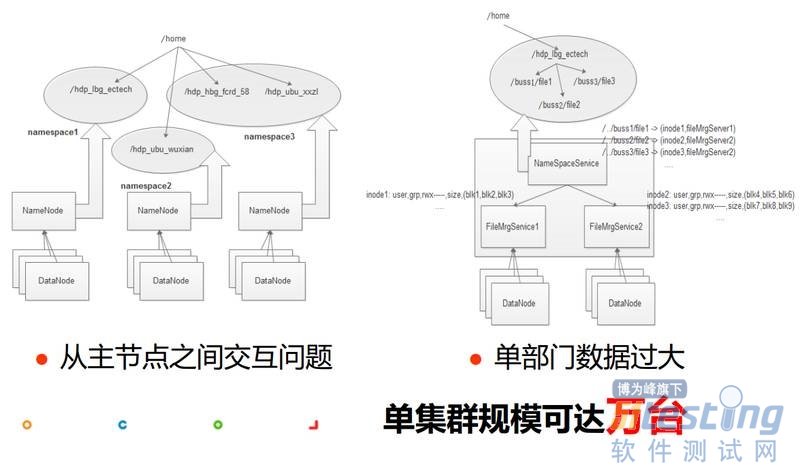
针对从主节点之间交互的问题,我们可以进行拆分,控制一个NameNode管理的DateNode的数量,这样就可以避免主从节点交互开销过大的问题。针对单部门数据过大的话可以针对部门内数据进行进一步细拆,就OK了。或者可以考虑百度之前提供的一个方案,即把目录树和inode信息进行抽象,然后分层管理和存储。当然我们目前采用社区federation的方案。如果好好规划的话,也是可以到万台了。
不知道大家有没有在自己运营集群过程中遇到过一些问题,你们是怎么解决的,有些问题可能相当的棘手。突发问题是非常紧急而且重要的,需要在短时间内搞定。接下来我会分享三个例子。
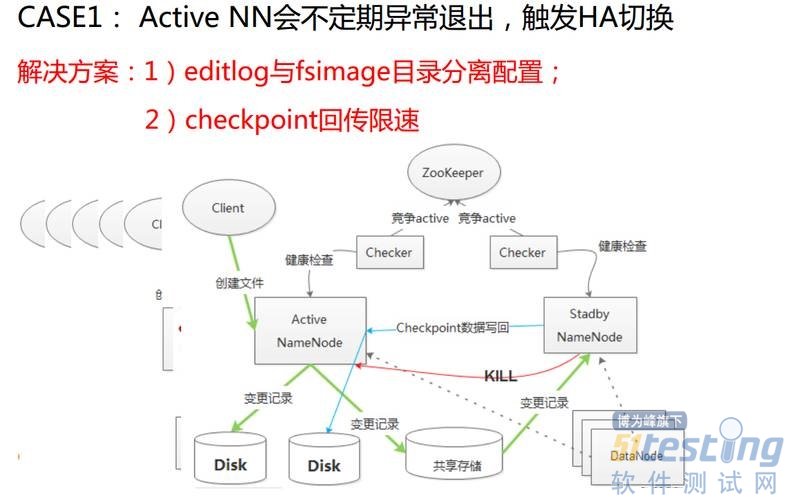
第一个例子是HDFS的Active NN会不定期异常退出,触发HA切换,这就好像一个不定时炸弹一样。这个图展示了HDFS的HA的架构图,客户端进行变更操作(如创建文件)的话会发出请求给namenode,namenode请求处理完之后会进行持久化工作,会在本地磁盘存一份,同时会在共享存储存一份,共享存储是为了active和standby之间同步状态的,standby会周期从共享存储中拉取更新的数据应用到自己的内存和目录树当中,所有的DataNode都是双汇报的,这样两个namenode都会有最新的块信息。最上面的是两个Checker,是为了仲裁究竟谁是Active的。
还有一个过程,Standby NameNode会定期做checkpoint工作,然后在checkpoint做完之后会回传最新的fsimage给active,最终保存在active的磁盘中,默认情况下在回传过程会造成大量的网络和磁盘的压力,导致active的本地磁盘的Util达到100%,此时用户变更请求延迟就会变高。如果磁盘的Util100%持续时间很长就会导致用户请求超时,甚至Checher的检测请求也因排队过长而超时,最终然后触发Checker仲裁HA切换。
切换的过程中在设计上有很重要一点考虑,不能同时有两个Active,所以要成为新Active NameNode,要把原来的Active NameNode停止掉。先会很友好地停止,什么是友好呢?就是发一个RPC,如果成功了就是友好的,如果失败了,就会ssh过去,把原来active namenode进程kill掉,这就是Active NameNode异常退的原因。
当这个原因了解了之后,其实要解决这个问题也非常简单。
第一点要把editlog与fsimage保存的本地目录分离配置,这种分离是磁盘上的分离,物理分离。
第二是checkpoint之后fsimage回传限速。把editlog与fsimage两个磁盘分离,fsimage回传的io压力不会对客户端请求造成影响,另外,回传限速后,也能限制io压力。这是比较棘手的问题。原因看起来很简单,但是从现象找到原因,这个过程并没有那么容易。

第二个案例也是一样,Active NN又出现异常退出,产生HA切换。这次和网络连接数有关,这张图是Active NameNode的所在机器的网络连接数,平时都挺正常,20000到30000之间,忽然有一个点一下打到60000多,然后就打平了,最后降下来,降下来的原因很明显,是服务进程退了。
为什么会出现这个情况呢?在后续分析的过程中我们发现了一个线索,在NameNode日志里报了一个空指针的异常。就顺藤摸瓜发现了一个JDK1.7的BUG,参见上面图片所示,在java select库函数调度路径过程中最终会调用这个函数(setUpdateEvents),大家可以看到,如果fd的个数超过了MAX_UPDATE_ARRAY_SIZE(65535)这个数的话,将会走到else路径,这个路径在if进行不等表达式判断时,将会出发空指针异常。
接下来的问题是,为什么会产生这么多的链接呢?经过分析我们发现,在问题出现的时候,存在一次大目录的DU操作,而DU会锁住整个namespace,这样就导致后续的写请求被阻塞,最终导致请求的堆积,请求的堆积导致了连接数大量堆积,连接数堆积到一定程度就触发JDK1.7的这个BUG。这个问题的解决,从两个方面看,首先我们先把JDK升级到1.8。其次,调整参数dfs.content-summary.limit,限制du操作的持锁时间。该参数默认参数是0。我们现在是设成10000了,大家可以参考。这是第二个非常棘手的问题。
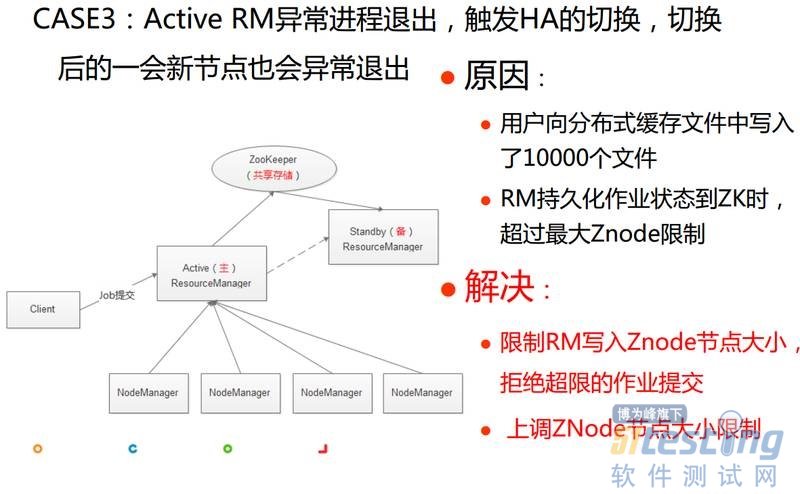
第三个案例关于YARN主节点的,有一天中午,我们收到报警,发现Active RM异常进程退出,触发HA的切换,然而切换后一会新的Active RM节点也会异常退出,这就比较悲剧,我们先进行了恢复。之后我们从当时的日志中发现了原因:一个用户写了一万个文件到分布式缓存里,分布式缓存里数据会同步到ZK上,RM持久化作业状态到ZK时超过Znode单节点最大上限,抛出异常,最终导致ResourceManager进程的异常退出。其实问题的解决方法也非常简单,我们增加了限制逻辑,对于序列化数据量大于Znode节点大小的Job,直接抛异常触发Job的失败。另外我们还适当提升Znode节点大小。
以上是在稳定性方面的一些工作,这三个案例跟大家分享一下,如果有类似的问题建议大家可以尝试一下,这些方案是被我们验证OK的。












