

背景
标题党,其实两个并没有很大的关联,第一个装饰器是用来处理博客上的登录模块,让页面方法以一种简单的方式来实现登录的校验。而测试用例的生成脚本是工作中的一个需求,今天尝试了多种方法,总结了一个最简单的方式。
装饰器
装饰器是Python的一个语法糖,实现起来并不难,只是理解起来有点绕,简单来说,装饰器就是给一个函数加上装饰,比如函数执行前执行一些东西,函数执行完毕后又执行一些东西,当然装饰器是可以实现在函数内部也执行一些东西的,但是不在我们今天讨论的范畴,网络上已经有相应很详细的教程。
回顾一下我们使用unittest测试框架的时候,有一个setUp方法和tearDown方法,这两个方法会在每个测试用例执行前后分别执行一次,达到初始化测试环境和清理测试环境的目的。装饰器的效果就类似这种,比如我们在打开某些需要权限的web页面的时候,就会需要校验身份。之前我们是这么做的:
user = request.session.get('user', '') if user != "xxx": return HttpResponseRedirect('/login/') |
在页面方法之前加入这段代码,就可以校验session中是否有对应的用户名,如果有,则正常加载页面,如果没有,那么就跳转到登录页面。
那么问题来了,如果页面非常多,在每个方法我们都要加上这段代码,万一有什么地方要修改,那么这样写就要修改非常多地方,我们要用一个更好,更优雅的方式来实现它,装饰器就是我们的选择。
def checklogin(func): def checkuser(request): user = request.session.get('user', '') if user != "xxx": return HttpResponseRedirect('/login/') r = func(request) return r return checkuser |
上面就是一个非常简单的装饰器,方法checklogin传入一个函数作为参数,内部先执行校验权限的方法,如果校验不通过就直接重定向到/login/路径下,不执行函数,如果校验通过,则执行传入的函数func。然后我们只要在被修饰的函数上面加上@checklogin即可,这样写起来既简单,又优雅,修改起来还非常的方便。比如下面这样:
@checklogin def index(request): rstdata = { "PageVisited": webstatistical.objects.get(id=1).webstatistical, "ArticleNum": BlogBody.objects.count(), } return render(request, 'index.html', {"rstdata": rstdata}) |
这样我们不用每个函数都加上那个校验的丑陋的方法,只要在函数上方带一个帽子就行了。
装饰器用来写日志也是非常不错的工具。
测试用例生成脚本
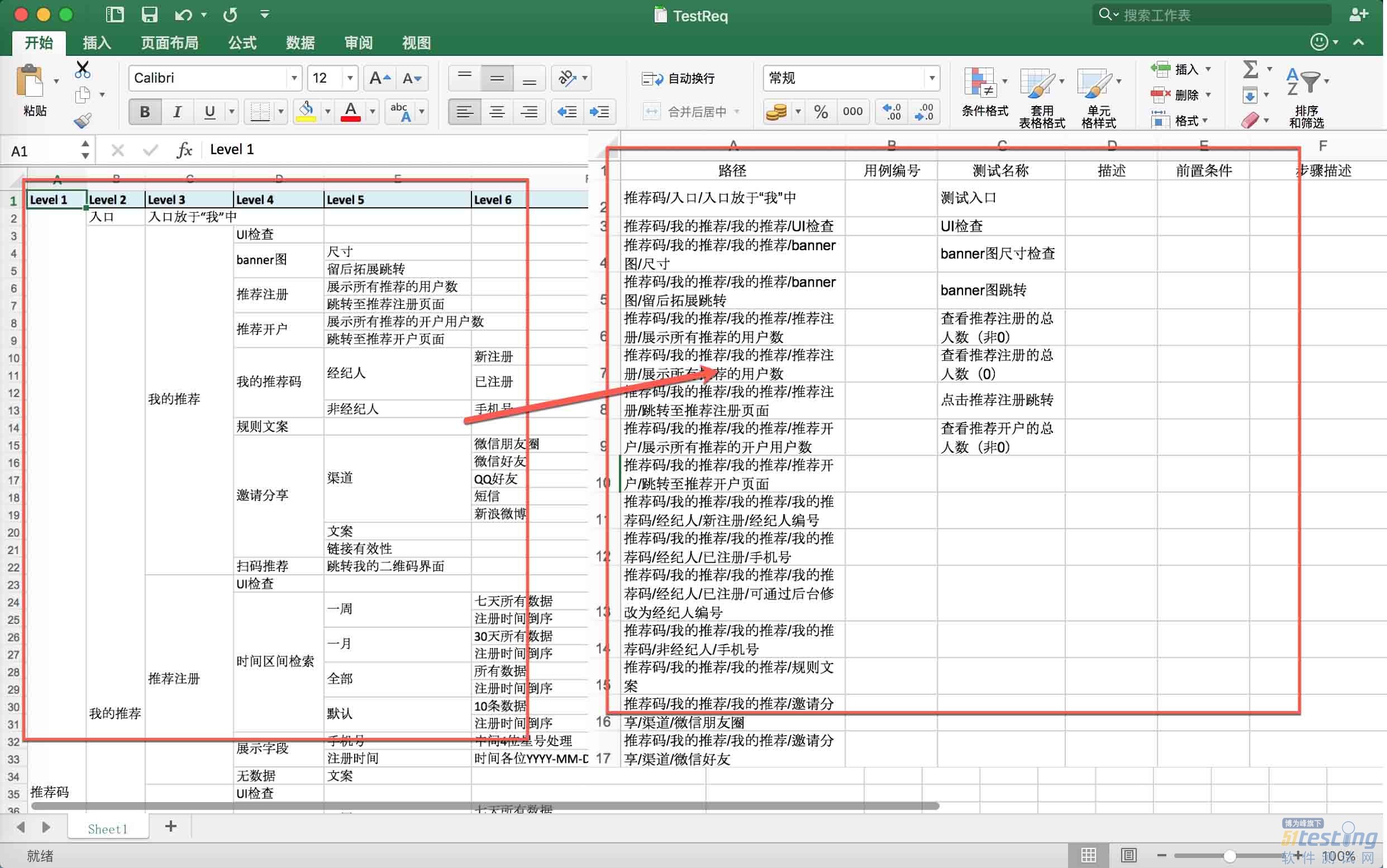
之前在招行的时候,有一个上古流传的vba脚本,可以自动将测试需求自动的拆分为测试需求和测试用例,然后只要写完测试用例就能直接导到测试管理系统中去。最近又在折腾这块东西,Mac貌似不能写vba,我就用Python写一个脚本来处理这个,反正以后可能也会用的到。效果如下图所示:
C4FA3053-D523-477B-9C1E-BD476555C3
先用xmind把测试需求写出来,然后导成Excel格式,就是初始的需求了。
转换起来有两个麻烦的点。
合并单元格只有第一个单元格数据有内容,其他空位数据全部是空
需求层级不同,会有某些行多某些行少,需要做一下对应的去空处理
第一个问题需要补空处理,就是如果读取到数据为空时,需要向上获取数据,而另一个问题需要把多余的空去掉,否则会出现冗余数据,而这两种空要分别处理,如果混在一起会导致数据错乱。
第一个问题我是这么处理的:
def findCell(table, rowindex, colindex): """ 已所在列之前行的内容来填充单元格内容 :param table: sheet对象 :param rowindex: int, 行号 :param colindex: int, 列号 :return: str, 填充之后单元格的内容 """ while 1: cell = getSingleCell(table, rowindex, colindex) if cell == '': rowindex -= 1 else: return cell |
只要变动行号就行了,行号不停的往上走,走到内容不为空时,就返回内容,这是就能正常的补上空白数据了。另一边的空白就是要去掉的。所以要专门对这个列表做处理,前面一半的空白补上,后面的空白要去掉,我使用的是如下的方式:
def getRowCell(table, index): """ 获取整列的数据,单独去除了单行后的空元素,单行前的空元素会自动获取所在列之前行的数据 :param table:sheet对象 :param index:int, 行号 :return:list, 整列的数据 """ row = [] status = 0 for x in range(table.ncols): if getSingleCell(table, index, x) == '' and status == 0: row.append(findCell(table, index, x)) elif getSingleCell(table, index, x) == '' and status == 1: break else: row.append(getSingleCell(table, index, x)) status = 1 return row |
由一个status来控制,为空的时候等于0,当迭代到列表元素不为空时,就替换为1,之后如果再遇到空元素,就扔掉。
把这些数据处理掉之后,就是一个非常完整的我们要的数据了,这时只要一直迭代,获取这些有效数据,放到一个列表,再调用写Excel的方法时候,迭代这个列表,就能写出我们要的东西了,比如这样:
def writeExcel(table): """ 写入Excel :param table: sheet对象 :return: None """ title = [u'路径', u'用例编号', u'测试名称', u'描述', u'前置条件', u'步骤描述', u'预期结果', u'优先级', u'用例类型', u'用例属性', u'设计人', u'设计日期'] f = xlwt.Workbook() sheet1 = f.add_sheet(u'TestCase', cell_overwrite_ok=True) # 书写每行的内容 for i, rows in enumerate(readMain(table)): sheet1.write(i, 0, '/'.join(rows)) sheet1.write(i, 10, u'xxx/xxx') sheet1.write(i, 11, time.strftime('%Y-%m-%d')) # 书写标题行 for x in range(len(title)): sheet1.write(0, x, title[x]) f.save('TestCase.xls') |
一个转换的脚本就写完了,以后每次用Xmind写完需求之后,就能自动跑起来生成测试用例了,把title调整一下就能够调整为自己需要的格式了。
最后
完整的代码我放在github上,有兴趣的可以自行查看。












