

现在对数据质量的要求越来越高,面对一个动辄上亿条数据的报表如何快速对它的数据质量做出分析呢?给大家分享下我们测试时用到的Data Profiling方法。
Data Profiling,可以大概翻译“数据概要分析”,维基百科对Data Profiling的解释如下:Data profiling is the process of examining the data available in an existing data source and collecting statistics and information about that data,我的理解就是通过对数据自身统计值分析来反映出数据质量问题。
日常工作中,我们拿到一个报表都会对每张表做Analyze,一方面是为了让优化器可以选择合适的执行计划,另一方面对于一些查询可以直接使用分析得到的统计信息返回结果,比如COUNT(*)。这个其实就是简单的Data Profiling。 Data Profiling其实是对报表各方面信息的一个收集统计信息的过程,然后根据收集到的信息对报表的数据情况做出判定,找到问题点从而更好保证数据质量。
数据的统计信息除了基本的记录条数、最大值、最小值、最大长度、最小长度、唯一值个数、NULL值个数、平均数和中位数、针对字段的枚举和分布频率外,还包括相关性分析、主键相关分析和血缘分析等,将之分别做了一下分类如下图:
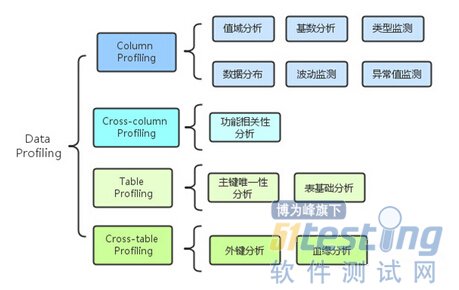
下面对它们分别进行详细介绍:
值域分析:
对于所有字段都适合,分析字段的值是否满足指定阀值、分析字段值的统计量(最大、最小、中位数、均值、方差等)
常见BUG:最大、最小值越界、发现有NULL值;
基数分析:
分析字段中不同值的个数,这种方法更适合于维度类指标
常见BUG: 对于度量类指标数据比较集中,基数下记录个数过大或过小等
类型监测:
分析字段真实值是否符合定义的数据类型 ,一般在数据预览时对数据内容做下评估
数据分布:
分析各个维度值在总体数据中分布情况,根据经验值能从总体上看出数据的质量情况
常见BUG: 数据分布不符合预期;度量类指标数据过分集中,发现有NULL值过多
波动监测:
分析检测值在一定周期内的数值波动是否在指定阀值内,这个更多用在线上数据监控中,可分析检测值在一定周期内的数值波动是否在指定阀值内,如出现大幅波动需要关注。
异常值监测:
分析字段中是否包含异常数据,例如空、NULL,另外一些约定异常值的数据的数量
常见BUG:col存在异常值,约定异常值数据过多,如-99,-1,NULL等
功能相关性分析:
分析字段或字段之间是否满足指定的业务规则,这个需要理解本表内字段间的业务逻辑关系,如pv>=uv
常见BUG:字段间的业务逻辑未满足预期
主键唯一性分析:
分析表数据中主键是否唯一,这个非常重要,如果主键不唯一会给下游表的计算带来无穷的困扰。
常见BUG:主键不唯一;主键为NULL
表基础分析:
分析表的基础统计量如分区、行数、大小,如果有对照表,最好参考对照表,如无对照表这个更多是靠经验值,分析此表的业务对于表的基础统计量是否符合预期进行判断。
常见BUG:表基础统计量不符合预期
外键分析:
分析事实表中的外键是否都能在维表中关联到
常见bug:表里的外键没有在对应维表中找到对应,外键本身为NULL或异常值
血缘分析:
分析表和字段的从数据源到当前表的血缘路径,以及血缘字段之间存在的关系是否满足,关注的数据的一致性以及表设计的合理性。












