

一万亿行
Sybase-Sun数据仓库参考架构
摘要
2004年3月,应Sybase及Sun公司的要求,我对Sybase-Sun数据仓库参考架构的性能进行了检验,测试平台建于美国加州Palo Alto,基于该平台,我对基准测试进行了设计及检测。
这一企业级数据仓库参考架构,基于两台Sun Fire服务器以及 Sybase IQ,经过验证取得了众多意义重大的成就:
◆事实表的总行数达到1万亿行,这是迄今为止经过独立验证的最大的数据库;足以记录20多年来全美可以出售的每一笔铝矿。
◆深度数据存储及压缩比例,155TB的原始数据在存储到该数据仓库的星型模型中,实际只占用55TB的存储空间
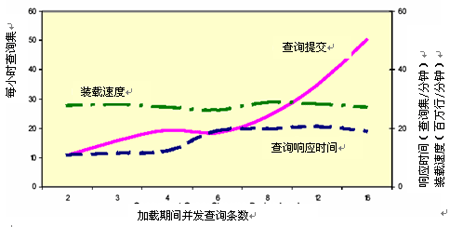
◆在不断增加查询压力至5倍的情况下,同时维持查询响应时间及数据加载速度性能的能力(如下图所示)。
详细报告
数据仓库测试平台包括两台独立的Sun服务器节点与一个共享磁盘架构,通过光纤与Sun磁盘阵列连接,数据库系统为Sybase IQ 12.5.0。
平台配置概览
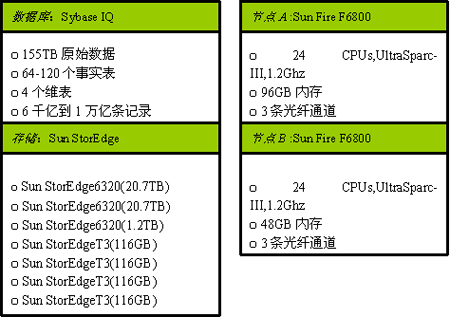
Sybase IQ Server配置
◆一个IQ 写(Writer)服务器,安装于A节点服务器。写服务器绑定了24个CPU中的16个CPU,分配了4GB的主缓冲(Main IQ Cach)和4GB的临时缓冲(Temp IQ Cach)。
◆一个IQ查询服务器,安装于A节点服务器。该查询服务器绑定了剩下的8个CPU中的7个(剩余一个留给操作系统使用),分配了28GB的主缓冲和48GB的临时缓冲。
◆一个IQ查询服务器,安装于B节点服务器。该查询服务器绑定了24个CPU中的7个CPU(其余的CPU基本保持空闲),分配了20GB的主缓冲和20GB的临时缓冲。
增至10亿条记录
建立数据库– Sybase IQ数据库以一个基本星型结构建立,以大量事实表为中心——每个事实表装载一个月的事实数据(每行25列)。建立四个维表用以对事实数据进行钻取。装载于维表的数据可以提供更大范围的表基数(从5千行到5亿行)。下图描述了维表的数据装载情况:
| 维表 | 行数 | 列数 | 行的大小 |
| Customer(客户) | 500,000,000 | 11 | 246 Bytes |
| Product(产品) | 1,000,000 | 8 | 144 Bytes |
| Channel(渠道) | 5,00 | 6 | 106 Bytes |
| Location(地址) | 30,000 | 7 | 108 Bytes |
初始装载– 首先,建立一组事实表共60张。每张表装载1999年到2003年间的一个月的事实数据。数据由1亿条种子记录生成,通过对种子记录的一个或多个相关的域值进行多次修改以保证行的唯一性,然后对记录进行复制。使用Sybase IQ的索引技术,事实表完全被索引化。另外,在主键上建立一个high-group索引,在四个对应于维表的外键上也建立high-group索引。
第一次验证– 接着定义了几张包含12张事实表的联合(UNION ALL)视图,为每年的数据各定义一张。同时,建立了一张包含所有5年的事实数据的视图。这样,确定了数据库的内容,接下来,我们进行了一系列的性能测试(详见后述)。
继续增加– 在第一次验证之后,更多的事实表被建立,同时与第一次验证类似,装载了各年份的事实数据。Sun存储系统的配置相应的增加,为新建立的事实表提供空间。
跨越1万亿行的界限– 总共对44张事实表进行了数据加载。然后定义了一个联合所有104张事实表的全局视图,涵盖了全部8年6个月的事实数据。下表描述了加载到事实表一万亿行中的数据的详细情况:
| 事实表 | 行数 | 列数 | 原始记录大小 | 原始数据大小 |
| ALL_FACTS(所有事实表) | 1万亿 | 25 | 170 Bytes | 154.6 Terabytes |
最终验证– 一万亿行数据加载的验证,以及对基于全局视图的跨表查询的执行,用以验证数据库是否依然运转正常,响应时间是否显著下降(详见后述)。












