

如果没有任何参考模板,需要快速从零创建一个爬虫项目,并且添加测试,需要怎么做呢。首先我们列一下整体计划,将要实现的功能分模块一步步实现。
目标:爬取菜鸟笔记前几页的笔记标题
使用语言和框架:Python+unittest+HTMLTestRunner
要实现的功能:
爬取网页并获取数据
保存爬取结果
记录日志
保存测试报告
一、爬取网页并获取数据
1、请求
方法一和二使用urllib模块的请求方法,方法二添加了代理。方法三是用requests模块的请求方法。
# 方法一
def open_url(url):
try:
req = urllib.request.Request(url)
req.add_header('user-agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/'
'68.0.3440.106 Safari/537.36')
response = urllib.request.urlopen(req)
html = response.read()
return html
except RequestException:
return None
# 方法二
def agent_req(url):
# 添加代理
try:
iplist = agent.get_agent()
proxy_support = urllib.request.ProxyHandler({'http': random.choice(iplist)})
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('user-agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/'
'68.0.3440.106 Safari/537.36')]
urllib.request.install_opener(opener)
response = urllib.request.urlopen(url)
html = response.read()
return html
except RequestException:
return None
# 方法三
def get_req(url):
try:
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/'
'68.0.3440.106 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = "utf-8"
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
2、获取页面HTML
在需要获取页面的地方调用想要的请求方法即可。
def get_html(baseurl):
html = request.get_req(baseurl)
return html
3、获取目标数据
传入html页面、查找范围和偏移量,即可返回想要获取的数据。
def get_data(html, a_field, b_field, num):
datalist = []
a = html.find(a_field)
while a != -1:
b = html.find(b_field, a, a + 255)
if b != -1:
if html[a + num:b] not in datalist:
datalist.append(html[a + num:b])
else:
b = a + num
a = html.find(a_field, b)
return datalist
二、保存爬取结果
考虑到结果数据用excel打开方便,我们选择保存结果到csv文件。
def save_data(datalist, file):
# 保存文件
a = 1
os.chdir(config.get_path('project_path'))
# 判断文件夹是否存在
if os.path.exists('result'):
pass
else:
os.mkdir('result')
# 切换路径
os.chdir(config.get_path('result_path'))
filename = file + str(date.today()) +'.csv'
with open(filename, 'a', newline='', encoding='utf-8') as wf:
writer = csv.writer(wf, delimiter='-')
# 先判断是否存在该文件
with open(filename, 'r', encoding='utf-8') as rf:
reader = csv.reader(rf)
# 判断是否有表头
if ['id-notename'] not in reader:
writer.writerow(['id', 'notename'])
# 判断已有行数
for line in reader:
a += 1
for i in datalist:
writer.writerow([a, i])
a += 1

result
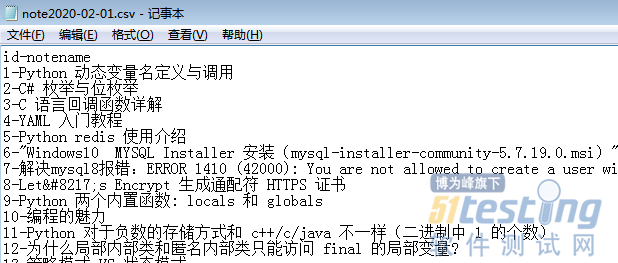
结果
运行完即可在result目录下保存当天数据。
三、记录日志
class LogOutput:
def log_output(self, name_project):
now = time.strftime("%Y_%m_%d_%H_%M_%S")
logging.basicConfig(level=logging.DEBUG,
filename=config.get_path('log_path') + '\\' + now + '- ' + name_project + '.log',
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
filemode='w',
datefmt='%Y-%m-%d %A %H:%M:%S')
logger = logging.getLogger()
logger.info(self)
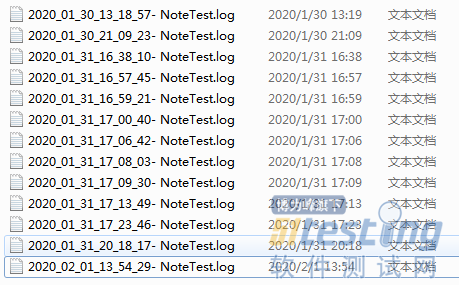
log

日志文件
运行完即可在log目录下保存每次运行的日志。
四、自动化测试
使用unittest框架,测试类需要继承unittest.TestCase。
class NoteTest(unittest.TestCase):
def setUp(self):
saveLog.LogOutput().log_output('NoteTest')
g = getArticle.GetNote()
g.get_note()
# 测试文件存在
def test_fileExists(self):
os.chdir(config.get_path('result_path'))
self.assertTrue(os.path.exists('note' + str(date.today()) + '.csv'))
logging.info('测试用例1:[note' + str(date.today()) + '.csv文件创建]运行通过')
# 测试文件内容存在
def test_resultSaved(self):
with open('note' + str(date.today()) + '.csv', 'r', encoding='utf-8') as rf:
reader = csv.reader(rf)
self.assertIn(['id-notename'], reader)
for i in reader:
logging.info(i)
logging.info('测试用例2:[文件中包含内容]运行通过')
def tearDown(self):
pass
五、保存测试报告
用HTMLTestRunner输出报告。
if __name__ == '__main__':
# unittest.main()
suite = unittest.TestSuite()
suite.addTest(NoteTest("test_fileExists"))
suite.addTest(NoteTest("test_resultSaved"))
html_file = config.get_path('report_path') + '\\report.html'
with open(html_file, "wb") as fp:
runner = HtmlTestRunner.HTMLTestRunner(stream=fp, title='mySpiderProject', description='测试用例')
runner.run(suite)

测试结果
六、其它
这样,一个简易的项目创建成功了,可以将公共方法抽离出来优化代码,也可以继续补充如下额外功能。
1、为项目添加README文件
2、项目提交至GIT
3、Jenkins自动构建
4、邮件通知结果
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












