

前言
在公司的测试平台上,对新写的RPC接口进行测试,但是发现返回的是无法转换POJO的异常:

最初以为只是业务代码写得有问题,结果发现问题并没有那么简单!
排查思路
业务代码问题
第一时间认为是自己业务代码的问题,于是使用公司开源的arthas工具初步确认接口返回的结果异常。然而事情并不如我所料,arthas显示我的接口多次调用均正确地返回了结果。摘取两次显示的结果片段:

这个结果是出乎我意料的,于是我使用idea远程调试以进一步确认,结果也正常返回。因此可以断定不是业务代码出现问题。
RPC框架问题
既然不是业务代码出现问题,那是否可能是我服务端使用的RPC框架出现了问题呢?并且仔细观察测试平台显示的异常信息,可以看到异常是在hsf(公司的RPC框架)中抛出的,异常信息也是POJO对象转化异常,因此我大胆猜测是服务端RPC框架的序列化出现了问题。

于是根据异常信息,我在异常抛出的位置打下了断点进行调试,结果再次出乎我的意料——断点处并没有进入并抛异常。因此排除服务端序列化问题。
测试平台服务端问题
既然不是我服务端的序列化问题,那会不会是测试平台服务器这边的序列化问题呢?测试平台的服务器需要将远程调用结果以json的形式穿给前端进行展示,而我们使用的RPC框架序列化协议是hessain2,因此在测试平台服务器在得到接口返回值后,还需要将其序列化为json给前端展示。
通过询问RPC框架开发人员,得知测试平台的json序列化目前采用的jackson,故在本地使用jackson对结果进行序列化,结果抛出异常:

原因是返回的类内部存在循环引用,导致jackson序列化时栈溢出。
为了进一步确认采用hessain2序列化协议在服务间调用没有问题,我在另一个服务中远程调用本文测试接口,发现结果是正常的。
至此,异常问题基本定位,产生的罪魁祸首在于返回结果中存在循环引用!
解决方案
由于后续我们也需要对这个接口的返回值透出至前端展示,并且目前该类修改成本很大,它包含非常多领域的数据,可以说基本不可能修改,所以需要探寻其它的json序列化方案处理该复杂类以透出到前端展示。
Gson
在使用Gson的过程中,暴露了这个复杂类的另一个问题——类中存在某成员与其父类成员同名,导致Gson抛出IllegalArgumentException异常,而目前该类是无法修改的,因此排除Gson方案。
fastjson
另一个就是常用的就是公司开源的fastjson了,最初直接使用toJSONString接口进行序列化,结果抛出了空指针异常。为了一探究竟,开始扒一扒它的源码。
阅读com.alibaba.fastjson.serializer.JavaBeanSerializer代码可以看到:

fastjson通过getter获取成员并进行序列化,而这里的getter阅读com.alibaba.fastjson.util.TypeUtils.computeGetters代码:
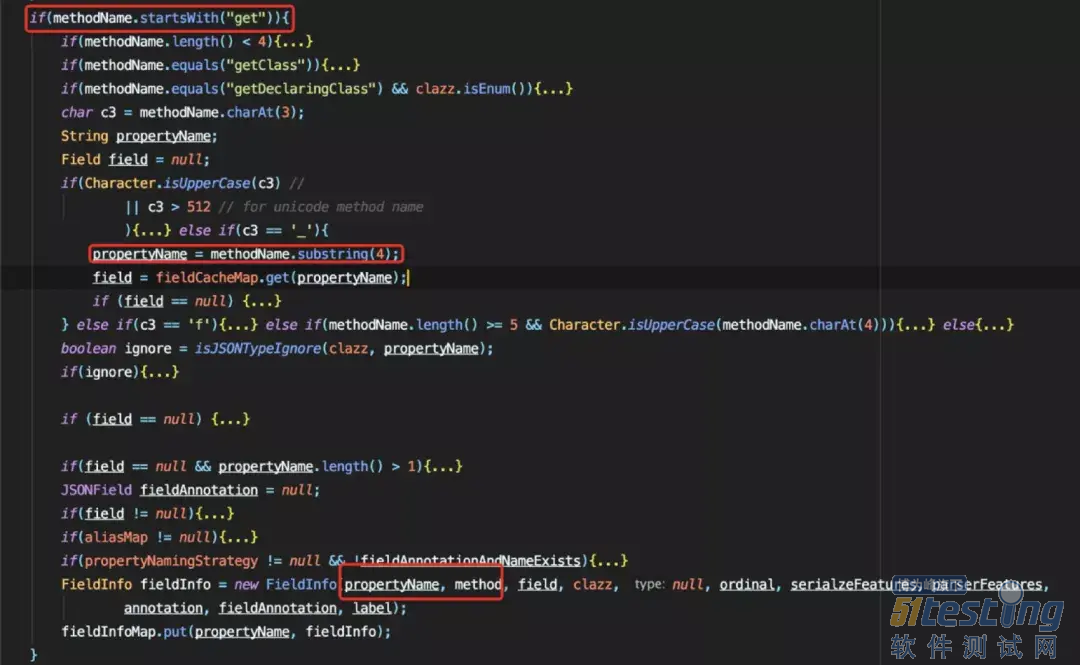
可以看到getter是根据getXxx方法得到,因此,它会调用getXxx方法,而我们的类中存在与成员无关的get方法,同时该方法并没有做好异常处理,因此在调用该方法时抛出了空指针异常。
为了解决这个问题,fastjson在1.2.7之后支持SerializerFeature.IgnoreNonFieldGetter参数,直接在toJSONString接口中添加即可。
至此,序列化结果顺利透出,问题得到解决。对于我们这种复杂返回类型,也暴露了json序列化容易踩的坑,未来需要序列化的对象尽量遵循几个原则:
避免循环依赖;
子类不与父类定义相同名称的成员;
避免定义非成员变量的getter/setter方法。
循环引用解决原理
循环引用造成问题的场景主要可以分为序列化和对象创建两种,假定类A对象引用类B对象,类B对象引用类A对象:
序列化A对象的时候,同时又会序列化B对象,序列化B对象的时候,又会反过来序列化A对象,如果采用递归实现,最终会导致堆栈溢出,如果采用循环实现,则会导致死循环;
创建A对象的时候,需要装载B对象,而B对象又反过来需要装载A,最终导致对象创建失败。
为了解决循环引用带来的上述问题,本质上需要将循环引用中的其中一个对象缓存起来,以避免重复地序列化或创建。具体案例如下:
fastjson/hessian
前文提到的jackson和Gson是不支持存在循环引用对象的序列化的,fastjson/hessain则是解决序列化场景循环引用的典型。阅读com.alibaba.fastjson.serializer.JavaBeanSerializer代码可以看到:

它有专门针对循环引用的方法,这里实际是对对象进行了缓存,如果引用的对象在缓存中,则不进一步进行序列化,而是以ref符号代替,规则如下:
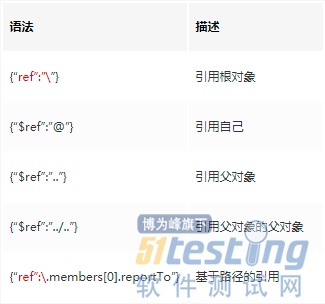
hessian实际也是采用的相同的方式解决循环引用问题的,阅读com.caucho.hessian.io.AbstractSerializer即可看到:

这里采用的方式是一样的,每次序列化前先判断是否在缓存中即可。
Spring
Spring是自动创建对象场景的典型,它采用三级缓存的方式解决循环引用对象的创建。
一级缓存:已经完全创建好的对象的缓存; 二级缓存:正在创建中,某些成员还未装载的对象的缓存; 三级缓存:存放创建对象方法的缓存(即存放工厂,而非对象的缓存)。
假定类A对象引用类B对象,类B对象引用类A对象,在创建类A对象的过程中,需要装载B对象,这时首先会在一级缓存中寻找B对象,若没有,则在二级缓存在找,若依然没有,则会从三级缓存找到创建B的方法,并创建一个"裸"bean(未装载成员对象的bean),放进二级缓存,然后将这个对象装载给A对象,同时还会将三级缓存中创建B的方法移除,防止重复创建,最后将A对象放入一级缓存。创建B对象时,直接在一级缓存中即可找到A对象进行装载,最后再将自己放入一级缓存中。
实际整个过程中,二级缓存承担的是解决循环引用问题的角色,个人理解三级缓存主要是为了实现上的优雅而存在的,没有也不影响循环引用问题的解决。
总结
从开发侧和工具侧两个方面做一些总结:
开发侧:json序列化是很容易踩坑的,未来需要序列化的对象尽量做到避免循环依赖、子类不与父类定义相同名称的成员、避免定义非成员变量的getter/setter方法。
工具侧:如果涉及到序列化和对象创建工具的开发,那么需要考虑循环引用问题的解决,主要方法即将循环引用中的其中一个对象缓存起来,以避免重复地序列化或创建。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












