

背景:为啥要去爬mp3?因为要收费下载了,买不起会员?还是花不起流量在线听?站在技术层面来说,如果是通过代码去解决以上烦恼,那么也就只是打算秀一把!
一、爬虫,在互联网时代已经是屡见不鲜的事情,我没有的就先考虑一下拿来主义!譬如一些通过中间商赚取差价获取利润的公司,首先声明一点,只要不干坏事,爬个东西应该不犯法,但是也不要做其他用途损害"东家"利益。既然有爬虫,必然也会有反爬虫。我们知道爬虫就是假装客户端发起一堆请求去获取服务器端返回的各种数据,那么服务端不允许爬虫,就需要考虑封杀非法过来的请求。先来说说如何做到反爬虫的:
· ip,如果我是通过nginx做代理的话,知道了同一个ip频繁请求某一个接口时,我就认为你是恶意的,我可能就要将这个ip重定向到其他页面,当然这些条件也可以在代码层进行全面控制;
· 请求头:User-agent,代理客户端,像一些工具做的爬虫都有自己的特殊标识,如:jmeter、python-requests、selenium等等,所以在nginx的location块里使用if ($User-Agent ~(xxx|xxx))然后重定向返回其他页面即可;
· 如果是通过访问html页面的dom元素进行爬虫,那么就可以更改html对应的元素信息即可让爬虫失效,或者重新定位开发增加他们的开发成本;
· 当然还有校验爬虫过来的其他请求头信息进行反爬虫。
二、既然知道了如何反爬虫,那么爬虫对于喜欢专研技术的人而言,那么就不攻自破了。
构造请求头信息:
· 获取ip池或者生成自己的ip库以供爬虫使用:www.xicidaili.com/nn/这个是基本失效的ip池;
生成自己的ip池,需要时刻监测ip是否可用
· User_agent,python中的fake_useragent库,提供了用户代理
from fake_useragent import UserAgent
· Referer如有必要这个参数是指从哪里请求过来的,那么请求我服务器的资源,也只允许这个地方来的;
· 当然还有浏览器的cookie,这些饼干信息对于爬虫也是相对重要的。
三、了解了爬虫与反爬虫,那么结合标题示例,我们来从163音乐网站下载mp3,正常情况下,不是要充钱就是要资源付费。
第一步:在不知道下载地址的情况下,先不要写任何代码;先获取music.163.com/#网易云下载mp3地址
· 抓包工具wireshark、charles、浏览器F12功能
· 经过工具层层分析,有点抱歉,咱找不到能正确下载mp3的url
方法一:点击标题播放音乐
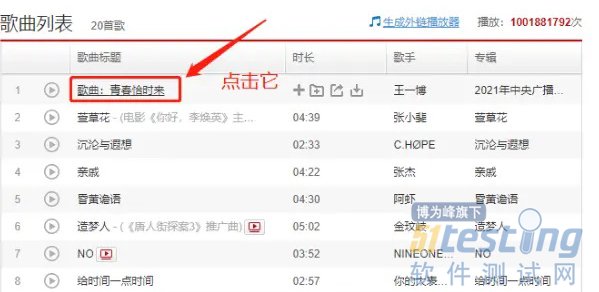
新页面,点击生成外链播放器

访问插件地址
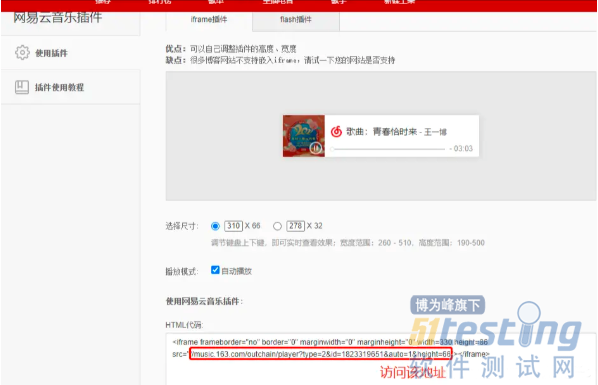
获取url:music.163.com/weapi/song/…返回结果:data下url的值:m801.music.126.net/20210302121…

这个地址是可访问的,即在dos下通过curl -O 下载该地址的mp3
如此方法一就得到了一个mp3的下载地址,但是,这样是不是爬得很辛苦,虽然只要在点击title生成播放页面更改id即可:music.163.com/#/song?id=1…
方法二:内事不决问度娘,所以三下五除二得到MP3转换地址为:music.163.com/song/media/… 如果知道了歌曲的id,替换红色部分即可下载;
使用浏览器访问:music.163.com/song/media/…
第二步:既然上面的步骤已经得到了mp3下载地址,那么下面就可以大刀阔斧的开始写代码了
def download_by_songID(song_id, song_name):
url="https://music.163.com/song/media/outer/url?id={}.mp3".format(song_id)
req = requests.get(url, headers=headers, allow_redirects=False)
req_url=req.headers['Location']
request.urlretrieve(req_url, path_config.music_path + "{}.mp3".format(song_name))
song_id = input("请输入song_id:")
song_name = input("请输入song_name:")
download_by_songID("{}".format(song_id), "{}".format(song_name))
except Exception as e:
第三步:上面的代码就完成了MP3下载功能,接下来要做的就是伪装,让人家反爬虫认可你,需要构造headers了。
# 还记得上面的fake_useragent库吗?
from fake_useragent import UserAgent
headers = {"Connection": "keep-alive",
"user-agent": ua.random,
"Host": "music.163.com",
"sec-fetch-mode": "nested-navigate"
至此,网易云mp3下载脚本完成,是不是觉得很不错?当然它也有一些必须要付费的mp3才能下载。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












