

深入理解MVCC
MVCC多版本并发控制机制,Mysql在读已提交和可重复读隔离级别下都实现了MVCC机制。
MVCC最大的优势:读不加锁,读写不冲突。在读多写少的应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能。
MVCC机制的实现就是通过ReadView与undo_log版本链,使得不同的事务会根据数据版本链对比规则读取同一条数据在版本链上的不同版本数据。
我们来了解一下undo_log版本链:
undo_log版本链是指某一行数据被多个事务依次修改过后,Mysql会保留修改前的数据undo回滚日志,并且用两个隐藏字段trx_id和roll_pointer把这些undo日志串联起来形成一个历史记录版本链,如下图:
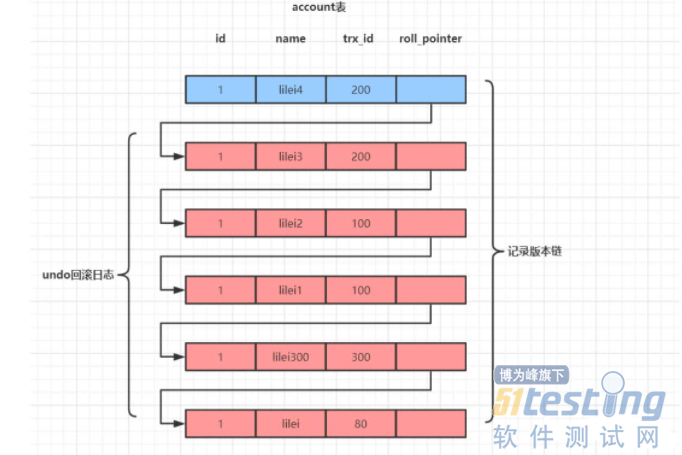
可以理解为一个单链表,表尾的数据为最新的数据,而表头的数据为最古老的数据。
说了版本链我们再来看看ReadView。
已提交读和可重复读的区别就在于它们生成ReadView的策略不同, 已提交读的事务中的每一次查询都会生成一个新的ReadView,而可重复读的事务中则不会。
那么究竟什么是ReadView呢?
通俗点说,就是在已提交读或者可重复读的隔离级别下,我们执行查询的时候,MYSQL内部会给我们维护一份活跃的事务列表,即begin了但还没有conmmit的事务id,比如ReadView为[30,60],那么说明30之前的事务都是已经提交的,60之后的事务是在当前ReadView生成之后才begin的。
举个例子 ,在已提交读隔离级别下:
比如此时有一个事务id为100的事务,修改了name,使得的name等于小明2,但是事务还没提交。则此时的版本链是:
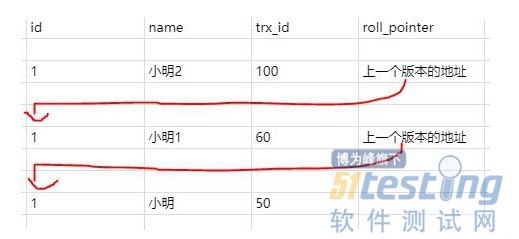
那此时另一个事务发起了select 语句要查询id为1的记录,那此时生成的ReadView 列表只有[100]。
那就去版本链去找了,首先肯定找最近的一条,发现trx_id是100,也就是name为小明2的那条记录,发现在列表内,所以不能访问。
这时候就通过指针继续找下一条,name为小明1的记录,发现trx_id是60,小于列表中的最小id,所以可以访问,直接访问结果为小明1。
那这时候我们把事务id为100的事务提交了,并且新建了一个事务id为110也修改id为1的记录,并且不提交事务:

这时候版本链就是:
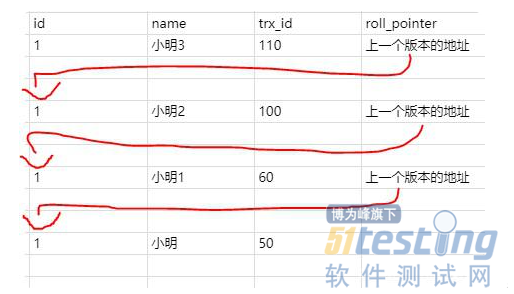
这时候之前那个select事务又执行了一次查询,要查询id为1的记录。
这个时候关键的地方来了,如果你是已提交读隔离级别,这时候你会重新一个ReadView,那你的活动事务列表中的值就变了,变成了[110]。
按照上的说法,你去版本链通过trx_id对比查找到合适的结果就是小明2。
如果你是可重复读隔离级别,这时候你的ReadView还是第一次select时候生成的ReadView,也就是列表的值还是[100]。所以select的结果是小明1。
所以第二次select结果和第一次一样,所以叫可重复读!
也就是说已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView。
这就是Mysql的MVCC,通过版本链,实现多版本,可并发读-写,写-读。通过ReadView生成策略的不同实现不同的隔离级别。
Innobd核心之BurfferPool缓存机制
为什么Mysql不直接更新磁盘上的数据而是设置这么一套BurfferPool机制来执行SQL呢?
因为来一个请求就直接对磁盘文件进行随机读写,然后更新磁盘文件里的数据性能可能相当差。
因为磁盘随机读写的性能是非常差的,所以直接更新磁盘文件是不能让数据库抗住很高并发的。
Mysql这套机制看起来复杂,但它可以保证每个更新请求都是更新内存BufferPool,然后顺序写日志文件,同时还能保证各种异常情况下的数据一致性。
更新内存的性能是极高的,然后顺序写磁盘上的日志文件的性能也是非常高的,要远高于随机读写磁盘文件。
正是通过这套机制,才能让我们的MySQL数据库在较高配置的机器上每秒可以抗下几干的读写请求。
下面我们看一下BurfferPool缓存机制的流程图:
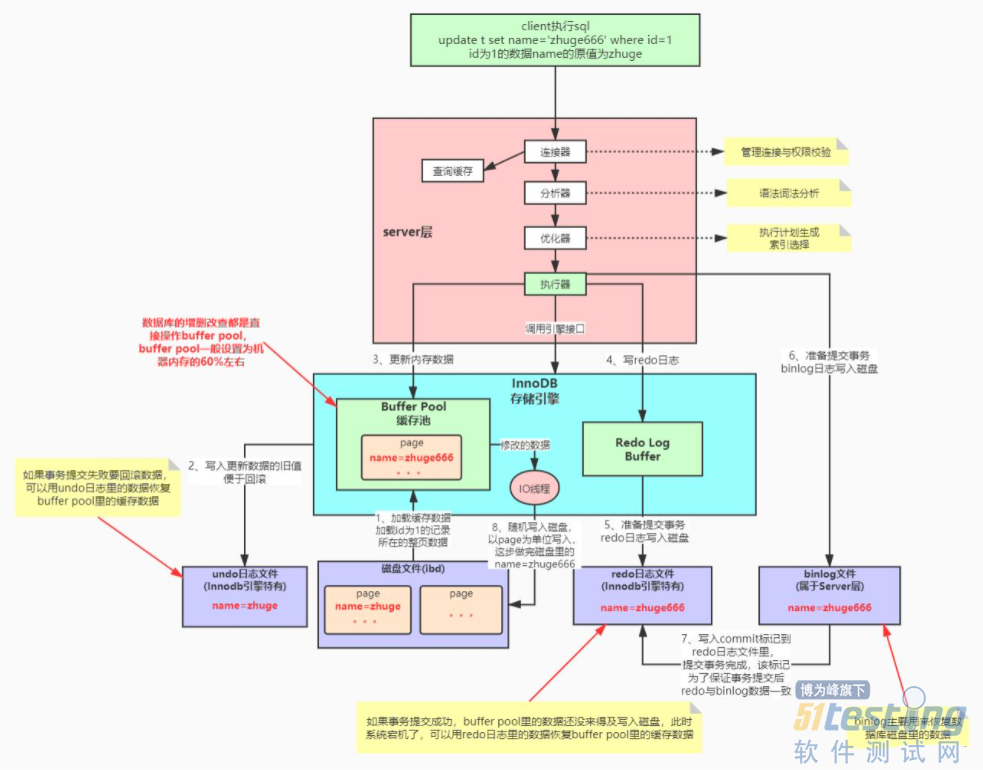
比如我们的SQL是一个update语句,实际上,MYSQL在更新之前会先进行查询。
经过MYSQL优化器优化之后得到最终的执行计划,然后执行器会先去磁盘中找到对应的数据,因为数据在磁盘上是以页的形式存储的,根据操作系统的预读取功能,会加载一整页的数据到BufferPool缓存池中。
将更新之前的数据写入undo_log,方便回滚操作。
undo_log写入成功之后,然后在BufferPool缓存池中进行数据更新。
BufferPool数据更新成功之后,会将最新的数据写入Redo_log_buffer。
在提交事务的时候,会将Redo_log_buffer中的数据写入Redo_log,主要作用是用于恢复BufferPool的数据
在操作5进行的同时,会异步开一个线程去将bin_log日志写入bin_log文件。
bin_log文件写入成功之后,最后会在redo_log文件中对应的数据打上一个commit的标记,为了保证事务提交后,redo_log和bin_log的数据一致性。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












