

近期,专家发现一种新的攻击方式。该攻击利用视频电话将可观察到的身体运动与正在输入的文本相联系,来推断出用户在视频电话时键入的信息。
这项研究是由Mohd Sabra和得克萨斯大学圣安东尼奥分校的Murtuza Jadliwala以及俄克拉荷马大学的Anindya Maiti进行的。他们表示,只要网络摄像头可以捕捉到目标用户的上半身动作,该攻击的范围就可以从视频电话扩展到YouTube和Twitch等视频网站上。
研究人员表示,随着视频捕获硬件嵌入越来越多的电子产品中,比如智能手机、平板电脑、笔记本电脑等,通过视觉渠道造成信息泄露的威胁在最近逐步扩增。此外,他们还称,这些攻击者的目标是利用在所有记录的帧上可观察到的上半身运动来推断受害者输入的私人文本。
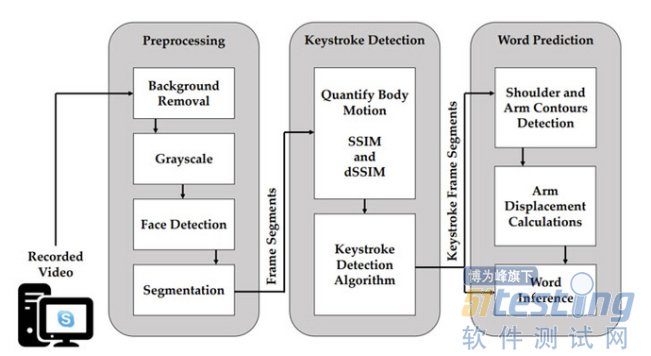
为了实现这个目的,录制的视频被输入到基于视频的按键推断框架中,该框架经历了三个阶段:
进行预处理:将背景移除后,视频将转为灰阶,然后用FaceBoxes的模型检测到的个人脸部,对左右手臂区域进行分割。
按键检测:检索分割后的含有手臂动作的帧数来进行结构相似度指数测量(SSIM),量化左右两侧视频段中每个连续帧之间的身体动作,并识别出发生按键的潜在帧。
单词预测:按键帧将用于检测每个按键前后的运动特征,并通过基于字典的预测算法来推断特定的单词。
换句话说,在检测到的按键帧池中,通过检测到的单词输入次数以及在单词的连续输入之间所发生的手臂位移的大小和方向来推断单词。
这种位移是用一种叫做稀疏光流的计算机视觉技术来测量的,这种技术被用来跟踪肩部和手臂在计时按键帧中的运动。
本文内容不用于商业目的,如涉及知识产权问题,请权利人联系51Testing小编(021-64471599-8017),我们将立即处理












