

一、逻辑回归的简介
逻辑回归,英文名是logistic regression。它是一种广泛使用的机器学习算法。尽管名字中有“回归”二字,但它其实是一种二元分类算法,也就是通过已知的自变量来预测数据是属于哪个类别的(也就是,判断数据的标签是 真或假,是或否等)。
在现实生活中,也有很多二元分类问题。例如,判断一封邮件是否为垃圾邮件?判断一次金融交易是否存在欺诈嫌疑?判断肿瘤是否是良性的?
二、逻辑回归的数学思想
通过拟合一个逻辑函数/假设函数(logic function/hypothesis function)来预测一个事件发生的概率,既然预测的是概率值,那么输出结果必须在(0--1)之间。
一般线性回归的结果(即y=h(Θ,x)的结果)是连续值,取值范围也是不确定的。我们需要找到一个数学公式,将连续值转换成(0--1)之间的值。
这个转换函数就是sigmoid函数: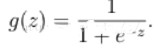 ,它的图像如下:
,它的图像如下:
,它的图像如下: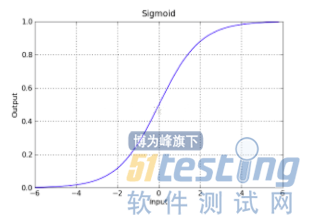
三、逻辑回归的算法步骤
初始化权重:即给定向量Θ的初始值,方便后续不断迭代更新。
加载数据:加载训练数据,方便拟合出假设函数
计算假设函数
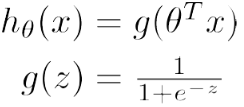
注:上面的公式表面自变量和标签之间的函数关系,下面的公式将标签取值范围缩小到0到1之间,以判断一个事件发生的概率。
计算单一样本的代价函数
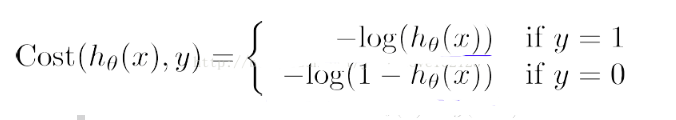
注:对单一样本而言,它的错分类代价就是:当Y等于1时,h(x)的结果是0;当Y等于0时,h(x)的结果是1.
计算总体样本的损失函数:即N个样本的代价均值。
使用梯度下降法来迭代更新参数值向量Θ,以保证损失函数最小

7.测试:用拟合好的假设函数,对测试数据集进行分类。
四、逻辑回归的PYTHON实现
import os import string import sys import math class LogisticRegression: def __init__(self): self.__X = [] # 特征集合 self.__Y = [] # 标签 self.__theta = [] # 权重 self.__LEARNING_RATE = 7 # 学习率 self.__FEATURE_CNT = 1 + 2 # 特征数 self.__load_training_data() # 加载数据 self.__SAMPLE_CNT = len(self.__Y) # 样本数 self.__feature_scaling() # 特征缩放 for idx in range(0, self.__FEATURE_CNT): self.__theta.append(0) def __load_training_data(self): # 加载训练数据,分离出特征和标签 fp = open(r"E:\xdlv\testSet.txt", "r") for line in fp.readlines(): (x1, x2, y) = line.strip('\r\n').split('\t') self.__X.append([1, float(x1), float(x2)]) self.__Y.append(float(y)) fp.close() def __feature_scaling(self): #为了帮助梯度下降算法收敛更快,进行特征缩放,使所有特征的取值范围具有相似的尺度。 max_value = [] min_value = [] for fidx in range(0, self.__FEATURE_CNT): max_value.append(0) min_value.append(100) for idx in range(0, self.__SAMPLE_CNT):#依次遍历每一个样本的每一个特征值,找到每一个特征值的最大值和最小值,然后做特征变换。 for fidx in range(1, self.__FEATURE_CNT): if max_value[fidx] < self.__X[idx][fidx]: max_value[fidx] = self.__X[idx][fidx] if min_value[fidx] > self.__X[idx][fidx]: min_value[fidx] = self.__X[idx][fidx] for idx in range(0, self.__SAMPLE_CNT): x = self.__X[idx] for fidx in range(1, self.__FEATURE_CNT): self.__X[idx][fidx] = (x[fidx] - min_value[fidx]) / (max_value[fidx] - min_value[fidx]) def batch_learning_alogrithm(self):#机器学习流程:迭代到10W次,每次迭代中训练数据(更新参数集),知道Loss收敛到最小。 last_loss = 0 for itr in range(1, 100000): # 1、训练数据 self.__training() loss = self.__get_loss() sys.stdout.write("After %s iteratorion loss = %lf\n" % (itr, loss)) if math.fabs(loss - last_loss) <= 0.01: break; last_loss = loss sys.stdout.write("The coef of the logistic model :\n") for idx in range(0, self.__FEATURE_CNT): sys.stdout.write("theta[%d] = %lf\n" % (idx, self.__theta[idx])) def __training(self): # 初始化权重为[0 0 0] weight = [] for idx in range(0, self.__FEATURE_CNT): weight.append(0) """计算loss""" for idx in range(0, self.__SAMPLE_CNT): x = self.__X[idx] y = self.__Y[idx] h = self.__sigmoid(x) for fidx in range(0, self.__FEATURE_CNT): weight[fidx] += (h - y) * x[fidx] """更新权重""" for idx in range(0, self.__FEATURE_CNT): self.__theta[idx] -= self.__LEARNING_RATE * weight[idx] / self.__SAMPLE_CNT def __sigmoid(self, x): logit = 0 for idx in range(0, self.__FEATURE_CNT): logit += self.__theta[idx] * x[idx] return 1.0 / (1.0 + math.exp(-logit)) def __get_loss(self): loss = 0 for idx in range(0, self.__SAMPLE_CNT): x = self.__X[idx] y = self.__Y[idx] h = self.__sigmoid(x) loss += y * math.log(h) + (1 - y) * math.log(1 - h) return loss def test(self): wrong_ans = 0 for idx in range(0, self.__SAMPLE_CNT): x = self.__X[idx] y = self.__Y[idx] h = self.__sigmoid(x) check = 0 if y > 0.5 and h < 0.5: check = -1 if y < 0.5 and h > 0.5: check = -1 sys.stdout.write("样本 %d : 真值 = %.2lf, 预测 = %.2lf check = %d\n" % (idx, y, h, check)) wrong_ans -= check print "错误 = %d" % wrong_ans if __name__ == "__main__": #main是主函数,也是程序入口。 lr = LogisticRegression() lr.batch_learning_alogrithm() lr.test() |
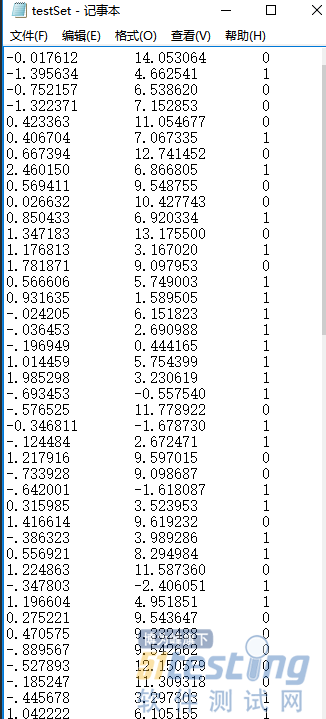
测试数据:
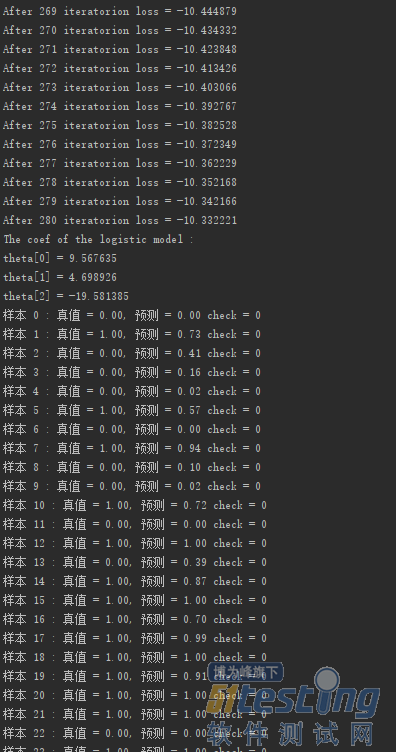
运行结果:
后记:
整个逻辑回归的基础知识就介绍到这里了,我个人觉得代码实现并不是最大的困难,难点是数学公式的推导。学习算法的时候,要理解每一步数学公式的作用和含义,然后再用Python把数学公式实现出来就可以了。朋友们,你GET到了吗?
......
查看更多精彩内容,请点击下载:
版权声明:本文出自《51测试天地》第五十四期。51Testing软件测试网及相关内容提供者拥有51testing.com内容的全部版权,未经明确的书面许可,任何人或单位不得对本网站内容复制、转载或进行镜像,否则将追究法律责任。












