

前言
“快速,灵活,富有表现力的数据结构,旨在使”关系“或”标记“数据的使用既简单又直观。”
我们知道pandas的两个主要数据结构:dataframe和series,我们对数据的一些操作都是基于这两个数据结构的。但在实际的使用中,我们可能很多时候会感觉运行一些数据结构的操作会异常的慢。一个操作慢几秒可能看不出来什么,但是一整个项目中很多个操作加起来会让整个开发工作效率变得很低。有的朋友抱怨pandas简直太慢了,其实对于pandas的一些操作也是有一定技巧的。

pandas是基于numpy库的数组结构上构建的,并且它的很多操作都是(通过numpy或者pandas自身由Cpython实现并编译成C的扩展模块)在C语言中实现的。因此,如果正确使用pandas的话,它的运行速度应该是非常快的。
本篇将要介绍几种pandas中常用到的方法,对于这些方法使用存在哪些需要注意的问题,以及如何对它们进行速度提升。
将datetime数据与时间序列一起使用的优点
进行批量计算的最有效途径
通过HDFStore存储数据节省时间
使用Datetime数据节省时间
我们来看一个例子。
>>> import pandas as pd >>> pd.__version__ '0.23.1' # 导入数据集 >>> df = pd.read_csv('demand_profile.csv') >>> df.head() date_time energy_kwh 0 1/1/13 0:00 0.586 1 1/1/13 1:00 0.580 2 1/1/13 2:00 0.572 3 1/1/13 3:00 0.596 4 1/1/13 4:00 0.592 |
从运行上面代码得到的结果来看,好像没有什么问题。但实际上pandas和numpy都有一个 dtypes 的概念。如果没有特殊声明,那么date_time将会使用一个 object的dtype类型,如下面代码所示:
>>> df.dtypes date_time object energy_kwh float64 dtype: object >>> type(df.iat[0, 0]) str |
object 类型像一个大的容器,不仅仅可以承载 str,也可以包含那些不能很好地融进一个数据类型的任何特征列。而如果我们将日期作为 str 类型就会极大的影响效率。
因此,对于时间序列的数据而言,我们需要让上面的date_time列格式化为datetime对象数组(pandas称之为时间戳)。pandas在这里操作非常简单,操作如下:
>>> df['date_time'] = pd.to_datetime(df['date_time']) >>> df['date_time'].dtype datetime64[ns] |
我们来运行一下这个df看看转化后的效果是什么样的。
>>> df.head() date_time energy_kwh 0 2013-01-01 00:00:00 0.586 1 2013-01-01 01:00:00 0.580 2 2013-01-01 02:00:00 0.572 3 2013-01-01 03:00:00 0.596 4 2013-01-01 04:00:00 0.592 |
date_time的格式已经自动转化了,但这还没完,在这个基础上,我们还是可以继续提高运行速度的。如何提速呢?为了更好的对比,我们首先通过 timeit 装饰器来测试一下上面代码的转化时间。
>>> @timeit(repeat=3, number=10) ... def convert(df, column_name): ... return pd.to_datetime(df[column_name]) >>> df['date_time'] = convert(df, 'date_time') Best of 3 trials with 10 function calls per trial: Function `convert` ran in average of 1.610 seconds. |
1.61s,看上去挺快,但其实可以更快,我们来看一下下面的方法。
>>> @timeit(repeat=3, number=100) >>> def convert_with_format(df, column_name): ... return pd.to_datetime(df[column_name], ... format='%d/%m/%y %H:%M') Best of 3 trials with 100 function calls per trial: Function `convert_with_format` ran in average of 0.032 seconds. |
结果只有0.032s,快了将近50倍。原因是:我们设置了转化的格式format。由于在CSV中的datetimes并不是 ISO 8601 格式的,如果不进行设置的话,那么pandas将使用 dateutil 包把每个字符串str转化成date日期。
相反,如果原始数据datetime已经是 ISO 8601 格式了,那么pandas就可以立即使用最快速的方法来解析日期。这也就是为什么提前设置好格式format可以提升这么多。
pandas数据的循环操作
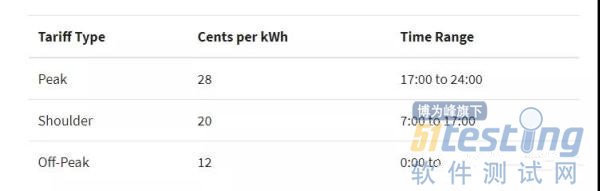
仍然基于上面的数据,我们想添加一个新的特征,但这个新的特征是基于一些时间条件的,根据时长(小时)而变化,如下:
还在抱怨Pandas运行速度慢?这几个方法会颠覆你的看法
因此,按照我们正常的做法就是使用apply方法写一个函数,函数里面写好时间条件的逻辑代码。
def apply_tariff(kwh, hour): """计算每个小时的电费""" if 0 <= hour < 7: rate = 12 elif 7 <= hour < 17: rate = 20 elif 17 <= hour < 24: rate = 28 else: raise ValueError(f'Invalid hour: {hour}') return rate * kwh |
然后使用for循环来遍历df,根据apply函数逻辑添加新的特征,如下:
>>> # 不赞同这种操作 >>> @timeit(repeat=3, number=100) ... def apply_tariff_loop(df): ... """Calculate costs in loop. Modifies `df` inplace.""" ... energy_cost_list = [] ... for i in range(len(df)): ... # 获取用电量和时间(小时) ... energy_used = df.iloc[i]['energy_kwh'] ... hour = df.iloc[i]['date_time'].hour ... energy_cost = apply_tariff(energy_used, hour) ... energy_cost_list.append(energy_cost) ... df['cost_cents'] = energy_cost_list ... >>> apply_tariff_loop(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_loop` ran in average of 3.152 seconds. |
对于那些写Pythonic风格的人来说,这个设计看起来很自然。然而,这个循环将会严重影响效率,也是不赞同这么做。原因有几个:
首先,它需要初始化一个将记录输出的列表。
其次,它使用不透明对象范围(0,len(df))循环,然后在应用apply_tariff()之后,它必须将结果附加到用于创建新DataFrame列的列表中。它还使用df.iloc [i] ['date_time']执行所谓的链式索引,这通常会导致意外的结果。
但这种方法的最大问题是计算的时间成本。对于8760行数据,此循环花费了3秒钟。接下来,你将看到一些改进的Pandas结构迭代解决方案。
使用itertuples() 和iterrows() 循环
那么推荐做法是什么样的呢?
实际上可以通过pandas引入itertuples和iterrows方法可以使效率更快。这些都是一次产生一行的生成器方法,类似scrapy中使用的yield用法。
.itertuples为每一行产生一个namedtuple,并且行的索引值作为元组的第一个元素。nametuple是Python的collections模块中的一种数据结构,其行为类似于Python元组,但具有可通过属性查找访问的字段。
.iterrows为DataFrame中的每一行产生(index,series)这样的元组。
虽然.itertuples往往会更快一些,但是在这个例子中使用.iterrows,我们看看这使用iterrows后效果如何。
>>> @timeit(repeat=3, number=100) ... def apply_tariff_iterrows(df): ... energy_cost_list = [] ... for index, row in df.iterrows(): ... # 获取用电量和时间(小时) ... energy_used = row['energy_kwh'] ... hour = row['date_time'].hour ... # 添加cost列表 ... energy_cost = apply_tariff(energy_used, hour) ... energy_cost_list.append(energy_cost) ... df['cost_cents'] = energy_cost_list ... >>> apply_tariff_iterrows(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_iterrows` ran in average of 0.713 seconds. |
语法方面:这样的语法更明确,并且行值引用中的混乱更少,因此它更具可读性。
在时间收益方面:快了近5倍! 但是,还有更多的改进空间。我们仍然在使用某种形式的Python for循环,这意味着每个函数调用都是在Python中完成的,理想情况是它可以用Pandas内部架构中内置的更快的语言完成。
Pandas的 .apply()方法
我们可以使用.apply方法而不是.iterrows进一步改进此操作。Pandas的.apply方法接受函数(callables)并沿DataFrame的轴(所有行或所有列)应用它们。在此示例中,lambda函数将帮助你将两列数据传递给apply_tariff():
>>> @timeit(repeat=3, number=100) ... def apply_tariff_withapply(df): ... df['cost_cents'] = df.apply( ... lambda row: apply_tariff( ... kwh=row['energy_kwh'], ... hour=row['date_time'].hour), ... axis=1) ... >>> apply_tariff_withapply(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_withapply` ran in average of 0.272 seconds. |
.apply的语法优点很明显,行数少,代码可读性高。在这种情况下,所花费的时间大约是.iterrows方法的一半。
但是,这还不是“非常快”。一个原因是.apply()将在内部尝试循环遍历Cython迭代器。但是在这种情况下,传递的lambda不是可以在Cython中处理的东西,因此它在Python中调用,因此并不是那么快。
如果你使用.apply()获取10年的小时数据,那么你将需要大约15分钟的处理时间。如果这个计算只是大型模型的一小部分,那么你真的应该加快速度。这也就是矢量化操作派上用场的地方。
矢量化操作:使用.isin()选择数据
什么是矢量化操作?如果你不基于一些条件,而是可以在一行代码中将所有电力消耗数据应用于该价格(df ['energy_kwh'] * 28),类似这种。这个特定的操作就是矢量化操作的一个例子,它是在Pandas中执行的最快方法。
但是如何将条件计算应用为Pandas中的矢量化运算?一个技巧是根据你的条件选择和分组DataFrame,然后对每个选定的组应用矢量化操作。 在下一个示例中,你将看到如何使用Pandas的.isin()方法选择行,然后在向量化操作中实现上面新特征的添加。在执行此操作之前,如果将date_time列设置为DataFrame的索引,则会使事情更方便:
df.set_index('date_time', inplace=True) @timeit(repeat=3, number=100) def apply_tariff_isin(df): # 定义小时范围Boolean数组 peak_hours = df.index.hour.isin(range(17, 24)) shoulder_hours = df.index.hour.isin(range(7, 17)) off_peak_hours = df.index.hour.isin(range(0, 7)) # 使用上面的定义 df.loc[peak_hours, 'cost_cents'] = df.loc[peak_hours, 'energy_kwh'] * 28 df.loc[shoulder_hours,'cost_cents'] = df.loc[shoulder_hours, 'energy_kwh'] * 20 df.loc[off_peak_hours,'cost_cents'] = df.loc[off_peak_hours, 'energy_kwh'] * 12 |
我们来看一下结果如何。
>>> apply_tariff_isin(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_isin` ran in average of 0.010 seconds. |
为了了解刚才代码中发生的情况,我们需要知道.isin()方法返回的是一个布尔值数组,如下所示:
| [False, False, False, ..., True, True, True] |
这些值标识哪些DataFrame索引(datetimes)落在指定的小时范围内。然后,当你将这些布尔数组传递给DataFrame的.loc索引器时,你将获得一个仅包含与这些小时匹配的行的DataFrame切片。在那之后,仅仅是将切片乘以适当的费率,这是一种快速的矢量化操作。
这与我们上面的循环操作相比如何?首先,你可能会注意到不再需要apply_tariff(),因为所有条件逻辑都应用于行的选择。因此,你必须编写的代码行和调用的Python代码会大大减少。
处理时间怎么样?比不是Pythonic的循环快315倍,比.iterrows快71倍,比.apply快27倍。
还可以做的更好吗?
在apply_tariff_isin中,我们仍然可以通过调用df.loc和df.index.hour.isin三次来进行一些“手动工作”。如果我们有更精细的时隙范围,你可能会争辩说这个解决方案是不可扩展的。幸运的是,在这种情况下,你可以使用Pandas的pd.cut() 函数以编程方式执行更多操作:
@timeit(repeat=3, number=100) def apply_tariff_cut(df): cents_per_kwh = pd.cut(x=df.index.hour, bins=[0, 7, 17, 24], include_lowest=True, labels=[12, 20, 28]).astype(int) df['cost_cents'] = cents_per_kwh * df['energy_kwh'] |
让我们看看这里发生了什么。pd.cut() 根据每小时所属的bin应用一组标签(costs)。
注意include_lowest参数表示第一个间隔是否应该是包含左边的(您希望在组中包含时间= 0)。
这是一种完全矢量化的方式来获得我们的预期结果,它在时间方面是最快的:
>>> apply_tariff_cut(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_cut` ran in average of 0.003 seconds. |
到目前为止,时间上基本快达到极限了,只需要花费不到一秒的时间来处理完整的10年的小时数据集。但是,最后一个选项是使用 NumPy 函数来操作每个DataFrame的底层NumPy数组,然后将结果集成回Pandas数据结构中。
使用Numpy继续加速
使用Pandas时不应忘记的一点是Pandas Series和DataFrames是在NumPy库之上设计的。这为你提供了更多的计算灵活性,因为Pandas可以与NumPy阵列和操作无缝衔接。
下面,我们将使用NumPy的 digitize() 函数。它类似于Pandas的cut(),因为数据将被分箱,但这次它将由一个索引数组表示,这些索引表示每小时所属的bin。然后将这些索引应用于价格数组:
@timeit(repeat=3, number=100) def apply_tariff_digitize(df): prices = np.array([12, 20, 28]) bins = np.digitize(df.index.hour.values, bins=[7, 17, 24]) df['cost_cents'] = prices[bins] * df['energy_kwh'].values |
与cut函数一样,这种语法非常简洁易读。但它在速度方面有何比较?让我们来看看:
>>> apply_tariff_digitize(df) Best of 3 trials with 100 function calls per trial: Function `apply_tariff_digitize` ran in average of 0.002 seconds. |
在这一点上,仍然有性能提升,但它本质上变得更加边缘化。使用Pandas,它可以帮助维持“层次结构”,如果你愿意,可以像在此处一样进行批量计算,这些通常排名从最快到最慢(最灵活到最不灵活):
使用向量化操作:没有for循环的Pandas方法和函数。
将.apply方法:与可调用方法一起使用。
使用.itertuples:从Python的集合模块迭代DataFrame行作为namedTuples。
使用.iterrows:迭代DataFrame行作为(index,Series)对。虽然Pandas系列是一种灵活的数据结构,但将每一行构建到一个系列中然后访问它可能会很昂贵。
使用“element-by-element”循环:使用df.loc或df.iloc一次更新一个单元格或行。
还在抱怨Pandas运行速度慢?这几个方法会颠覆你的看法

使用HDFStore防止重新处理
现在你已经了解了Pandas中的加速数据流程,接着让我们探讨如何避免与最近集成到Pandas中的HDFStore一起重新处理时间。
通常,在构建复杂数据模型时,可以方便地对数据进行一些预处理。例如,如果您有10年的分钟频率耗电量数据,即使你指定格式参数,只需将日期和时间转换为日期时间可能需要20分钟。你真的只想做一次,而不是每次运行你的模型,进行测试或分析。
你可以在此处执行的一项非常有用的操作是预处理,然后将数据存储在已处理的表单中,以便在需要时使用。但是,如何以正确的格式存储数据而无需再次重新处理?如果你要另存为CSV,则只会丢失datetimes对象,并且在再次访问时必须重新处理它。
Pandas有一个内置的解决方案,它使用 HDF5,这是一种专门用于存储表格数据阵列的高性能存储格式。 Pandas的 HDFStore 类允许你将DataFrame存储在HDF5文件中,以便可以有效地访问它,同时仍保留列类型和其他元数据。它是一个类似字典的类,因此您可以像读取Python dict对象一样进行读写。
以下是将预处理电力消耗DataFrame df存储在HDF5文件中的方法:
# 创建储存对象,并存为 processed_data data_store = pd.HDFStore('processed_data.h5') # 将 DataFrame 放进对象中,并设置 key 为 preprocessed_df data_store['preprocessed_df'] = df data_store.close() |
现在,你可以关闭计算机并休息一下。等你回来的时候,你处理的数据将在你需要时为你所用,而无需再次加工。以下是如何从HDF5文件访问数据,并保留数据类型:
# 获取数据储存对象 data_store = pd.HDFStore('processed_data.h5') # 通过key获取数据 preprocessed_df = data_store['preprocessed_df'] data_store.close() |
数据存储可以容纳多个表,每个表的名称作为键。
关于在Pandas中使用HDFStore的注意事项:您需要安装PyTables> = 3.0.0,因此在安装Pandas之后,请确保更新PyTables,如下所示:
| pip install --upgrade tables |
结论
如果你觉得你的Pandas项目不够快速,灵活,简单和直观,请考虑重新考虑你使用该库的方式。
这里探讨的示例相当简单,但说明了Pandas功能的正确应用如何能够大大改进运行时和速度的代码可读性。以下是一些经验,可以在下次使用Pandas中的大型数据集时应用这些经验法则:
尝试尽可能使用矢量化操作,而不是在df 中解决for x的问题。如果你的代码是许多for循环,那么它可能更适合使用本机Python数据结构,因为Pandas会带来很多开销。
如果你有更复杂的操作,其中矢量化根本不可能或太难以有效地解决,请使用.apply方法。
如果必须循环遍历数组(确实发生了这种情况),请使用.iterrows()或.itertuples()来提高速度和语法。
Pandas有很多可选性,几乎总有几种方法可以从A到B。请注意这一点,比较不同方法的执行方式,并选择在项目环境中效果最佳的路线。
一旦建立了数据清理脚本,就可以通过使用HDFStore存储中间结果来避免重新处理。
将NumPy集成到Pandas操作中通常可以提高速度并简化语法。
上文内容不用于商业目的,如涉及知识产权问题,请权利人联系博为峰小编(021-64471599-8017),我们将立即处理。












